Net::HTTP - Universeller Basis-Parser mit Unterstützung für mehrseitige Datenerfassung und CloudFlare-Umgehung
Übersicht über den Parser
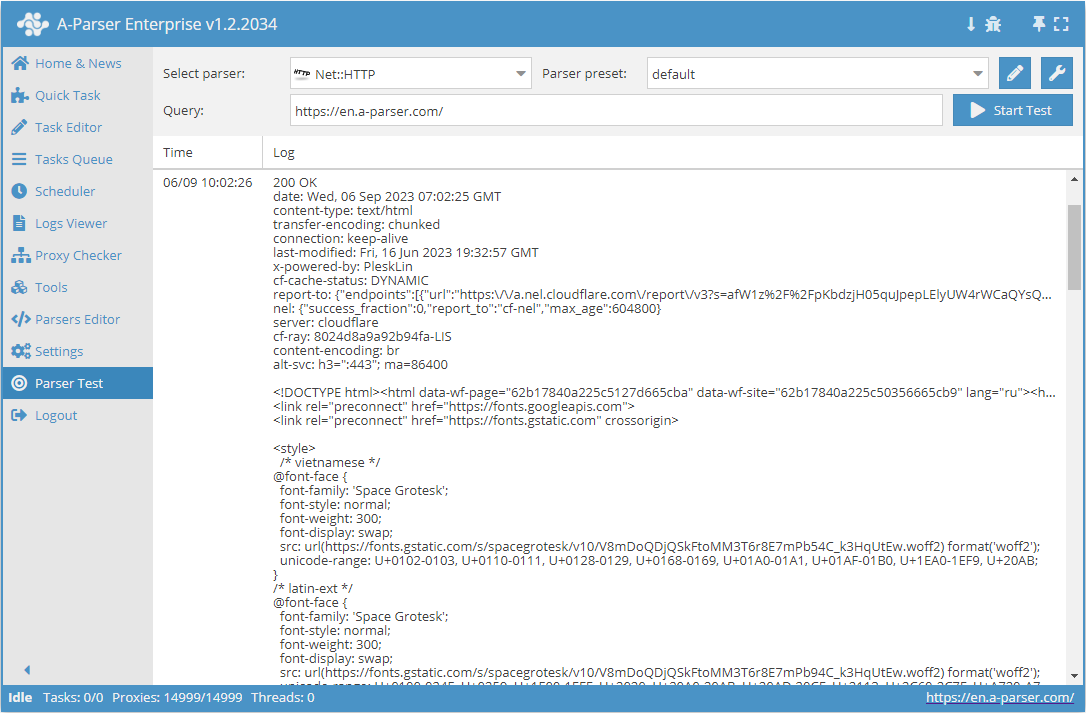
 Net::HTTP – ist ein universeller Parser, der die Lösung der meisten nicht standardmäßigen Aufgaben ermöglicht. Er kann als Basis für die Datenerfassung beliebiger Inhalte von beliebigen Websites verwendet werden. Ermöglicht das Herunterladen des Seitencodes über einen Link, unterstützt mehrseitige Datenerfassung (Navigation durch Seiten), automatische Arbeit mit Proxys und ermöglicht die Überprüfung einer erfolgreichen Antwort anhand des Codes oder des Seiteninhalts.
Net::HTTP – ist ein universeller Parser, der die Lösung der meisten nicht standardmäßigen Aufgaben ermöglicht. Er kann als Basis für die Datenerfassung beliebiger Inhalte von beliebigen Websites verwendet werden. Ermöglicht das Herunterladen des Seitencodes über einen Link, unterstützt mehrseitige Datenerfassung (Navigation durch Seiten), automatische Arbeit mit Proxys und ermöglicht die Überprüfung einer erfolgreichen Antwort anhand des Codes oder des Seiteninhalts.Anwendungsbeispiele für den Parser
🔗 REG.RU Domain-Auktion
Datenerfassung der Auktion freiwerdender Domains mit Filtermöglichkeit
🔗 SSL-Zertifikatsdaten
Datenerfassung von SSL-Zertifikatsdaten für Domains von der Website leaderssl.ru
🔗 Datenerfassung der Ressource Booking.com
Abrufen von Suchergebnissen für Wohnungen und Hotels auf der Website
🔗 Erfassung von Produktmerkmalen
Beispiel für die Datenerfassung einer unbekannten Anzahl von Produktmerkmalen
🔗 Datenerfassung der Filmdatenbank von IMDB
Ruft Daten zu jedem Film ab und schreibt sie in das Ergebnis
🔗 Überprüfung auf HTTPS-Vorhandensein
Preset prüft das Vorhandensein von HTTPS auf der Website
Gesammelte Daten
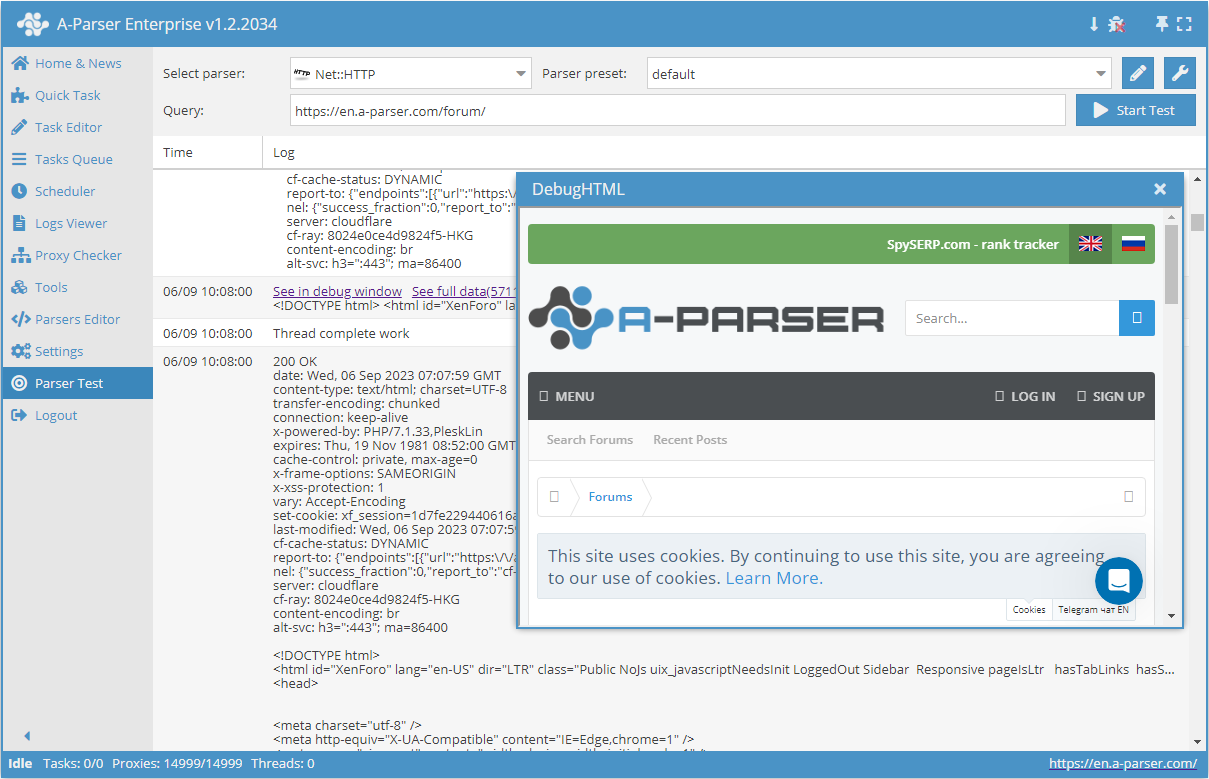
- Inhalt
- HTTP-Statuscode
- Beschreibung der Serverantwort
- Header der Serverantwort
- Beim Request verwendete Proxys
- Array mit allen gesammelten Seiten (wird bei Verwendung der Option Use Pages genutzt)
Funktionen
- Mehrseitige Datenerfassung (Navigation durch Seiten)
- Automatische Arbeit mit Proxys
- Überprüfung der erfolgreichen Antwort nach Code oder Seiteninhalt
- Unterstützt Kompressionen wie gzip/deflate/brotli
- Erkennung und Umwandlung von Website-Kodierungen in UTF-8
- Umgehung des CloudFlare-Schutzes
- Auswahl der Engine (HTTP oder Chrome)
- Option Check content – führt einen angegebenen regulären Ausdruck auf der abgerufenen Seite aus. Wenn der Ausdruck nicht passt, wird die Seite mit einem anderen Proxy erneut geladen.
- Option Use Pages – ermöglicht das Durchlaufen einer angegebenen Anzahl von Seiten mit einem bestimmten Schritt. Die Variable
$pagenumenthält die aktuelle Seitennummer beim Durchlauf. - Option Check next page – hier muss ein regulärer Ausdruck angegeben werden, der den Link zur nächsten Seite extrahiert (normalerweise die "Weiter"-Schaltfläche), falls vorhanden. Der Übergang zwischen den Seiten erfolgt innerhalb des angegebenen Limits (0 - unbegrenzt).
- Option Page as new query – der Übergang zur nächsten Seite erfolgt in einem neuen Request. Ermöglicht die Aufhebung der Beschränkung für die Anzahl der zu durchlaufenden Seiten.
Anwendungsfälle
- Herunterladen von Inhalten
- Herunterladen von Bildern
- Überprüfung des HTTP-Statuscodes
- Überprüfung auf HTTPS-Verfügbarkeit
- Überprüfung auf Weiterleitungen
- Ausgabe einer Liste von Redirect-URLs
- Ermittlung der Seitengröße
- Sammeln von Meta-Tags
- Extrahieren von Daten aus dem Quellcode der Seite und/oder den Headern
Anfragen
Als Anfragen müssen Links zu Seiten angegeben werden, zum Beispiel:
http://lenta.ru/
http://a-parser.com/pages/reviews/
Beispiele für die Ergebnisausgabe
A-Parser unterstützt eine flexible Formatierung der Ergebnisse dank der integrierten Template-Engine Template Toolkit, was die Ausgabe der Ergebnisse in beliebiger Form sowie strukturiert, zum Beispiel als CSV oder JSON, ermöglicht.
Inhaltsausgabe
Ergebnisformat:
$data
Beispielergebnis:
<!DOCTYPE html><html id="XenForo" lang="ru-RU" dir="LTR" class="Public NoJs uix_javascriptNeedsInit LoggedOut Sidebar Responsive pageIsLtr hasTabLinks hasSearch is-sidebarOpen hasRightSidebar is-setWidth navStyle_0 pageStyle_0 hasFlexbox" xmlns:fb="http://www.facebook.com/2008/fbml">
<head>
<!-- Google Tag Manager -->
<!-- End Google Tag Manager -->
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<base href="https://a-parser.com/" />
<title>A-Parser - parser für SEO-Profis</title>
<noscript><style>.JsOnly, .jsOnly { display: none !important; }</style></noscript>
<link rel="stylesheet" href="css.php?css=xenforo,form,public,parser_icons&style=9&dir=LTR&d=1612857138" />
<link rel="stylesheet" href="css.php?css=facebook,google,login_bar,moderator_bar,nat_public_css,node_category,node_forum,node_list,notices,panel_scroller,resource_list_mini,sidebar_share_page,thread_list_simple,twitter,uix_extendedFooter&style=9&dir=LTR&d=1612857138" />
<link rel="stylesheet" href="css.php?css=uix,uix_style&style=9&dir=LTR&d=1612857138" />
HTTP-Statuscode
Ergebnisformat:
$code
Beispielergebnis:
200
Das Ergebnisformat [% response.Redirects.0.Status || code %] ermöglicht die Ausgabe des Status 301, wenn im Request Weiterleitungen vorhanden sind.
Abrufen von Request-Daten
Die Variable $response hilft dabei, Informationen über den Request und die Serverantwort zu erhalten.
Ergebnisformat:
$response.json\n
Beispielergebnis:
{
"Time": 3.414,
"connection": "keep-alive",
"Decode": "Decode from utf-8(meta charset)",
"cache-control": "max-age=3600,public",
"last-modified": "Tue, 18 May 2021 12:42:56 GMT",
"transfer-encoding": "chunked",
"date": "Thu, 27 May 2021 14:18:42 GMT",
"Status": 200,
"content-encoding": "gzip",
"Body-Length-Decoded": 1507378,
"Reason": "OK",
"Proxy": "http://51.255.55.144:25302",
"content-type": "text/html",
"Redirects": [],
"server": "nginx",
"Request-Raw": "GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n",
"URI": "https://a-parser.com/",
"HTTPVersion": "1.1",
"Body-Length": 299312,
"Decode-Mode": "auto-html",
"etag": "W/\"60a3b650-170032\"",
"Decode-Time": 0.003,
"IP": "remote",
"expires": "Thu, 27 May 2021 15:18:42 GMT"
}
Abrufen von Redirects
Anfrage:
https://google.it
Ergebnisformat:
$response.Redirects.0.URI -> $response.URI
Beispielergebnis:
https://google.it/ -> https://www.google.it/
JSON mit Redirects
Ergebnisformat:
$response.Redirects.json
Beispielergebnis:
[{"x-powered-by":"PleskLin","connection":"keep-alive","URI":"http://a-parser.com/","location":"https://a-parser.com/","date":"Thu, 18 Feb 2021 09:16:36 GMT","HTTPVersion":"1.1","Status":301,"content-length":"162","Reason":"Moved Permanently","Proxy":"socks5://51.255.55.144:29683","content-type":"text/html","IP":"remote","server":"nginx","Request-Raw":"GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n"}]
Ausgabe des Server-Antwortstatus
Ergebnisformat:
$reason
Beispielergebnis:
OK
Antwortzeit des Servers
Ergebnisformat:
$response.Time
Beispielergebnis:
1.457
Ermittlung der Seitengröße
Als Beispiel wird die Größe in drei verschiedenen Varianten dargestellt.
Ergebnisformat:
[% "data-length: " _ data.length _ "\n";
"Body-Length: " _ response.${'Body-Length'} _ "\n";
"Body-Length-Decoded: " _ response.${'Body-Length-Decoded'} _ "\n" %]
Beispielergebnis:
data-length: 70257
Body-Length: 23167
Body-Length-Decoded: 75868
Ergebnisverarbeitung
A-Parser ermöglicht die Verarbeitung von Ergebnissen direkt während der Datenerfassung. In diesem Abschnitt haben wir die beliebtesten Anwendungsfälle für den Net::HTTP-Parser aufgeführt.
Ausgabe der H1-H6 Überschriften
Einen regulären Ausdruck hinzufügen (Option Parse custom results (Parse custom result) (Regulären Ausdruck verwenden)) <(h\d+)[^>]+>(.+?)<\/h\d+>, im Feld „Parse result“ $pages.$i.data - Page content wählen, im Feld gegenüber dem regulären Ausdruck die Modifikatoren sg wählen. Als Ergebnistyp wird automatisch ein Array ausgewählt. Im Feld „Name“ headers angeben, dann in „$1 to“ tag angeben, auf das

content angeben. Im allgemeinen Ergebnisformat die Ausgabe $p1.headers.format('$tag - $content\n') festlegen.Beispiel herunterladen
Wie man ein Preset in A-Parser importiert
eJxtVNuO2jAQ/RVkIS2IW3loH6IVFYuK2ooSlmWfIJUsMgR3HTu1HboI8e+dcUIC
tE+Jj+ccn7nYJ+a4fbMLAxacZcH6xDL/zwI2BxcEX1erRWOrpYStEypp7Ie9/SfW
ZRk3Fgwx1nUg4jHseC4d656YO2aAMtvcOp0uwXqYmeInWKNEApYo3HEW0U4C70h4
bO03m7jTXv8cRZ1Rq9/53H7cbAYeHLEyblWI26SSLBFuDD8i6L9znhK2Bx6T2Uso
2cbEibvVyoFyLDpHUbU91SblVIJmNuyX5P7Og62HJhIbvUazZG426qFdK7/wA6w0
UndCQg1PcVWaaWK+QLsXxXbfvVNleBwLJ7TisjifXNaeXpX4nRNfaYzFXyPATo1O
EXLgBQg8XryvWdOvqbK55z4XHBbsuLTQZRatTjkaie93hAPDnTZhRn4QPzGtxlLO
4ACyDvP6T7mQVJ/xDknfSuL/Q8J/NM5VetdHHcD8MeihUvGrp/BHzYr1TCeXYkiR
CodrO9G5orZ9QPANIKtqNqewVBuojimVy9Nx/jNQMUbWLRtnNXSTxk1bbkGciZ1I
QkzAiBgukbla4SUL1USnmQTKS+VSYlssLOvxGNuyDbSoDd6TJ/4ItFXdNOa0lvb7
S2E1MwLH7yMZTLGS16eWklsu5etydr1DRLylWai+GHPXPj8YbO9cZoPBgPeKm9/f
6nRA9weHOdE4ZpjqOarehepBOV29DsHpjK37ZRdFDOVJEYhhwSz2hQXD81+VjpX2
Sammeln von Meta-Tags
Fügen Sie einen regulären Ausdruck hinzu (Option Parse custom results (Parse custom result) (Regulären Ausdruck verwenden)) (<meta[^>]+>), wählen Sie im Feld "Parse result" $pages.$i.data - Page content, wählen Sie im Feld gegenüber dem regulären Ausdruck den Modifikator g. Als Ergebnistyp wird automatisch ein Array ausgewählt. Geben Sie im Feld "Name" meta an, in "$1 to" geben Sie item an. Verwenden Sie im Ergebnisformat $p1.meta.format('$item\n').
Beispiel herunterladen
Wie man ein Preset in A-Parser importiert
eJxtVO9v2jAQ/V8spBatg/XDvkRTJYqEtokRRtNPNJMscsk8/Gu2Q0FR/vfeJSGB
bp/ie37v3Z3PTsUC93u/duAheBZtK2abNYtYBjkvZWB3zHLnwdH2lq0gRNHXJFkj
3jMqFk4WULMrfTBqA74VunYRbdGiAE8SHjhLaaeAIwpuvygIfPvrIf3wMGYdnrRm
Re/QAdw5fkKw+a64IozkPY9KZCKAYmmdpj26ME5xamlk7yckmOQNcnszIvLLi74Z
Dx5P/ACJQXYuJAzwAqMu5wi7ANo9+4wn4Uj98iwTQRjNZZuS6hnKeNbib0l6bZCL
SyfAL5xRCAVoDAg8ncvdslET03mVjfZnq2FRzqWHO+ax1AXHQrL3O9iX48G42FI9
iFfM6JmUSziAHGiN/2MpZIbzneUo+tYJ/0+J//Go+/YuUx3AvTqsoXdposf4x6DK
zNIU58OQQomAsZ+bUtOkPiG4B7D9ma2IpoyDPk3n3GXHK2xBZ8gcRjazA3TVxtVY
rsGd0bkoYmzAiQzOzFIn+E5iPTfKSqC+dCkljsXDZrgeM9+NgYKhwPfieZPi6oUF
Y6T//tSWap3A6/eZClR4kpdZO8sdl/J5s7zcYcOVwuB3CNZH0yn/2L7dyc6o6avY
i6nQGRynjDwCFAZvF3ZYp/0j738F1cVTj6oaJ/bHr1sOtUcMxPCcPI6DRff1GzD1
gDE=
Varianten des Durchlaufens der Paginierung
Verwendung von Use pages
Use pages. Diese Funktion ermöglicht das Durchlaufen der Paginierung mit Angabe einer im Voraus bekannten Anzahl von Seiten.
Nehmen wir als Beispiel eine Kategorie auf der Website eines Produktkatalogs https://www.proball.ru/catalog/myachi/. Oben und unten sehen wir ein Paginierungs-Panel. Beim Klicken auf die Piktogramme mit den Seitennummern kann man in der Browserzeile sehen, wie der Parameter mit der Seitennummer am Ende des Requests übertragen wird:
https://www.proball.ru/catalog/myachi/?PAGEN_1=1
Use pages ist eine Art Zähler, der tatsächlich in die Variable $pagenum der Reihe nach Nummern einsetzt und diese um den von uns angegebenen Wert erhöht.
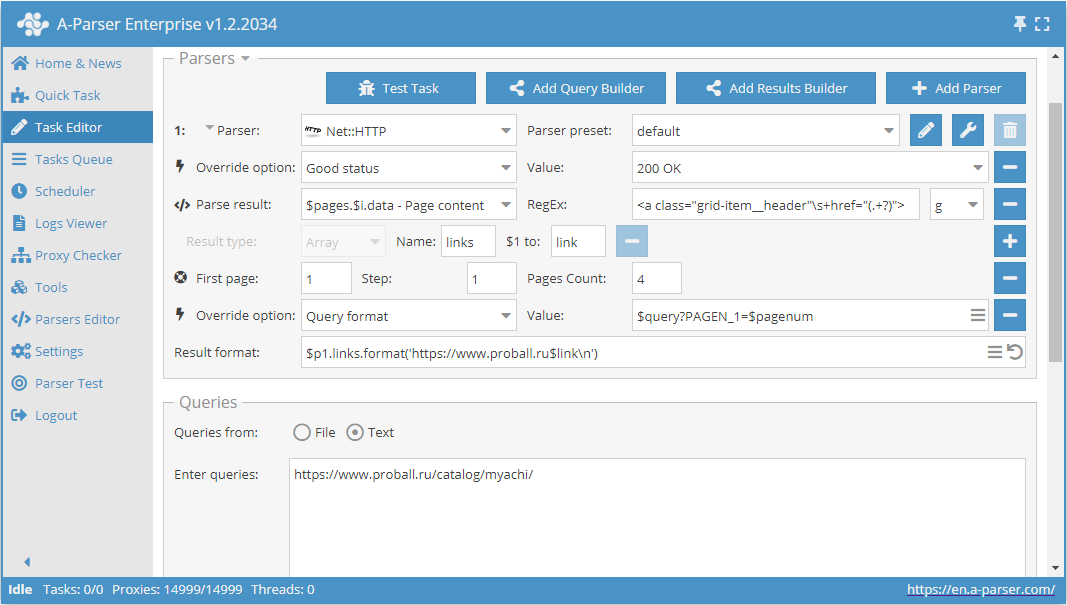
Wie im Screenshot zu sehen ist, wird im Request-Format des Parsers an der entsprechenden Stelle die Variable $pagenum verwendet.
Die Funktion Use pages durchläuft alle Werte und setzt sie in den Request ein, sodass wir faktisch die Links für den Request erhalten:
https://www.proball.ru/catalog/myachi/?PAGEN_1=$pagenum
wobei anstelle der Variable $pagenum die Seitennummer eingesetzt wird, beginnend von 1 bis 4 mit einem Schritt von 1.
Auf diese Weise erfolgt der Durchlauf durch die Seiten des gewünschten Bereichs. Hierin liegt die Einschränkung dieser Methode – man muss die Anzahl der Seiten in der Paginierung im Voraus kennen. Offensichtlich wird bei der gleichzeitigen Erfassung mehrerer Kategorien die Anzahl der Seiten überall unterschiedlich sein, und als Ausweg können wir einfach eine größere Anzahl vermuteter Seiten angeben. Das ist jedoch nicht ganz korrekt, daher gibt es eine optimalere Lösung, die im Folgenden besprochen wird.
Beispiel herunterladen
eJx1VNtu2kAQ/ZVqhJSgUAhV+2I1jSgqvSgCmtAnjKKtPTZu1rubvXAR8r931jY2
pOmTvWfPXM7M7BzAMvNk5hoNWgPB8gCq/IcAnME5SxF6oJg2qP31EqZog+DbYjEn
PMaEOW6hdwC7V0g2coNaZ7E3ymI6p1LGY1meN4w7oizfXV+vitYicsbK/B5N6Qh0
9RMsKWiKxgdhlsHK36S4I4OP7E3EmTE3IaQU6m1mMX98XCOLUYcQhuZqrTGh28v+
1W03hE9Q2y6qgGkTpQaY1mxPYPmdstxjPBNPpiF65SUEp5lLZTMpzFFqXS7TSoWh
9xrHmecxDsGhEvVgUdW3/hxJJ3y930NR/L+Szw71PpE6Z/YkQqeEb+ejr1+mj8Ob
jvcnXA7FatUkP6mMiKyG/VJYv/JzebG2VplgMNhut32l5W/GeV+7jieFobjothV4
YBtcSHKSZBxbeEKnumQdahT626P3bj8ym7MKVJn4arbZ/RLZcylFSOJ6ORmaiZY5
QRZ3tgb3RxXLWrMfCVfa/qxsIEgYN9gDQ6lOGCUSv7yhUdHMSj2rO0cNkWLE+R1u
kLe00v9nl3GaKDNKyOh7bfg6ZfaPj6KRdxqKOrrVlENLiuWdTI/anxBVU42pR3Kp
sXFQR6790otVKPxgtM0YqRY6S/Cs4OdgJEWSpbN62I5MJxa0FmZiLHPF0WcsHOc9
P+P3beNHpi6wP7QJvjQelyEorWZdgJWSmx8PVapKZzRYH5rmE/r6XA4iWgVcpoN8
z6J1NiBbQjCVNA1+c5XjQi9Hl/J6gDvFRIxUEasdFqti1ayyZuEdThZacKAHCH/M
vOJ4VZ5BGJXHUBcgGBZ/AXULzRU=
Verwendung von Check next page
Check next page ist eine weitere Funktion, die es ermöglicht, einen Durchlauf durch die Paginierung zu organisieren. Die Besonderheit ihrer Verwendung besteht darin, dass für den Übergang zur nächsten Seite ein regulärer Ausdruck verwendet werden muss, der den Link zur nächsten Seite zurückgibt. Dies ist eine bequemere und am häufigsten angewendete Methode. Sie lässt sich jedoch nicht für https://www.proball.ru/catalog/myachi/ anwenden, da im Code keine Links zu den nächsten Seiten vorhanden sind. Die Links werden dort per Skript generiert. Nehmen wir daher als Beispiel die Website http://www.imdb.com/search/name?gender=female. Hier gibt es eine Paginierung sowohl am Anfang als auch am Ende der Liste. Nach Analyse des Quellcodes lässt sich ein Link finden, der den Übergang zur nächsten Seite ermöglicht:
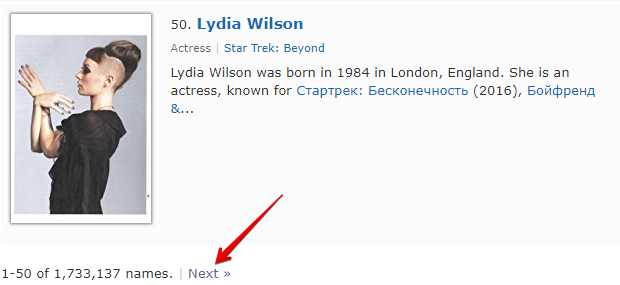
- tragen Sie in das Feld Next page RegEx den regulären Ausdruck ein
- geben Sie im Feld Limit die Anzahl der zu durchlaufenden Seiten an
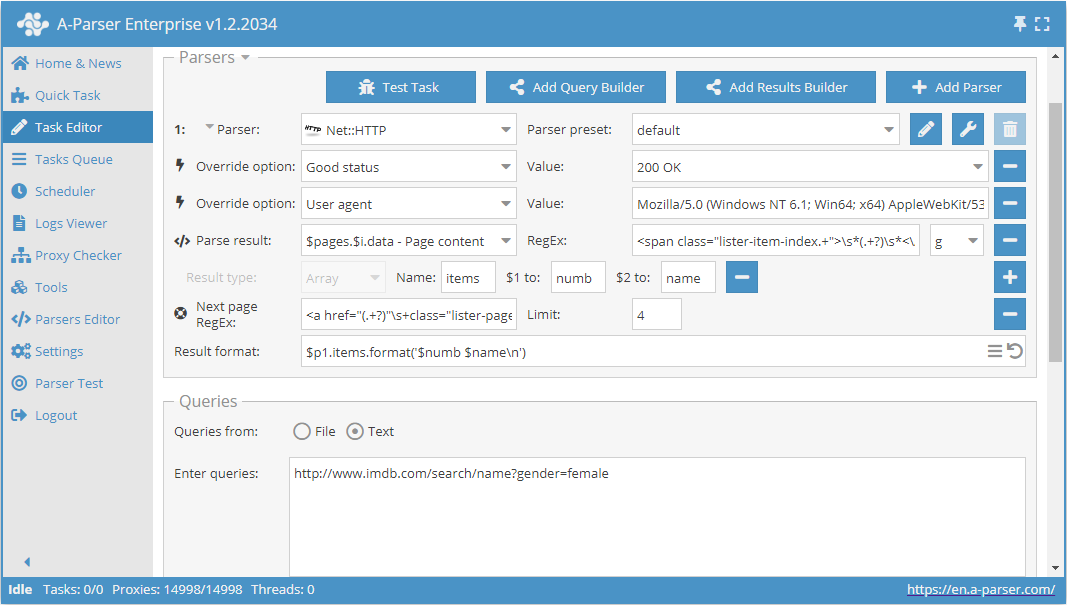
Im Beispiel ist 4 angegeben. Durch Angabe des Limits legen wir fest, wie viele Seiten der Parser durchlaufen soll. In unserem Fall werden 5 Seiten durchlaufen, da die Zählung bei 0 beginnt. Wenn man das Limit auf 0 setzt, arbeitet der Parser so lange, bis er alle Seiten durchlaufen hat, unabhängig von deren Anzahl. Dies ist sehr praktisch, wenn man alle Ergebnisse von allen Seiten extrahieren möchte.
Beispiel herunterladen
eJx1VGFT2kAQ/SuZG2aUggGq4DSijnXG2qpAlY4fCM6cZANXL7n07iJYhv/e3RAS
sO0XuH3ZvX1vd2+XzHLzYgYaDFjDvNGSJdmZeWwyg8lLDxZ2wKfA6izh2oAmpxHr
gfW86+FwgHgAIU+lZfUls28JYKR6Ba1FQEEiQHuqVHCpMvuVyxRdRh+bzfHq/xEp
ZjrAtLEtY9id+i2k5I2223T2H0UcqLlxekOn47ZOHLQ7RyfOonNUdS6SRMIjPN8I
22gfHruHHWf/5np4d1t3pHgB5wsKU1XncqZVBI32J7fpHjaPW26r1XYeeMi1yMPY
FsVJaqyK7sFkWpleH7wR1mUKhurALWdj+jKFBQZ0TcJjZyK5Mac+k8JY1CQsRAdI
HRZuzWdnvm8+7Lu18yodur7foBhCa10+ejob19Yeo6fueMuJn7E8zXDNbVoQygGu
NX9DMPvv8YgwSm0KR+oji9PoGZGYHHbakVihYrPpxvtJ2DSky52ZhhDVrTUwIv5O
MFXnIMZYh34y02fELAgEJeGSecvdDLciEjSAR2y1Go8LwldKR5zwStJyMzFumEH7
exUS4lRIh+/He9VS5QN/haHCoFBIKOErtPKyVLBvQF83t1Vdu7A7DNeZqWIlmx+x
+JUVIVboi0ctwFzhQCFkIbuAwLcN6xGrZDZNSJrFfl/HMC/k0kCdGaR6xZFI8P4L
itXcKt3P24IFU/GFlLfwCrJ0y+7/nAoZ4DO9CDHoax74b5f+X3esCnnbqfBtzjVy
KJ0CdaumG+0vAElRjR4hkdJQXJBnzu/FTZNATENVNgOfawHtENwp+C44UXEopv18
bWw803iI66wfX6oINwAxjlMp67RO7svGX5i8wGSUBN8HX2YpkFax4JhVSppvD2uq
iRY4WO2i+YjOrE28RmM+n7siCp7diYoaBriezBo0m+e40FDCaQgRz6ZxgqM3VTgU
tHizqaHhMZQKFrgJAsCyWJ3CarwaFxu42NbLrT3sLVfYmJ9msPYhaeSBGNbIYCuY
11r9ASIaBUM=
Wie oben erwähnt, besteht die Möglichkeit, die Anzahl der Seiten in Use pages dynamisch zu begrenzen. Dazu müssen Use pages und Check next page gemeinsam verwendet werden. Ergänzen wir das Beispiel, das bei der Beschreibung von Use pages betrachtet wurde, und fügen die Funktion Check next page hinzu:
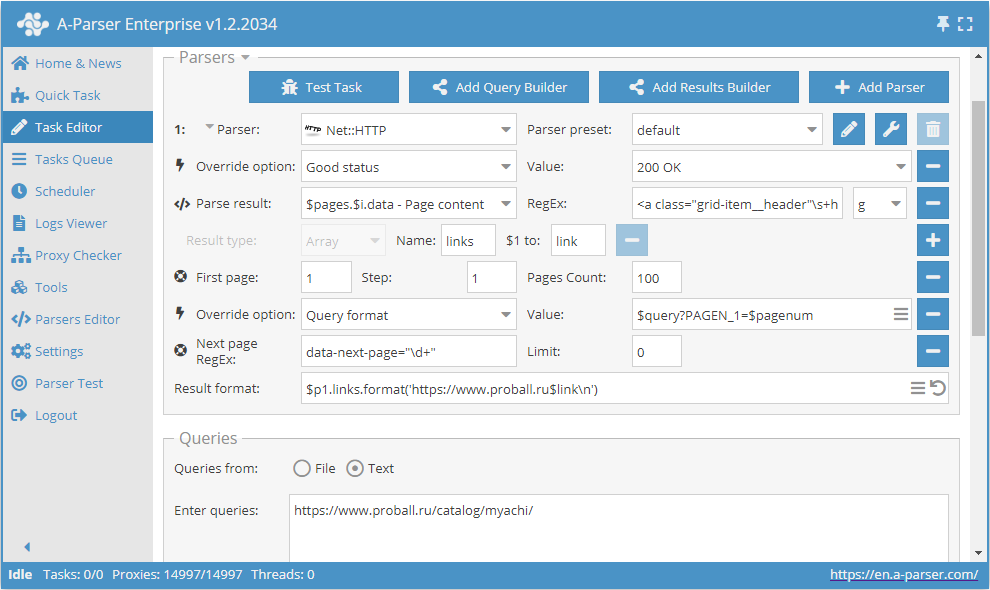
Diese beiden Funktionen arbeiten im Team wie folgt: Use pages sorgt für den Durchlauf durch die Seiten, und Check next page prüft, ob die nächste Seite existiert. Sobald Check next page keine nächste Seite mehr findet, wird die Datenerfassung dieser Kategorie gestoppt, ohne den gesamten in Use pages angegebenen Bereich abzuwarten. Durch die Kombination dieser Funktionen erhöhen wir die Effizienz des Parsers und sparen Zeit sowie Ressourcen.
Beispiel herunterladen
eJx1VNtuGjEQ/ZXKQkqiEC6V+rJqGtGo9KIIaEKfWBS5u7OLi9d2bC8EIf69M3uF
XJ52fTyXM2fGs2eeu7WbWXDgHQsWe2aKfxaw3MGMp8C6zHDrwNL1gk3AB8GP+XyG
eAwJz6Vn3T3zOwPoozdgrYjJScR4TrWOb3Vx3nCZo8ni42CwPLQeUe68zu7BFYGY
LX+CBSZNwVES7jlb0k0Kz+jwmX+IJHfuOmQpproSHrLHxxXwGGzIwtBdriwkeHve
u7y5CNkXVvnOy4Rpk6UCuLV8h2DxnfCMMCnU2jWGVHkBsWPm2nihlatLreRybals
SFHjWJAdlyzYl0U9eDDVLZ0jnSvSezgYsMPhfS2fcrC7RNuM+6McnQK+mY2+f5s8
Dq87FFHlGXufaLSCaD2BZ191t45EQl8pxK8oxjVpGV+G7FUNJ/53IhNEnqgvl41g
45Im0jPDXiFmr2R+frby3rig399utz1j9V8uZc/mHTIKQ3V20ar+wDcw1xgkERJa
eIynqk0d5Ax0W0e/6EVuc8K4ZEIdbNn9UeKpKFlptCUBBbix1RlCHgurwF1dxaJS
mcYwL3x/lz4sSLh00GUOqY45Eolf3uB4Wu61nVZNQAG1Gkl5BxuQrVkR/2suJE6x
GyXo9LNyfNtk+irGoSnvOBXO0NYih9Yo1nc6rWtfA5hGjQkhmbbQBKgyV3FxSxhQ
NEJtM0amhU4Ingh+CkZaJSKdVuNdW+Zqjqtoqm51ZiQQY5VL2aV3dd82fuQqgenQ
EnzpfFukoKGuVxTzWkv366GkaqzAwfrUNB/Rt+eyH+GrkDrtZzserUQffRGBVOM0
0LYsxgWfmC3K6zJ4NlzFgIoMD8vDstmdzYbdH23QYI/vnf1zs9KGSiILxFAbhy2g
KP8Byg3yDQ==
Verwendung von Substitutions-Makros
Substitutions-Makros ermöglichen die sequentielle Einsetzung von Werten aus einem angegebenen Bereich.
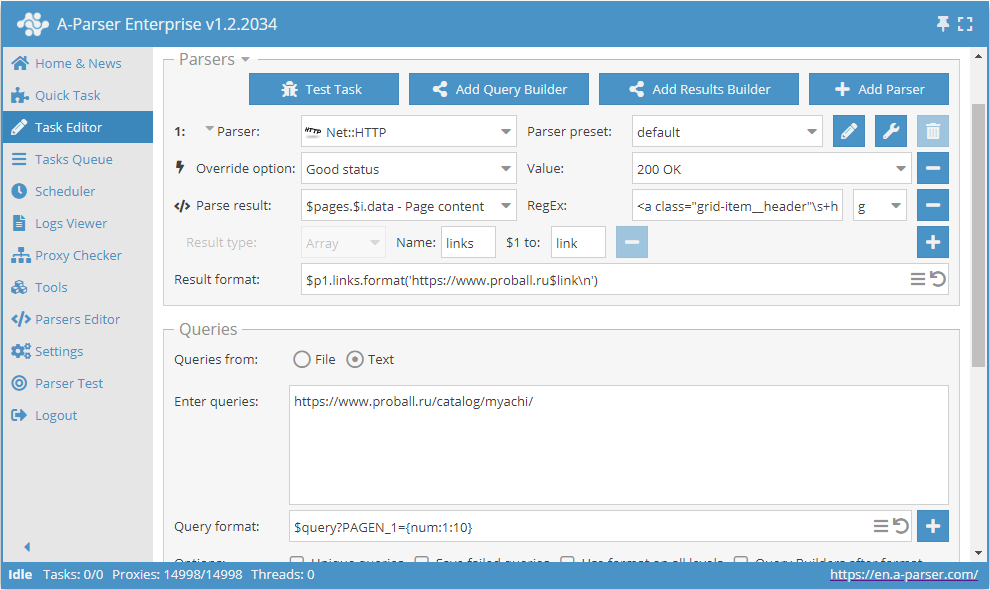
Dieses Preset funktioniert wie folgt. Durch Angabe des Templates im Request-Format:
$query?PAGEN_1={num:1:10}
fügen wir die Einsetzung von Werten von 1 before 10 (der Bereich kann beliebig gewählt werden) in den Request selbst ein. Auf diese Weise erhalten wir Anfragen, die den Durchlauf durch die gewünschte Anzahl von Seiten gewährleisten, in der Form:
https://www.proball.ru/catalog/myachi/?PAGEN_1=1
https://www.proball.ru/catalog/myachi/?PAGEN_1=2
...
https://www.proball.ru/catalog/myachi/?PAGEN_1=10
Die Verwendung von Substitutions-Makros für den Paginierungsdurchlauf ähnelt der Funktion Use pages und hat dieselben Einschränkungen, d. h. es muss ein konkreter Wertebereich angegeben werden. Der Vorteil dieser Methode besteht darin, dass über Substitutions-Makros verschiedene Werte eingesetzt werden können, sowohl numerische als auch textuelle, zum Beispiel Wörter oder Ausdrücke. So können wir flexibler benötigte Teile in Requests einfügen oder die Requests selbst aus Teilen zusammensetzen, die sich in verschiedenen Dateien befinden, falls die Aufgabe dies erfordert.
Beispiel herunterladen
eJxtVFtP2zAU/iuTVQkQXUsn7SUaQx2iu4i1HXRPTYW85CT1cGzPx+lFUf47x26a
AOMp8Xcu3+dzccUcx0ecW0BwyKJlxUz4ZxH7yROr8WbH+sxwi2C9fcmm4KLo22Ix
JzyFjJfSsX7F3N4ABekNWCtSIKNI6ZxrnV7rcN5wWZLL8sPFxaruIpISnS7uAEMi
Zg8/0ZJIc0BPwh1nK2/JYUcBn/i7RHLEy5jlRPVeOCgeHtbAU7Axi2M8X1vIyHo6
OL86i9ln1sQuDoR5y9IA3Fq+JzB8p7zwmBTqEVtHf/MAsVW9WrXoRNuC+1L1zGgQ
IgZZgE5P1s4ZjIbD7XY7MFb/4VIObNnzTnGsTs661Pd8AwtNSTIhoYMndGq09KgC
4K3H7GeDBDdecJoKJ7Ti8qDEy+zU/Vbiny84U5p86dcKwInVBUEOdq4B98dbLFkv
nK/m468304fRZaXKIhpFo4val78M6X4d0rAo4xKhz5DUTzhpS19bqC2WO21nxksk
vGJajaW8hQ3Izi1QfimFpO7hOKOg703g2y6z/3LU7Y2fU9Ecbi1p6JxSfavzYzke
AUxboKlHCm2hTdAwN3lpPQwoP85df8amg14IfNGDl2CiVSbyWbMiR89SLWgHZ+pa
F0aCV6xKKangCHfdLIyxKbA/dAJfB18HCpLVriZzWkv8cX+QaqygWfvYzgOhb4/q
MKG1kzofFnuerMWQYgmBXNt9eCbCBPlBQs8BO8NVClQPZ0uoaUvaR6N9W6pnT0dU
1dSRvzg/+Pg7eQ/CqDhIPWDRqH4C36ybyg==
Verwendung von Page as query
Um den Speicherverbrauch zu senken, kann die Logik mit der Option Page as query definiert werden. Bei ihrer Aktivierung werden die Funktionen Check next page und Use pages jede folgende Seite als eigenständigen Request in die Anfragen einfügen, wodurch deren Inhalt nicht im Speicher angesammelt wird. Page as query ermöglicht es zudem festzulegen, ob die Ebene des Requests erhöht werden soll Increase (analog zur Arbeitsweise des Tools tools.query.add) oder nicht Keep.
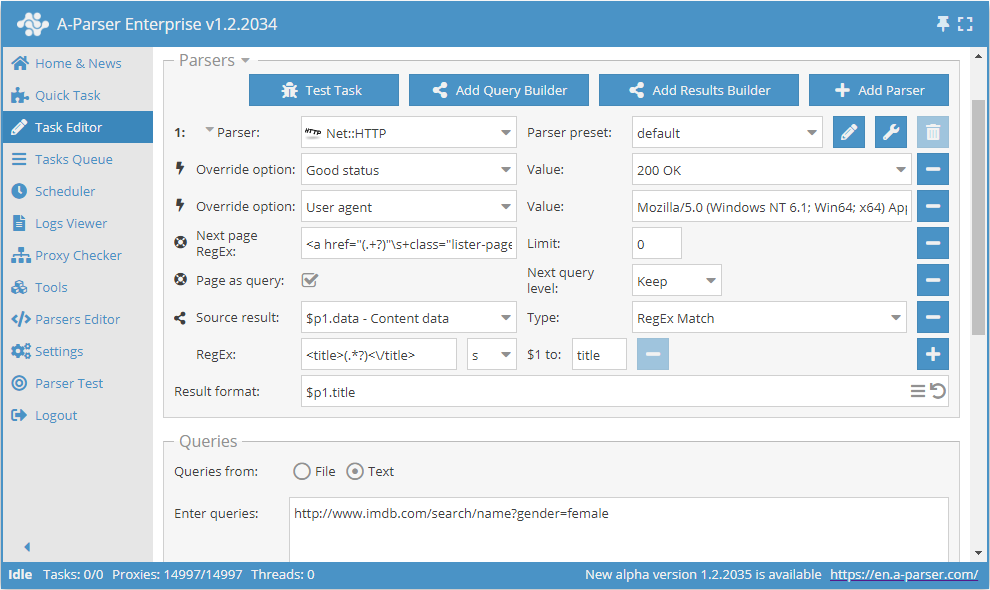
Beispiel herunterladen
eJx1VNty2jAQ/RWPJg/QEts0gUydpBnCDE0bAiQhkwfgQbHXoCJbriQDKcO/dyXM
tc0LeFd7OXv2siSaqqnqSVCgFQkGS5LZbxKQHh1DQ3Vg/piDfCcVklGpQBqrAemA
DoK7fr+H+ghimnNNKkui3zNAVzEDKVkE+MgilMdCRE1h5RnlOZoMvvj+aPWxR46Z
ThFAqnc+5EH8YZxTr+b6TumVpZGYK6fTd+pu9dJBuX5+6Szq52WnkWUcXuHtnmmv
dnbhntWd0v1d/6FdcTibgvMdwqkoO82JFAl4ta+u7575F1W3Wq05zzSmkhVuZB9i
pplI1QZhOMEgHVhow9MeyCvqTCTE10NScj/flIdkOFSfQ06VQhVnSmNhGbqcpujr
mB8rDgnGoFHETBLKSbA8zNBmCTNd8cnqY0zZccsKUFrmcBx9CpBZszbMADX+ajUa
VQh2H3upWkIm1OQ7yaquZpqbEou3ZzqDvsC3mO2rWyh1aGJgnURUg3l1YxunVHb1
Qh8UuE5ghmmX9CVlvy2HqUBb/JQMVAt7hCoNNoBRvm/ADciJlQmGyK3v49qHBDHl
CktWCLVFEUh0/MKwD1QL2S0YREZE2uDcsrEzs/Fvc8YjnPxGjE4/Csf/m3T/ibHa
lrefCsd9LhHDNoqVbrsPO69ItMUYK4/esG5u2o+yaoo8Xc9BxbZwy1nHcJYICds0
ReQiO+54BqmZkl3LcE+2qoMyDtqyp1wSJXIZmgX2ESHV1HBfDKOEMSxscPOPm2Dn
5lvJ/XRTvhoOvbW4MeivnczsamF6uZ6y0QoDhiKN2bhb3IQNmjzt47Hqpk2R4Hob
7tKc84q5FU+7EWyootVG2JFw7Ny0KQy9m+uFMARXP5/XdGSSIaqaAZtgt/azFiFD
yvnLU3v/hezGFoWJ1lngefP53GVJ9OaGIvEUUBlOvBT35AavG9J6HUNC7R6FuDRj
geOM5RoWinu7Pc7LvasbLPEMkF+qt7YxtRoL1CFpCvtPgurqL0u6AK8=
Mögliche Einstellungen
| Parametername | Standardwert | Beschreibung |
|---|---|---|
| Good status | All | Auswahl, welche Antwort vom Server als erfolgreich gilt. Wenn bei der Datenerfassung eine andere Antwort vom Server kommt, wird der Request mit einem anderen Proxy wiederholt. |
| Good code RegEx | Möglichkeit, einen regulären Ausdruck zur Überprüfung des Statuscodes anzugeben. | |
| Ban Proxy Code RegEx | Möglichkeit, Proxys zeitweise zu sperren (Proxy ban time) basierend auf dem HTTP-Statuscode des Servers. | |
| Method | GET | Request-Methode. |
| POST body | Inhalt, der bei Verwendung der POST-Methode an den Server übertragen wird. Unterstützt Variablen wie $query – Request-URL, $query.orig – ursprüngliche Anfrage und $pagenum – Seitennummer bei Verwendung der Option Use Pages. | |
| Cookies | Möglichkeit, Cookies für den Request anzugeben. | |
| User agent | _Automatisch wird der User-Agent der aktuellen Chrome-Version eingesetzt_ | Der User-Agent Header beim Abrufen von Seiten. |
| Additional headers | Möglichkeit, beliebige Request-Header anzugeben, unterstützt durch die Funktionen der Template-Engine und unter Verwendung von Variablen aus dem Abfrage-Builder. | |
| Read only headers | ☐ | Nur Header lesen. In einigen Fällen spart dies Traffic, wenn der Inhalt nicht verarbeitet werden muss. |
| Detect charset on content | ☐ | Kodierung basierend auf dem Seiteninhalt erkennen. |
| Emulate browser headers | ☑ | Browser-Header emulieren. |
| Max redirects count | 7 | Maximale Anzahl an Weiterleitungen, denen der Parser folgt. |
| Follow common redirects | ☑ | Ermöglicht Redirects zwischen http <-> https und www.domain <-> domain innerhalb derselben Domain unter Umgehung des Max redirects count Limits. |
| Max cookies count | 16 | Maximale Anzahl an zu speichernden Cookies. |
| Engine | HTTP (Fast, JavaScript Disabled) | Ermöglicht die Wahl der Engine: HTTP (schneller, ohne JavaScript) oder Chrome (langsamer, JavaScript aktiviert). |
| Chrome Headless | ☐ | Wenn diese Option aktiviert ist, wird der Browser nicht angezeigt. |
| Chrome DevTools | ☐ | Ermöglicht die Verwendung von Chromium-Entwicklungstools. |
| Chrome Log Proxy connections | ☐ | Wenn diese Option aktiviert ist, werden Informationen zu Chrome-Verbindungen im Log ausgegeben. |
| Chrome Wait Until | networkidle2 | Bestimmt, wann eine Seite als geladen gilt. Mehr zu den Werten. |
| Use HTTP/2 transport | ☐ | Bestimmt, ob HTTP/2 anstelle von HTTP/1.1 verwendet werden soll. Einige Websites sperren sofort bei Verwendung von HTTP/1.1, während andere umgekehrt nicht mit HTTP/2 funktionieren. |
| Try use HTTP/1.1 for Protocol error | ☑ | Weist den Parser an, den Request mit HTTP/1.1 zu wiederholen, wenn HTTP/2 aktiviert war und ein Protokollfehler auftrat (d. h. wenn die Website nicht mit HTTP/2 funktioniert). |
| Don't verify TLS certs | ☐ | Deaktivierung der TLS-Zertifikatsvalidierung. |
| Randomize TLS Fingerprint | ☐ | Diese Option ermöglicht die Umgehung von Website-Sperren basierend auf dem TLS-Fingerprint. |
| Bypass CloudFlare with Chrome | ☐ | Automatische Umgehung der CloudFlare-Prüfung. |
| Bypass CloudFlare with Chrome Max Pages | 20 | Maximale Anzahl an Seiten bei der CF-Umgehung via Chrome. |
| Bypass CloudFlare with Chrome Headless | ☑ | Wenn diese Option aktiviert ist, wird der Browser während der CF-Umgehung via Chrome nicht angezeigt. |