Häufig gestellte Fragen
1. Fragen zu Demo, Bezahlung und Kauf
1.1. Wie lade ich Ergebnisse in der Demo-Version herunter?
In der Demo-Version stehen die Ergebnisse nicht zum Download zur Verfügung. Wir stellen sie auf Ihre Anfrage hin bereit. Senden Sie uns Ihre Anfragen und teilen Sie uns mit, welcher Scraper Sie interessiert, und wir senden Ihnen die Ergebnisse zu (im Rahmen der Demo ist deren Anzahl begrenzt).
1.2. Muss ich nach dem Kauf von A-Parser für etwas extra bezahlen?
Nein. Weitere Details: Lizenzen und Ergänzungen, Kaufseite.
1.3. Wo und wie kann ich Proxys bezahlen?
Beim Kauf einer Lizenz werden Ihnen Bonus-Proxys zur Verfügung gestellt.
Lite - 20 Threads für 2 Wochen, Pro und Enterprise - 50 Threads für einen Monat.
Weitere Threads kaufen oder verlängern können Sie im Mitgliederbereich auf dem Tab Shop, Unterabschnitt Proxy.
1.4. Könnten Sie mir eine Aufgabe gegen Bezahlung einrichten?
Technischer Support zu Fragen bezüglich der Arbeit von A-Parser wird kostenlos angeboten. Bezüglich kostenpflichtiger Hilfe bei der Erstellung von Aufgaben können Sie sich hierhin wenden: Kostenpflichtige Leistungen zur Erstellung von Aufgaben, Hilfe bei der Einrichtung und Schulung zur Arbeit mit A-Parser.
1.5. Kann ich den Scraper über die Privat24 Bank oder über KIWI bezahlen?
Die Liste der Zahlungssysteme, mit denen wir zusammenarbeiten, ist hier aufgeführt: A-Parser kaufen.
1.6. Wenn ich nur die Anzahl der indexierten Seiten bei Yandex extrahieren möchte, welche Version sollte ich kaufen?
Für solche Zwecke reicht die Lite-Version aus, aber Pro ist praktischer und flexibler in der Arbeit.
1.7. Wo sehe ich Informationen zu meiner Lizenz?
1.8. Ist es möglich, gekaufte Proxys von mehreren IPs aus zu nutzen?
Nein.
2. Fragen zu Installation, Start und Updates
2.1. Ich klicke auf den Download-Button - aber das Archiv wird nicht heruntergeladen. Was tun?
Überprüfen Sie, ob Sie freien Speicherplatz auf der Festplatte haben, und deaktivieren Sie den Virenschutz. Folgen Sie der Installationsanleitung. Lesen Sie auch Erste Schritte.
2.2. Ich habe die Enterprise-Version gekauft, aber es wird weiterhin PRO installiert. Was tun?
Löschen Sie die vorherige Version. Überprüfen Sie im Members Area, ob Ihre IP-Adresse korrekt eingetragen ist. Klicken Sie vor dem Herunterladen auf die Schaltfläche Update (Aktualisieren). Laden Sie eine neuere Version herunter. Weitere Details in der Installationsanleitung.
2.3. Ich habe das Programm installiert, aber es startet nicht. Was tun?
Überprüfen Sie die laufenden Anwendungen, deaktivieren Sie den Virenschutz und prüfen Sie den verfügbaren freien Arbeitsspeicher. Überprüfen Sie auch im Mitgliederbereich, ob Ihre IP-Adresse korrekt eingetragen ist. Weitere Details: Installationsanleitung.
2.4. Was tun, wenn ich eine dynamische IP-Adresse habe?
Kein Problem, A-Parser unterstützt die Arbeit mit dynamischen IP-Adressen. Jedes Mal, wenn sie sich ändert, müssen Sie diese einfach im Members Area eintragen. Um diese Manipulationen zu vermeiden, wird empfohlen, eine statische IP-Adresse zu verwenden.
2.5. Was sind die optimalen Server- oder Computerparameter für die Installation des Scrapers?
Alle Systemanforderungen können Sie hier einsehen: Systemanforderungen.
2.6. Ich habe eine Aufgabe gestartet. Der Scraper ist abgestürzt und startet nicht mehr. Was tun?
Sie müssen den Server stoppen, prüfen, ob der Prozess noch im Speicher hängt, und versuchen, ihn erneut zu starten. Sie können auch versuchen, A-Parser mit dem Stoppen aller Aufgaben zu starten. Dazu müssen Sie ihn mit dem Parameter -stoptasks starten. Details zum Start mit Parameter.
2.7. Welches Passwort muss beim Öffnen der Adresse 127.0.0.1:9091 eingegeben werden?
Wenn dies der erste Start ist, ist das Passwort leer. Wenn nicht der erste - dann das, welches Sie festgelegt haben. Wenn Sie das Passwort vergessen haben - Passwort zurücksetzen.
2.8. Im Mitgliederbereich gebe ich meine IP ein, aber sie ändert sich nicht im Feld Ihre aktuelle IP. Warum?
Das Feld Your current IP (Ihre aktuelle IP) zeigt die IP an, die bei Ihnen gerade gültig ist, und sie sollte sich nicht ändern. Diese müssen Sie in das Feld IP 1 eintragen.
2.9. Kann ich zwei Kopien gleichzeitig ausführen?
Zwei Kopien auf einem Rechner können nur gestartet werden, wenn ihnen in der Konfigurationsdatei unterschiedliche Ports zugewiesen wurden.
Zwei A-Parser gleichzeitig auf verschiedenen Rechnern zu starten ist nur möglich, wenn Sie eine zusätzliche IP im Mitgliederbereich erworben haben.
2.10. Ist der Scraper an die Hardware gebunden?
Nein. Zur Lizenzkontrolle wird Ihre IP verwendet.
2.11. Frage zum Update - nur die .exe aktualisieren? Wofür sind config/config.db und files/Rank-CMS/apps.json?
Sofern nicht anders angegeben, aktualisieren Sie nur .exe. Die erste Datei dient zum Speichern der A-Parser, und die zweite ist die Datenbank zur Bestimmung des CMS und für den eigentlichen Betrieb des Parsers ![]() Rank::CMS.
Rank::CMS.
2.12. Ich habe Win Server 2008 Web Edition - der Scraper startet nicht...
Auf dieser Betriebssystemversion wird A-Parser nicht funktionieren. Die einzige Option ist ein Wechsel des Betriebssystems.
2.13. Ich habe einen 4-Kern-Prozessor. Warum nutzt A-Parser nur einen Kern?
A-Parser nutzt 2 bis 4 Kerne, zusätzliche Kerne werden nur bei der Filterung, im Ergebnis-Builder und bei Parse custom result verwendet.
2.14. Bei mir tritt ein Segmentierungsfehler auf (segmentation failed, segmentation error). Was tun?
Höchstwahrscheinlich hat sich Ihre IP geändert. Überprüfen Sie dies im Mitgliederbereich.
2.15. Ich habe Linux. A-Parser ist gestartet, öffnet sich aber nicht im Browser. Wie lösen?
Überprüfen Sie die Firewall - höchstwahrscheinlich blockiert sie den Zugriff.
2.16. Ich habe Windows 7. A-Parser ist gestartet, öffnet sich aber nicht im Browser und im Task-Manager gibt es keinen Node.js Prozess. Wie lösen?
Sie müssen die Windows-Updates überprüfen und die neuesten verfügbaren installieren. Insbesondere wird das Windows 7 SP1 Update benötigt.
2.17. A-Parser startet nicht und in aparser.log steht der Fehler FATAL: padding_depad failed: Invalid argument provided. at ./Crypt/Mode/CBC.pm line 20.
Höchstwahrscheinlich tritt ein Problem mit einer Aufgabe auf (Ordner /config/tasks/), infolge eines Festplattenfehlers (z.B. wenn der PC ohne ordnungsgemäßes Herunterfahren ausgeschaltet wurde). Genaueres erfahren Sie, wenn Sie A-Parser mit dem Flag -morelogs starten.
Lösung: Start von A-Parser mit dem Parameter -stoptasks. Wenn das nicht hilft, leeren Sie den gesamten Ordner /config/tasks/. Wenn das Problem danach immer noch besteht, installieren Sie den Parser neu in ein neues Verzeichnis und übernehmen Sie die Konfiguration vom alten (falls diese nicht beschädigt ist).
3. Fragen zur Konfiguration von A-Parser und anderen Einstellungen
3.1. Wie richte ich den Proxychecker ein?
Eine detaillierte Anleitung finden Sie hier: Proxy-Einstellungen.
3.2. Keine aktiven Proxys - warum?
Überprüfen Sie Ihre Internetverbindung sowie die Korrektheit der Proxychecker-Einstellungen. Wenn alles richtig gemacht wurde, bedeutet dies, dass Ihre Proxy-Liste derzeit keine funktionierenden Server enthält. Lösung für dieses Problem: Entweder andere Proxys verwenden oder es später erneut versuchen. Wenn Sie unsere Proxys verwenden, überprüfen Sie die IP-Adresse im Mitgliederbereich im Bereich Proxies (Proxy). Es ist auch möglich, dass Ihr Provider den Zugriff auf andere DNS blockiert; versuchen Sie die hier beschriebenen Schritte: http://a-parser.com/threads/1240/#post-3582
3.3. Wie verbinde ich Antigate?
Eine detaillierte Anleitung zur Einrichtung von Antigate finden Sie hier.
3.4. Ich habe Parameter in den Scraper-Einstellungen geändert, aber sie wurden nicht übernommen. Warum?
Das Standard-Preset (default) kann nicht geändert werden. Wenn Änderungen vorgenommen wurden, müssen Sie auf Save as New Preset (Als neues Preset speichern) klicken und dieses danach in Ihrer Aufgabe verwenden.
3.5. Kann man die Einstellungen einer laufenden Aufgabe ändern?
Ja, aber nicht alle. In einer laufenden Aufgabe können Sie auf Pause klicken und dort im Dropdown-Menü Edit (Bearbeiten) wählen.
3.6. Wie importiere ich ein Preset?
Klicken Sie auf die Schaltfläche neben dem Aufgabenauswahlfeld im Task-Editor. Details hier.
3.7. Wie stelle ich den Scraper so ein, dass er keine Proxys verwendet?
In den Einstellungen des entsprechenden Scrapers das Häkchen bei Use proxy entfernen.
3.8. Ich habe keine Schaltfläche 'Überschreibung hinzufügen / Override option'!
Diese Option kann direkt im Task-Editor hinzugefügt werden. Scraper-Optionen.
3.9. Wie überschreibe ich dieselbe Ergebnisdatei?
Beim Erstellen der Aufgabe die Option Overwrite file (Datei überschreiben) aktivieren.
3.10. Wo ändere ich das Passwort für den Scraper?
3.11. Ich habe 6 Millionen Keys zum Scraping eingestellt und angegeben, dass alle Domains einzigartig sein sollen. Wie erreiche ich, dass bei neuen 6 Millionen Keys nur einzigartige Domains gespeichert werden, die sich nicht mit dem vorherigen Scraping überschneiden?
Sie müssen die Option Keep unique (Unikalisierung speichern) beim Erstellen der ersten Aufgabe nutzen und die gespeicherte Datenbank in der zweiten angeben. Details in den zusätzlichen Optionen des Task-Editors.
3.12. Wie umgehe ich das Limit von 1000 Ergebnissen bei Google?
Nutzen Sie die Option Alle Ergebnisse extrahieren / Parse all results.
3.13. Wie umgehe ich das Limit von 1024 Threads unter Linux?
3.14. Was ist das Thread-Limit unter Windows?
Bis zu 10.000 Threads.
3.15. Wie mache ich Abfragen einzigartig?
Verwenden Sie die Option Unique queries (Einzigartige Abfragen) im Block Queries (Abfragen) im Task-Editor.
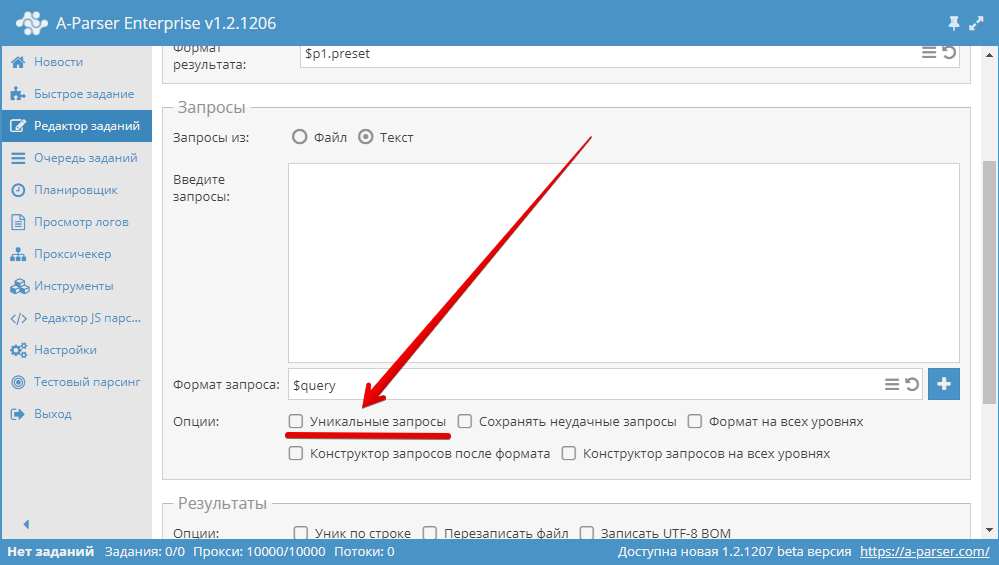
3.16. Wie deaktiviere ich die Proxy-Prüfung?
In Einstellungen - Proxychecker-Einstellungen den gewünschten Proxychecker auswählen und das Häkchen bei No check proxies (Proxys nicht prüfen) setzen. Speichern und das gespeicherte Preset auswählen.
3.17. Was ist Proxy ban time? Kann ich dort 0 eintragen?
Die Zeit der Proxy-Sperre in Sekunden. Ja, das können Sie.
3.18. Was ist der Unterschied zwischen Exact Domain und Top Level Domain im Parser  SE::Google::Position
SE::Google::Position
Exact Domain ist eine strikte Übereinstimmung, d.h. wenn in den Ergebnissen www.domain.com steht und wir nach domain.com suchen, gibt es keine Übereinstimmung. Top Level Domain vergleicht die gesamte Top-Level-Domain, d.h. hier gäbe es eine Übereinstimmung.
3.19. Wenn ich ein Test-Scraping starte, funktioniert alles, beim normalen Scraping erhalte ich den Fehler 'Some error'.
Höchstwahrscheinlich liegt ein Problem mit dem DNS vor. Versuchen Sie, diese Anleitung zur DNS-Konfiguration zu befolgen.
3.20. Wo wird das Ergebnisformat festgelegt?
Verwenden Sie bei der Ergebnisformatierung \n. Beispiel:
3.21. In  SE::Google fehlt die niederländische Sprache, obwohl sie in den Google-Einstellungen vorhanden ist. Warum?
SE::Google fehlt die niederländische Sprache, obwohl sie in den Google-Einstellungen vorhanden ist. Warum?
Niederländisch ist Dutch, es steht auf der Liste. Details in der Verbesserung zum Hinzufügen der niederländischen Sprache.
4. Fragen zur Datenerfassung und Fehlern während der Datenerfassung
4.1. Was sind Threads?
Alle modernen Prozessoren können Aufgaben in mehreren Threads ausführen, was deren Ausführungsgeschwindigkeit erheblich erhöht. Zum Vergleich kann man einen gewöhnlichen Bus heranziehen, der pro Zeiteinheit eine bestimmte Anzahl von Personen befördert – das wäre eine normale Single-Thread-Verarbeitung, und einen Doppeldeckerbus, der in der gleichen Zeit doppelt so viele Personen befördert – das wäre eine Multi-Thread-Verarbeitung. A-Parser kann gleichzeitig bis zu 10000 Threads verarbeiten.
4.2. Die Aufgabe startet nicht - es steht 'Some Error' - warum?
Überprüfen Sie die IP-Adresse im Mitgliederbereich.
4.3. Alle Abfragen schlagen fehl, was tun?
Höchstwahrscheinlich wurde die Aufgabe falsch erstellt oder es wird ein falsches Abfrageformat verwendet. Prüfen Sie auch, ob aktive Proxys vorhanden sind. Sie können auch versuchen, die Option Request retries zu erhöhen (Details hier: fehlgeschlagene Anfragen).
4.4. Wie viele Accounts müssen registriert werden, um 1.000.000 Keywords mit  SE::Yandex::Wordstat zu extrahieren?
SE::Yandex::Wordstat zu extrahieren?
Es lässt sich nicht genau sagen, wie viele Accounts benötigt werden, da ein Account nach einer unbekannten Anzahl von Anfragen unbrauchbar werden kann. Sie können jedoch jederzeit neue Accounts mit dem Parser  SE::Yandex::Register registrieren oder einfach bestehende Accounts zur Datei files/SE-Yandex/accounts.txt hinzufügen.
SE::Yandex::Register registrieren oder einfach bestehende Accounts zur Datei files/SE-Yandex/accounts.txt hinzufügen.
4.5. Die Aufgabe startet nicht, es steht 'Error: Lock 100 threads failed(20 of limit 100 used)'. Was tun?
Es ist notwendig, die maximal verfügbare Anzahl an Threads in den Parser-Einstellungen zu erhöhen oder in den Aufgabeneinstellungen zu verringern. Details unter Einstellungen.
4.6. Kann man 2 Aufgaben gleichzeitig starten?
Ja, A-Parser unterstützt die gleichzeitige Ausführung mehrerer Aufgaben. Die Anzahl der gleichzeitig laufenden Aufgaben wird unter Einstellungen - Allgemeine Einstellungen: Maximum aktive Aufgaben geregelt.
4.7. Wo liegt die Ergebnisdatei?
Auf dem Tab Tasks Queue (Tasks queue) (Aufgabenwarteschlange) können Sie nach Abschluss jeder Aufgabe die Ergebnisse herunterladen. Physisch befinden sie sich im Ordner results.
4.8. Kann man die Ergebnisdatei herunterladen, wenn die Datenerfassung noch nicht beendet ist?
Nein, solange die Datenerfassung nicht abgeschlossen ist, können die Ergebnisse nicht heruntergeladen werden. Sie können jedoch bei gestoppter oder pausierter Aufgabe aus dem Ordner aparser/results kopiert werden.
4.9. Kann man mit Ihrem Scraper 1.000.000 Links zu einer Abfrage extrahieren?
Ja, unter Verwendung der Option Alle Ergebnisse extrahieren / Parse all results.
4.10. Kann man  Rank::CMS,
Rank::CMS,  Net::Whois ohne Proxy nutzen?
Net::Whois ohne Proxy nutzen?
Net::Whois - nicht ratsam.4.11. Wie extrahiere ich Links von Google?
Es muss SE::Google verwendet werden.
4.12. Kann der Scraper Links folgen?
Ja, das kann der Parser  HTML::LinkExtractor unter Verwendung der Option Bis zur Ebene extrahieren / Parse to level tun.
HTML::LinkExtractor unter Verwendung der Option Bis zur Ebene extrahieren / Parse to level tun.
4.13. Google wird sehr langsam gescrapt, was tun?
Zuerst sollten Sie die Aufgaben-Logs prüfen, möglicherweise sind alle Anfragen fehlgeschlagen. Wenn dies der Fall ist, müssen Sie die Ursache finden, warum die Anfragen fehlgeschlagen sind, und diese beheben. Bei der Datenerfassung mit SE::Google hängen fehlgeschlagene Versuche in den Aufgaben-Logs oft damit zusammen, dass Google Captchas anzeigt, was normal ist. Sie können Antigate verbinden, um Captchas zu umgehen, damit der Parser die Versuche nicht unnötig wiederholt.
Außerdem gibt es einen Artikel, der die Faktoren beschreibt, die die Geschwindigkeit der Datenerfassung beeinflussen, und wie sie wirken: Geschwindigkeit und Funktionsprinzip von Scrapern.
4.14. Kann man mit Ihrem Scraper Links extrahieren, deren Text nur auf Japanisch ist?
Ja, dazu müssen Sie in den Parser-Einstellungen die gewünschte Sprache festlegen sowie japanische Keywords verwenden.
4.15. Kann man mit Ihrem Scraper Links nur in der Domainzone .de oder .ru extrahieren?
Ja. Dazu müssen Sie einen Filter verwenden.
4.16. Wie erhalte ich jedes Ergebnis in der Datei in einer neuen Zeile?
Verwenden Sie bei der Ergebnisformatierung \n. Beispiel:
$serp.format('$link\n')
4.17. Wie extrahiere ich die Top 10 Websites von Google?
Hier ist das Preset:
eyJwcmVzZXQiOiJUT1AxMCIsInZhbHVlIjp7InByZXNldCI6IlRPUDEwIiwicGFy
c2VycyI6W1siU0U6Okdvb2dsZSIsImRlZmF1bHQiLHsidHlwZSI6Im92ZXJyaWRl
IiwiaWQiOiJwYWdlY291bnQiLCJ2YWx1ZSI6MX0seyJ0eXBlIjoib3ZlcnJpZGUi
LCJpZCI6ImxpbmtzcGVycGFnZSIsInZhbHVlIjoxMH0seyJ0eXBlIjoib3ZlcnJp
ZGUiLCJpZCI6InVzZXByb3h5IiwidmFsdWUiOmZhbHNlfV1dLCJyZXN1bHRzRm9y
bWF0IjoiJHAxLnByZXNldCIsInJlc3VsdHNTYXZlVG8iOiJmaWxlIiwicmVzdWx0
c0ZpbGVOYW1lIjoiJGRhdGVmaWxlLmZvcm1hdCgpLnR4dCIsImFkZGl0aW9uYWxG
b3JtYXRzIjpbXSwicmVzdWx0c1VuaXF1ZSI6Im5vIiwicXVlcnlGb3JtYXQiOlsi
JHF1ZXJ5Il0sInVuaXF1ZVF1ZXJpZXMiOmZhbHNlLCJzYXZlRmFpbGVkUXVlcmll
cyI6ZmFsc2UsIml0ZXJhdG9yT3B0aW9ucyI6eyJvbkFsbExldmVscyI6ZmFsc2Us
InF1ZXJ5QnVpbGRlcnNBZnRlckl0ZXJhdG9yIjpmYWxzZX0sInJlc3VsdHNPcHRp
b25zIjp7Im92ZXJ3cml0ZSI6ZmFsc2V9LCJkb0xvZyI6Im5vIiwia2VlcFVuaXF1
ZSI6Ik5vIiwibW9yZU9wdGlvbnMiOmZhbHNlLCJyZXN1bHRzUHJlcGVuZCI6IiIs
InJlc3VsdHNBcHBlbmQiOiIiLCJxdWVyeUJ1aWxkZXJzIjpbXSwicmVzdWx0c0J1
aWxkZXJzIjpbXSwiY29uZmlnT3ZlcnJpZGVzIjpbXX19
4.18. Ich füge eine Aufgabe hinzu, gehe zum Tab Aufgabenwarteschlange - aber sie ist nicht da! Warum?
Entweder wurde beim Erstellen der Aufgabe ein Fehler gemacht, oder sie wurde bereits ausgeführt und in den Status Completed (Abgeschlossen) verschoben.
4.19. Es steht dort, dass die Datei nicht in utf-8 ist, aber ich habe sie nicht geändert, sie ist bereits utf-8. Was tun?
Überprüfen Sie es noch einmal. Versuchen Sie auch, die Kodierung zu ändern, zum Beispiel mit Notepad++.
4.20. In der Ergebnisdatei ist alles in einer Zeile, obwohl ich in der Aufgabe einen Zeilenumbruch eingestellt habe - warum?
In den zusätzlichen Einstellungen von A-Parser muss der Zeilenumbruch CRLF (Windows) verwendet werden.
Wenn Sie jedoch bereits ohne diese Option extrahiert haben, verwenden Sie zum Betrachten einen fortgeschritteneren Viewer, wie zum Beispiel Notepad++.
4.21. Wie viel Zeit wird benötigt, um das Suchvolumen von 1.000 Abfragen bei Yandex zu prüfen?
Dieser Wert hängt stark von den Aufgabenparametern, den Servereigenschaften, der Proxy-Qualität usw. ab, daher ist eine eindeutige Antwort nicht möglich.
4.22. Wie richte ich den Scraper so ein, dass das Ergebnis 'Abfrage-Link' ist?
Ergebnisformat:
$p1.serp.format('$query: $link\n')
Das Ergebnis wird sein:
Abfrage: Link 1
Abfrage: Link 2
Abfrage: Link 3
4.23. Wie scrappe ich fehlgeschlagene Abfragen erneut und wo werden sie gespeichert?
Damit fehlgeschlagene Anfragen gespeichert werden, sollte die entsprechende Option im Block Queries (Anfragen) im Task-Editor ausgewählt werden. Fehlgeschlagene Anfragen werden in queries\failed gespeichert. Sie müssen eine neue Aufgabe erstellen und als Abfragedatei die Datei mit den fehlgeschlagenen Anfragen angeben.
4.24. Wie entferne ich HTML-Tags beim Scraping von Text?
Nutzen Sie die Option Remove HTML tags im Ergebnis-Builder.
4.25. Wie erreiche ich, dass nur Domains extrahiert werden?
Nutzen Sie die Option Extract Domain im Ergebnis-Builder.
4.26. Was ist die maximale Größe der Abfragedatei, die im Scraper verwendet werden kann?
Die Größen der Abfrage- und Ergebnisdateien sind nicht begrenzt und können Terabyte-Werte erreichen.
4.27. Warum gibt der Scraper 'Queries length limited to 8192 characters' aus, wenn ich Text in das Abfragefeld eingebe?
Dies geschieht, weil die Länge einer Abfrage auf 8192 Zeichen begrenzt ist. Um längere Abfragen zu verwenden, nutzen Sie Dateien als Abfragen.
4.28. Was bedeutet 'Wartende Threads - 3'?
Das bedeutet, dass nicht genügend Proxys vorhanden sind. Verringern Sie die Anzahl der Threads oder erhöhen Sie die Anzahl der Proxys.
4.29. Im Test-Scraping steht '596 SOCKS proxy error: Hello read error(Connection reset by peer) (0 KB)' und es wird nichts extrahiert, warum?
Dies deutet auf nicht funktionierende Proxys hin.
4.30. Was ist der Unterschied zwischen Ergebnissprache und Suchland im Google-Scraper?
Der Unterschied ist folgender: Das Suchland ist die Bindung der Ergebnisse an ein bestimmtes Land. Wenn Sie beispielsweise nach Fenster kaufen mit Bindung an ein bestimmtes Land suchen, haben Websites Priorität, die den Kauf von Fenstern genau in diesem Land anbieten. Die Ergebnissprache hingegen ist die Sprache, in der die Ergebnisse ausgegeben werden sollen.
4.31. Eine bestimmte Website wird bei mir nicht gescrapt. Woran kann das liegen?
Oft liegt das Problem darin, dass eine Blockierung aufgrund eines alten User-Agents auf der Serverseite erfolgt. Dies wird durch einen neuen User-Agent oder den folgenden Code im Parameter User agent gelöst:
[% tools.ua.random() %]
4.32. Der Scraper hängt sich auf oder stürzt ab. Im Log erscheint die Zeile 'syswrite: No space left on device'.
A-Parser hat nicht genügend Festplattenspeicher. Geben Sie mehr Speicherplatz frei.
4.33. Mein Scraper gibt plötzlich 'none' in den Ergebnissen aus (oder ein offensichtlich falsches Ergebnis).
4.34. Es erscheint ständig ein Fenster mit der Aufschrift 'Failed fetch news'.
4.35. Wie gebe ich die ersten n Ergebnisse der Suchergebnisse aus?
4.36. Wie verfolge ich eine Weiterleitungskette?
4.37. Wie prüfe ich die Indexierung eines Links beim Donor?
Für solche Zwecke gibt es einen separaten Parser:  Check::BackLink.
Details in der Diskussion.
Check::BackLink.
Details in der Diskussion.
4.38. Der Scraper stürzt unter Linux ab. Im Log steht dieser Eintrag: EV: error in callback (ignoring): syswrite() on closed filehandle at AnyEvent/Handle.pm line...
Höchstwahrscheinlich muss die Anzahl der Threads optimiert werden, wie in der Dokumentation: Linux-Tuning für eine höhere Anzahl von Threads beschrieben.
4.39. Wo kann ich alle möglichen Parameter für die Verwendung über die API einsehen?
Abrufen einer API-Anfrage im Interface.
Zudem kann eine vollständige Aufgabenkonfiguration in JSON generiert werden. Dazu muss der Aufgabencode genommen und aus base64 dekodiert werden.
4.40. Ich lade Bilder mit  Net::HTTP herunter, aber sie sind alle beschädigt. Was tun?
Net::HTTP herunter, aber sie sind alle beschädigt. Was tun?
1) Überprüfen Sie den Parameter Max body size - möglicherweise muss dieser erhöht werden. 2) Überprüfen Sie in den A-Parser das Format des Zeilenumbruchs: Zusätzliche Einstellungen - Zeilenumbruch.
Damit das Bild nicht beschädigt wird, muss das UNIX-Format verwendet werden.
4.41. Wie erhalte ich den Admin-Kontakt aus WHOIS?
Eine solche Aufgabe lässt sich leicht mit der Funktion Parse custom result und einem regulären Ausdruck lösen. Details in der Diskussion.
4.42. Regulärer Ausdruck zum Scraping von Telefonnummern
4.43. Bestimmung von Websites ohne mobile Version
4.44. Wie erfahre ich den Namen des NS-Servers?
4.45. Wie extrahiere ich Links zum Yandex-Cache?
4.46. Wie extrahiere ich Links zu allen Seiten einer Website?
4.47. Wie extrahiere ich den Title von einer Seite?
4.48. Wie extrahiere ich alle Websites in einer bestimmten Domainzone?
4.49. Wie sammle ich alle URLs mit Parametern?
4.50. Wie filtere ich Ergebnisse nach mehreren Kriterien und teile sie im Bericht danach auf?
4.51. Wie vereinfache ich die Filterkonstruktion?
4.52. Wie sortiere ich nach Dateien in Abhängigkeit vom Ergebnis?
4.53. Neues Ergebnisverzeichnis alle X Dateien erstellen
4.54. Erste Schritte bei der Arbeit mit WordStat
4.55. Sammlung von Textblöcken > 1000 Zeichen
4.56. Ausgabe einer bestimmten Textmenge von einer Seite
Dies wird ebenfalls mit Template Toolkit gelöst. Details in der Diskussion.
4.57. Prüfung von Konkurrenz und Vorkommen im Titel bei Google
4.58. Filterung nach Anzahl der Vorkommen der Abfrage in Anker und Snippet
4.59. Wie erhalte ich den Inhalt eines Artikels in einer einzigen Zeile?
4.60. Wie vergleiche ich zwei Datums-Strings?
4.61. Wie extrahiere ich hervorgehobene Wörter aus dem Snippet?
4.62. Beispiel einer Aufgabe unter Verwendung mehrerer Scraper
4.63. Wie mische ich Zeilen im Ergebnis und wie gebe ich eine zufällige Anzahl an Ergebnissen aus?
4.64. Wie signiere ich das Ergebnis mit MD5?
4.65. Wie wandle ich ein Datum vom Unix-Timestamp in eine String-Darstellung um?
4.66. Parse to level, wie extrahiere ich mit Begrenzung?
4.67. Der Scraper stürzt unter Linux beim Start einer Aufgabe ab. Im Log stehen diese Zeilen: Can't call method "if_list" on an undefined value at IO/Interface/Simple.pm...
In der Konsole muss folgender Befehl ausgeführt werden:
apt-get --reinstall --purge install netbase
4.68. Fehler Cannot init Parser: Error: Failed to launch the browser process! [0429/082706.472999:ERROR:zygote_host_impl_linux.cc(90)] Running as root without --no-sandbox is not supported...
A-Parser muss nicht als Root gestartet werden. Genauer gesagt: Vom Root-Benutzer aus muss ein neuer Benutzer ohne Root-Rechte erstellt werden (falls vorhanden, diesen einfach verwenden), diesem Benutzer muss dann erlaubt werden, mit dem A-Parser zu interagieren, danach muss man sich als neuer Benutzer einloggen und von dort aus starten.
Unter dem Benutzer root einen User erstellen, dies ist nach diesem Guide möglich.
Um dem erstellten Benutzer die Interaktion mit dem A-Parser zu erlauben, müssen dem Benutzer Rechte gegeben werden. Dazu loggen wir uns als Root-Benutzer ein und geben die Rechte mit dem Befehl:
chown -R user:user aparser
4.69. Fehler Cannot init Parser: Error: Failed to launch the browser process! [0429/102002.619437:FATAL:zygote_host_impl_linux.cc(117)] No usable sandbox! Update your kernel or see...
Unter dem Benutzer root den Befehl ausführen:
sysctl -w kernel.unprivileged_userns_clone=1
Ein Neustart von A-Parser ist nicht erforderlich.
Für CentOS 7 findet sich die Lösung in diesem Thema.
Unter dem root-Benutzer den Befehl ausführen:
echo "user.max_user_namespaces=15000" >> /etc/sysctl.conf
Dann sysctl mit dem Befehl neu starten:
sysctl -p
4.70. Fehler JavaScript execution error(): Error: Failed to launch the browser process! /aparser/dist/nodejs/node_modules/puppeteer/.local-chromium/linux-884014/chrome-linux/chrome: error while loading shared libraries: libatk-1.0.so.0: cannot open shared object file: No such file or directory...
Der Fehler tritt aufgrund fehlender Bibliotheken im Betriebssystem für den Betrieb von Chrome auf.
Die Liste der benötigten Bibliotheken für den Betrieb von Chrome finden Sie unter Chrome headless doesn't launch on UNIX.
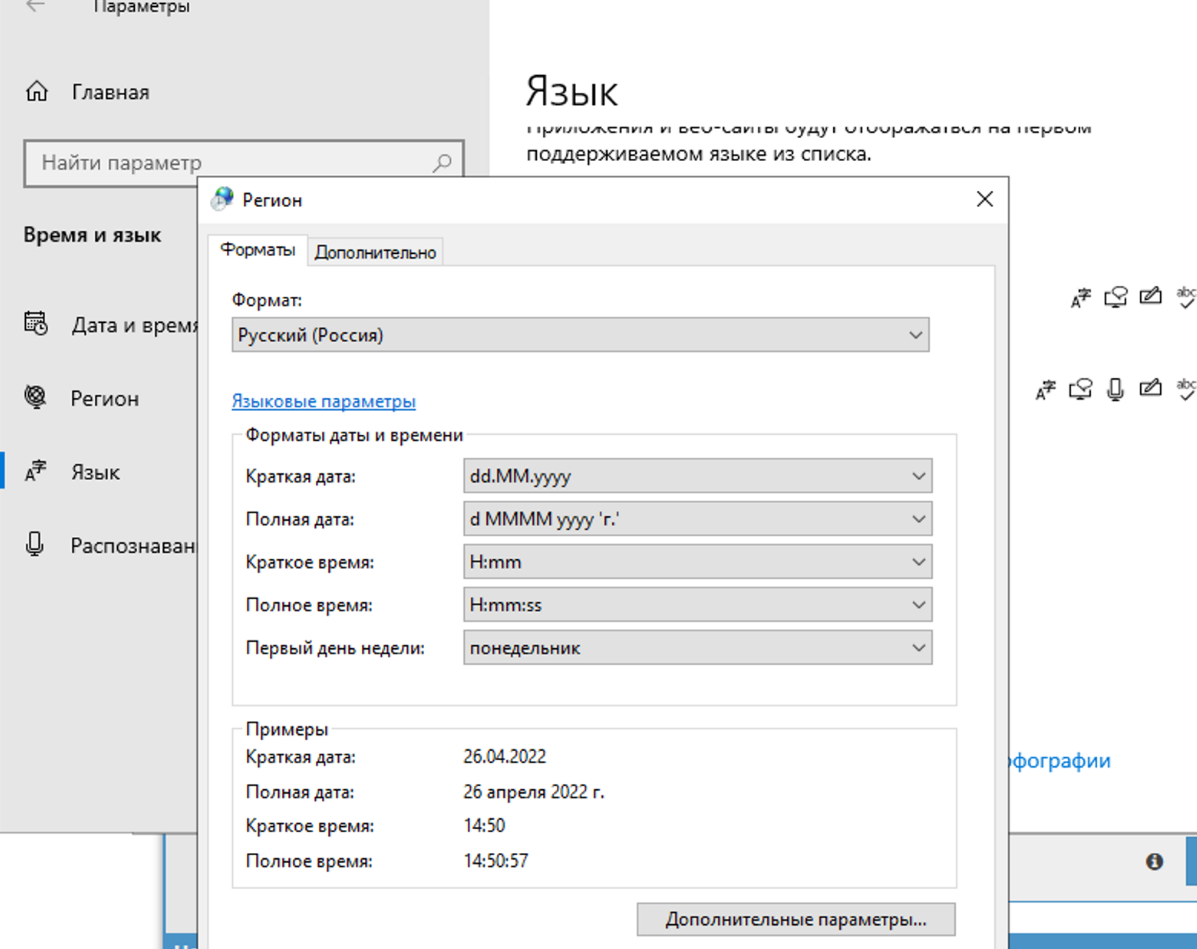
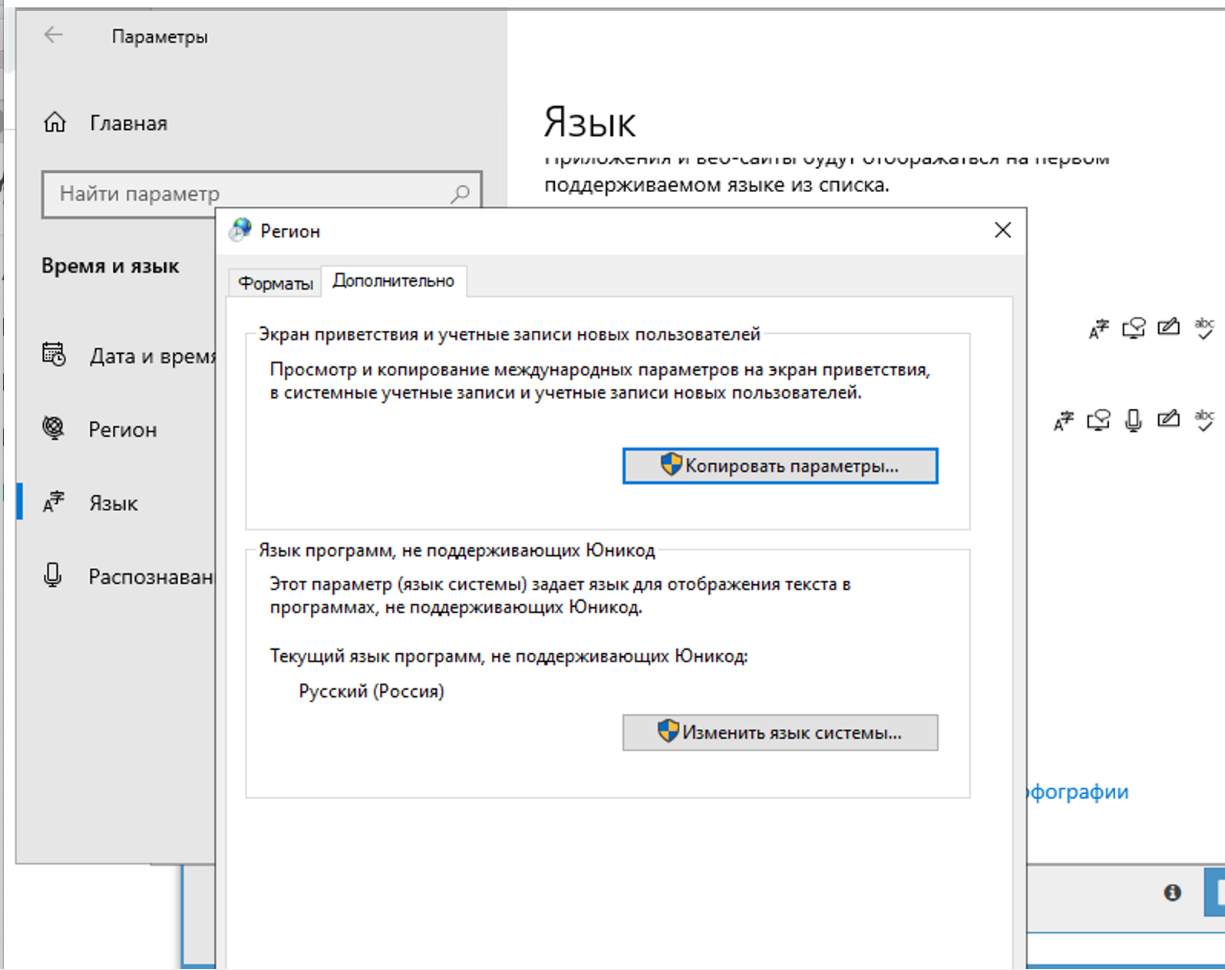
4.71. Warum wird das Captcha nicht gelöst? Im Log ist zu sehen, dass A-Parser von Xevil Fragezeichen anstelle der Captcha-Antwort erhalten hat
In den Regionaleinstellungen muss auf Russisch umgestellt werden.
Die Änderung sollte nur auf dem Tab 'Erweitert' vorgenommen werden. Auf das Lösen von Captchas hat dies keinen Einfluss, aber in Xrumer selbst wird es ein Problem mit der Kodierung geben, wenn es an beiden Stellen geändert wird.