HTML::LinkExtractor - Scraper di link esterni e interni da un sito specificato
Panoramica dello scraper
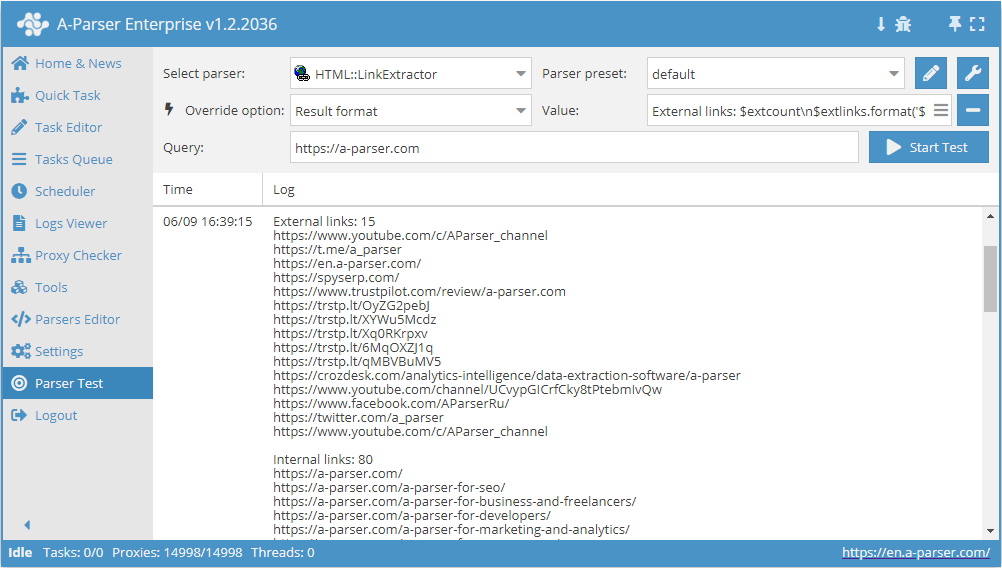
 HTML::LinkExtractor – scraper di link esterni e interni da un sito specificato. Supporta lo scraping multipagina e la navigazione attraverso le pagine interne del sito fino alla profondità specificata, consentendo di scansionare tutte le pagine del sito raccogliendo link interni ed esterni. Dispone di strumenti integrati per il bypass della protezione CloudFlare e anche la possibilità di scegliere Chrome come motore per lo scraping di email dalle pagine i cui dati vengono caricati tramite script. È in grado di raggiungere una velocità fino a 2000 richieste al minuto – ovvero 120 000 link all'ora.
HTML::LinkExtractor – scraper di link esterni e interni da un sito specificato. Supporta lo scraping multipagina e la navigazione attraverso le pagine interne del sito fino alla profondità specificata, consentendo di scansionare tutte le pagine del sito raccogliendo link interni ed esterni. Dispone di strumenti integrati per il bypass della protezione CloudFlare e anche la possibilità di scegliere Chrome come motore per lo scraping di email dalle pagine i cui dati vengono caricati tramite script. È in grado di raggiungere una velocità fino a 2000 richieste al minuto – ovvero 120 000 link all'ora.Casi d'uso dello scraper
Raccolta di tutti i link esterni da un sito
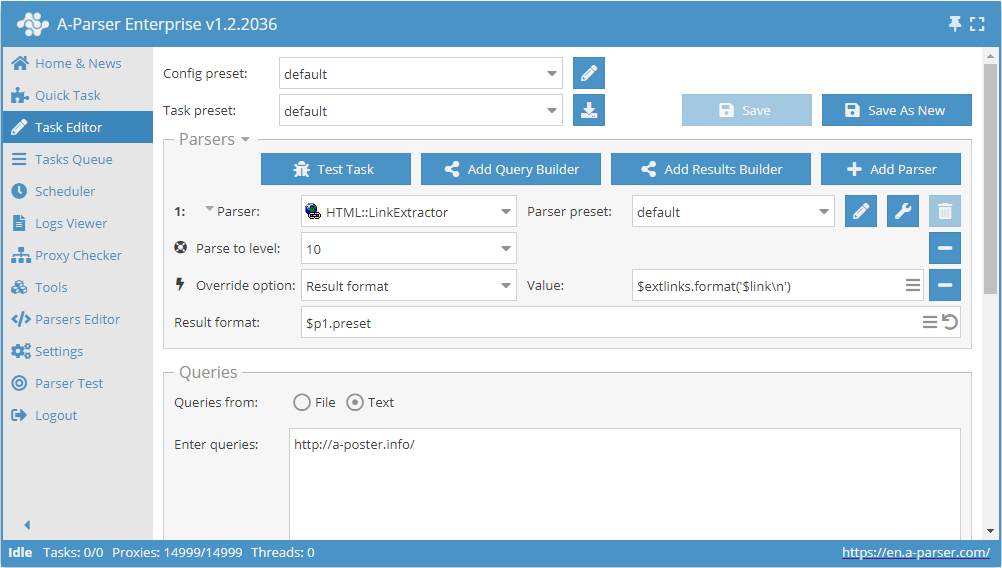
- Aggiungere l'opzione Parse to level, selezionare il valore
10nell'elenco (navigazione attraverso le pagine adiacenti fino al 10° livello). - Aggiungere l'opzione Result format, indicare come valore
$extlinks.format('$link\n')(output dei link esterni). - Nella sezione Queries (Query), spuntare l'opzione
Unique queries. - Nella sezione Results (Risultati), spuntare l'opzione
Unique string. - Come query, indicare il link al sito da cui si desidera estrarre i link esterni.
Scarica l'esempio
Come importare l'esempio in A-Parser
eJxtU01v2zAM/S9CgK5AlrSHXnxLgwZb4dZdm57SHISYztTIoirRWQrD/32U7NjJ
1ptIvsfHL9WCpN/5JwceyItkVQsb3yIRORSy0iTGwkrnwYXwSvxYPqRJkiqzuzuQ
kxtCx4geWwv6tMBstKTQeI6pnM2YIoU9aPbspa4Yc33VnOD34JzK4Ugo0JWSuJa2
hI4iRnAgzeJ+0gK+XYyC+fZmLi5Fs16PRUvxixgODHs96Xrqgy9yD0sMKkrD4F6w
9SjLqJNLghA96lxO6BAyyDxXoTOpW4UwlUH11aiPWKcnp8yW8Ww6BX7hsGQ3QUwS
nJ/HCldiFG3BaarI/9VyREKugrHwXO1Cci15Hyik9hxRBE7yBrJu2Ekt0My0joMe
YDH9baV0zlucFUz62RG/hmT/5Wj6Dk+leGV/HNfQZ4nWbfYwsHJMccuNG+S2tSoV
se3nWJmwmyt27gBsP7bHACvRQS/TZe7U+VAtmHAfw9ZmdnCdtXG2mXPnBk2htll3
c0dkZZb8GzIzx9JqCH2ZSmveiofn4UJmvltDMIYC/yXPo8TZPyJE7e9f2lKtU3yB
N6HAkid5qtql3EitX5/T04gYLoqN30Q2mU7ld4ueFzpRpsCpCESCLfJFcVvNuv+/
/S+vv/zFSd3wwt79U4sO3QUs+3hMnrfBP7b5C6wbebo=
suggerimento
Raccolta di tutti i link interni da un sito
Analogamente al primo caso, ma al passaggio 2 indicare come valore $intlinks.format('$link\n') (output dei link interni).
Scarica l'esempio
Come importare l'esempio in A-Parser
eJxtU8tu2zAQ/BfCQBrAtZNDL7o5Roy2cOI0j5PjA2GtXNYUyZIrN4Ggf++QkiW7
zY27O7OzL9aCZdiHB0+BOIhsXQuX3iITORWy0izGwkkfyMfwWnx9vltm2VKZ/e0b
e7ll64HosbXgd0dgW8fKmoCYymGmFEs6kIbnIHUFzPVVc4I/kPcqpyOhsL6UjFra
EjqKGCnDGuJh0gI+XYyi+fpqLi5Fs9mMRUsJixSODHc96Xrqg0/yQM82qihNg3sB
616WSSeXTDF61Lmc8FvMIPNcxc6kbhXiVAbVF6N+pzoDe2V2wMP0isLC2xJuppQk
Ot+PFa7FKNkCaarE/9FyRMa+orEIqHYhUUveBwqpAyKKyUtsYNUNO6uFNTOt06AH
WEp/UymdY4uzAqRvHfFjyOq/HE3f4akUVvbHo4Y+S7JuVncDK7dLu0PjxqJtrUrF
sMPcVibu5grOPZHrx3YfYaX11Mt0mTt1HKojE+9j2NrMDa6zNs42c+7cWlOo3aq7
uSOyMs/4DSszt6XTFPsyldbYSqDH4UJmoVtDNIYC/yXPk8TZP2Jrdfj+1JbqvMIF
fokFlpjkqWqXciu1fnlcnkbEcFEwfjK7bDqVn50NWOhEmcJORSQy7SwuCm01m/7/
9r+8/vAXZ3WDhf0KDy06dhex8GFMAdvAj23+ApcrebQ=
Navigazione solo sui link che non contengono la parola forum
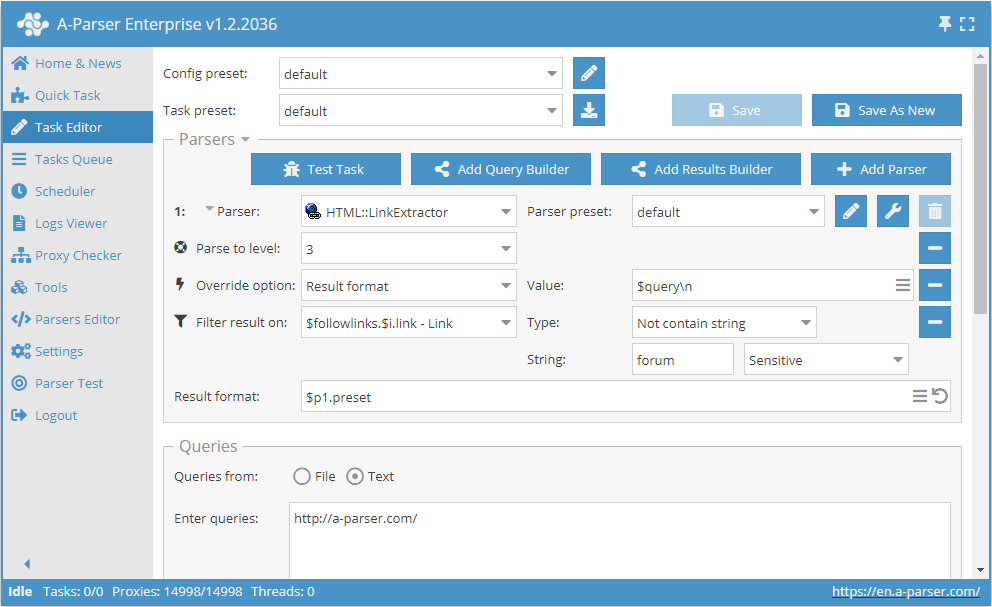
- Aggiungere l'opzione Parse to level, selezionare il valore
3nell'elenco (navigazione attraverso le pagine adiacenti fino al 3° livello). - Aggiungere l'opzione Result format, indicare come valore
$query. - Aggiungere un filtro. Filtrare per
$followlinks.$i.link - Link, scegliere il tipoNot contain string, e indicareforumcome stringa stessa. - Nella sezione Queries (Query), spuntare l'opzione
Unique queries. - Nella sezione Results (Risultati), spuntare l'opzione
Unique string. - Come query, indicare il link al sito da cui si desidera estrarre i link.
Scarica l'esempio
Come importare l'esempio in A-Parser
eJxtVE1v2zAM/S/CDhuQJS2GXXxLgwbd4DZdm57SHISYzrTIkipRaQvD/33UR2xn
6ykh+R75+CG3DLk7uHsLDtCxYtMyE/+zglVQcy+RTZjh1oEN4Q27Wd+WRVEKdbh+
Q8t3qC0hemzL8N0AsbVBoZWjmKjIjClKOIIkz5FLT5hv3Qh+BGtFBSd8rW3DkaQk
BZnBPr14sO/Pz4qNuLWQCEFFhhcbokupXyWpDArCL9tOMnCdWErjTivkQo3yU1nf
kJ3Uk8MB9dBtt6fkbhmFBSnmcppn1Qcf+RHWOkmCwb0k6443sYGKI4ToNHX4+csU
30IGXlUi1OQyVQjTHqo+KfESBTq0Qu0JHwYhwC2tbsiNEJPE6ZwUbvK0Quc+8n8l
DivQepgwR2qXnLRUfaDm0lFE0Jg4bXaVl1i0TKu5lHGBAyymv/JCVnQd85pIPzLx
Y8jqvxxd3+G4FN3CqyUNfZZoXa1uB1alS72PW4z7bQSS7Rbaq7CbC3IeAEw/trsA
a7SFvkzOnKvTAzCgwuENW5ubwXXWxtlmzp10UbXYr/Ixn5BeremVrdRCN0ZC6Et5
KWkrDh6GC5m7vIZgDAL/JS9iibP3iVpL9/MxSTVW0AV+DwIbmuS4ak6541I+PZTj
CBsuiozfiKaYzfjX9PCnO93MWOAh7DUdFHXVbfvPQv/xaD/8OBRtR/v64+4TOjQX
sOSjKbn4yi67v8azl7c=
suggerimento
Dati raccolti
- Numero di link esterni
- Numero di link interni
- Link esterni:
- i link stessi
- anchor
- anchor puliti dai tag HTML
- parametro nofollow
- tag
<a>completo
- Link interni:
- i link stessi
- anchor
- anchor puliti dai tag HTML
- parametro nofollow
- tag
<a>completo
- Array con tutte le pagine raccolte (utilizzato quando l'opzione Use Pages è attiva)
Funzionalità
- Scraping multipagina (navigazione tra le pagine)
- Navigazione attraverso le pagine interne del sito fino alla profondità specificata (opzione Parse to level) – permette di scansionare tutte le pagine del sito, raccogliendo link interni ed esterni
- Limite di navigazione tra le pagine (opzione Follow links limit)
- Pulisce automaticamente l'anchor dai tag HTML
- Rilevamento di nofollow per ogni link
- Possibilità di specificare se considerare i sottodomini come pagine interne del sito
- Supporta la compressione gzip/deflate/brotli
- Rilevamento e conversione della codifica dei siti in UTF-8
- Bypass della protezione CloudFlare
- Scelta del motore (HTTP o Chrome)
Casi d'uso
- Ottenimento di una mappa completa del sito (salvataggio di tutti i link interni)
- Ottenimento di tutti i link esterni da un sito
- Verifica dei backlink al proprio sito
Query
Come query è necessario indicare i link alle pagine da cui raccogliere i link, o un punto di ingresso (ad esempio, la home page del sito), nei casi in cui si utilizzi l'opzione Parse to level:
https://lenta.ru/
https://a-parser.com/wiki/index/
Esempi di output dei risultati
A-Parser supporta una formattazione flessibile dei risultati grazie al motore di modelli integrato Template Toolkit, che gli consente di produrre risultati in forma libera o strutturata, come CSV o JSON
Output di link esterni e interni con il relativo conteggio
Formato del risultato:
External links: $extcount\n$extlinks.format('$link\n')
Internal links: $intcount\n$intlinks.format('$link\n')
Esempio di risultato:
External links: 12
https://www.youtube.com/c/AParser_channel
https://t.me/a_parser
https://en.a-parser.com/
https://spyserp.com/ru/
https://sitechecker.pro/
https://arsenkin.ru/tools/
https://spyserp.com/
http://www.promkaskad.ru/
https://www.youtube.com/channel/UCvypGICrfCky8tPtebmIvQw
https://www.facebook.com/AParserRu
https://twitter.com/a_parser
https://www.youtube.com/c/AParser_channel
Internal links: 129
https://a-parser.com/
https://a-parser.com/
https://a-parser.com/a-parser-for-seo/
https://a-parser.com/a-parser-for-business-and-freelancers/
https://a-parser.com/a-parser-for-developers/
https://a-parser.com/a-parser-for-marketing-and-analytics/
https://a-parser.com/a-parser-for-e-commerce/
https://a-parser.com/a-parser-for-cpa/
https://a-parser.com/wiki/features-and-benefits/
https://a-parser.com/wiki/parsers/
Impostazioni possibili
nota
| Nome parametro | Valore predefinito | Descrizione |
|---|---|---|
| Good status | All | Scelta di quale risposta dal server sarà considerata corretta. Se durante lo scraping si riceve una risposta diversa dal server, la query verrà ripetuta con un altro proxy |
| Good code RegEx | Possibilità di specificare un'espressione regolare per controllare il codice di risposta | |
| Ban Proxy Code RegEx | Possibilità di bannare il proxy temporaneamente (Proxy ban time) in base al codice di risposta del server | |
| Method | GET | Metodo della richiesta |
| POST body | Contenuto da inviare al server quando si utilizza il metodo POST. Supporta le variabili $query – URL della richiesta, $query.orig – query originale e $pagenum - numero di pagina quando si utilizza l'opzione Use Pages. | |
| Cookies | Possibilità di specificare i cookie per la richiesta. | |
| User agent | _Viene inserito automaticamente lo user-agent della versione attuale di Chrome_ | Intestazione User-Agent durante la richiesta delle pagine |
| Additional headers | Possibilità di specificare intestazioni di richiesta personalizzate con supporto alle funzionalità del motore di modelli e utilizzo di variabili dal costruttore di query | |
| Read only headers | ☐ | Leggi solo le intestazioni. In alcuni casi permette di risparmiare traffico se non è necessario elaborare il contenuto |
| Detect charset on content | ☐ | Riconoscimento della codifica in base al contenuto della pagina |
| Emulate browser headers | ☐ | Emula le intestazioni del browser |
| Max redirects count | 0 | Numero massimo di reindirizzamenti che lo scraper seguirà |
| Follow common redirects | ☑ | Consente di effettuare reindirizzamenti http <-> https e www.domain <-> domain all'interno dello stesso dominio bypassando il limite Max redirects count |
| Max cookies count | 16 | Numero massimo di cookie da salvare |
| Engine | HTTP (Fast, JavaScript Disabled) | Permette di scegliere il motore HTTP (più veloce, senza JavaScript) o Chrome (più lento, JavaScript abilitato) |
| Chrome Headless | ☐ | Se l'opzione è attiva, il browser non verrà visualizzato |
| Chrome DevTools | ☑ | Permette di utilizzare gli strumenti di debug di Chromium |
| Chrome Log Proxy connections | ☑ | Se l'opzione è attiva, le informazioni sulle connessioni chrome verranno visualizzate nel log |
| Chrome Wait Until | networkidle2 | Determina quando la pagina è considerata caricata. Maggiori informazioni sui valori. |
| Use HTTP/2 transport | ☐ | Determina se utilizzare HTTP/2 invece di HTTP/1.1. Ad esempio, Google e Majestic bannano immediatamente se si utilizza HTTP/1.1. |
| Don't verify TLS certs | ☐ | Disabilitazione della validazione dei certificati TLS |
| Randomize TLS Fingerprint | ☐ | Questa opzione permette di bypassare il ban dei siti basato sull'impronta TLS |
| Bypass CloudFlare | ☑ | Bypass automatico del controllo CloudFlare |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Bypass di CF tramite Chrome |
| Bypass CloudFlare with Chrome Max Pages | 20 | Numero massimo di pagine durante il bypass di CF tramite Chrome |
| Subdomains are internal | ☐ | Se considerare i sottodomini come link interni |
| Follow links | Internal only | Quali link seguire |
| Follow links limit | 0 | Limite Follow links, applicato a ogni dominio unico |
| Skip comment blocks | ☐ | Se saltare i blocchi di commenti |