SE::Yandex::WordStat - WordStat-Parser. Erfassung von Keywords und Impression-Statistiken
Übersicht des Parsers
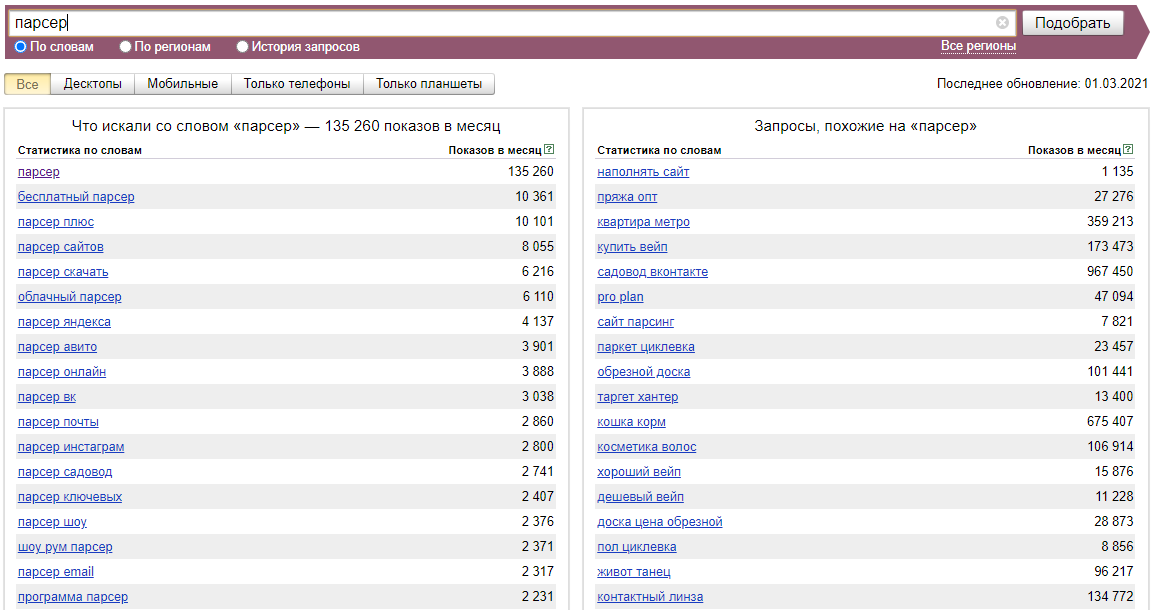
Wordstat (Vordstat) ist ein Dienst von Yandex, der zur Bewertung des Nutzerinteresses an verschiedenen Themen und zur Auswahl von Schlüsselwörtern für die SEO-Optimierung und Kontextwerbung entwickelt wurde. Darüber hinaus kann man mit Wordstat Yandex die Saisonalität und geografische Abhängigkeit von Suchanfragen bewerten.
Der Yandex WordStat Keyword-Parser unterstützt die automatische Vervielfachung von Abfragen, sodass Sie sicher sein können, die maximale Anzahl an Ergebnissen aus der Ausgabe zu erhalten. Zudem kann A-Parser automatisch verwandten Abfragen bis zu einer angegebenen Tiefe folgen.
Die Funktionalität von A-Parser ermöglicht es, Datenerfassungseinstellungen für die spätere Verwendung zu speichern (Presets), Zeitpläne für die Datenerfassung festzulegen und vieles mehr. Sie können die automatische Abfragevervielfachung, die Substitution von Unterabfragen aus Dateien, das Durchlaufen von alphanumerischen Kombinationen und Listen nutzen, um die maximal mögliche Anzahl an Ergebnissen bei der Datenerfassung von Yandex Wordstat zu erzielen.
Das Speichern der Ergebnisse ist in der von Ihnen benötigten Form und Struktur möglich, dank des integrierten leistungsstarken Template-Engines Template Toolkit, der es ermöglicht, zusätzliche Logik auf die Ergebnisse anzuwenden und Daten in verschiedenen Formaten auszugeben, einschließlich JSON, SQL und CSV.
Anwendungsbeispiele des Parsers
🔗 Wordstat-Datenerfassung in die Tiefe
Verwendung des Yandex WordStat Parsers für die Datenerfassung in die Tiefe.
🔗 Häufigkeitsbewertung nach WordStat
Häufigkeitsbewertung nach WordStat
Accounts
Für die Arbeit des Parsers  SE::Yandex::WordStat sind Yandex-Accounts erforderlich. Accounts können mit dem Parser
SE::Yandex::WordStat sind Yandex-Accounts erforderlich. Accounts können mit dem Parser  SE::Yandex::Register registriert oder einfach vorhandene Accounts zur Datei
SE::Yandex::Register registriert oder einfach vorhandene Accounts zur Datei files/SE-Yandex/accounts.txt im unterstützten Format hinzugefügt werden.
Alternativ kann die Registrierung von Accounts "on-the-fly" aktiviert werden.
Für die Arbeit mit der Autorisierung per Sitzung ist es erforderlich, dass die Datenzeile in diesem Format vorliegt:
[email protected];MAQT78Z31Rinx4H;{"answer":"qmfhsxdcrk","proxy":"185.104.120.45:3128","session_id":"3:1748440908.5.0.1748440867459:ZXBxpg:47e4.1.2:1|2191075974.41.2.2:41.3:1748440908|3:10308131.797655.5pfkoRZWgLJGntKTlcUhYdysNfk"}
Gesammelte Daten
- Anzahl der Impressionen für die angegebene Abfrage
- Datum der Statistikaktualisierung
- Liste aller mit der angegebenen Abfrage verknüpften Keywords und deren monatliche Impressionen
- Liste aller zusätzlichen Keywords, nach denen Nutzer gesucht haben, und deren monatliche Impressionen
Funktionen
- Extrahiert die von Wordstat maximal ausgegebene Anzahl an Ergebnissen - 40 Seiten mit je 50 Elementen
- Unterstützt die Auswahl der Suchregion (mit Untergruppen)
- Kann gefundene Keywords automatisch erneut als Abfragen einsetzen (Option Parse to level)
- Möglichkeit, mehrere Regionen gleichzeitig zur Bewertung auszuwählen
- Unterstützung für die automatische Umgehung von Smart Captcha und die Möglichkeit, grafische Captchas mit dem AntiCaptcha-Dienst oder einer anderen unterstützten API zu umgehen
- Auswahl des Gerätetyps
- Möglichkeit, die Autorisierungsmethode zu wählen
- Möglichkeit, Accounts "on-the-fly" zu registrieren
- Unterstützt die Arbeit mit dem erweiterten Account-Format und kann Sicherheitsfragen beantworten (wenn die Antwort in
info). Verwendet zudem den gespeicherten Proxy für die Autorisierung (falls ininfo).
Anwendungsfälle
- Bewertung des Traffic-Volumens pro Keyword (Häufigkeit)
- Suche nach neuen Schlüsselwörtern ähnlicher Thematik
- Erstellung großer Keyword-Datenbanken verschiedener Themen
- Alle anderen Varianten, die das Scraping von Yandex.WordStat in irgendeiner Form beinhalten
Abfragen
Als Abfragen müssen Schlüsselwörter angegeben werden, genau so, als ob sie direkt in das Suchformular von Wordstat eingegeben würden, zum Beispiel:
fenster moskau
"fenster moskau"
!fenster !moskau
Beispiele für die Ergebnisausgabe
A-Parser unterstützt eine flexible Formatierung der Ergebnisse dank des integrierten Template-Engines Template Toolkit, was die Ausgabe in beliebiger Form sowie in strukturierter Form wie CSV oder JSON ermöglicht
Standardausgabe
Ergebnisformat:
$query - $totalcount, updated: $updatedate\nkeywords:\n$keys.format('$key: $count\n')\nadditional keywords:\n$search.format('$key: $count\n')
Im Ergebnis werden die ursprüngliche Abfrage, die Anzahl ihrer Impressionen, das Datum der Statistikaktualisierung, die Liste der verwandten Keywords und deren monatliche Impressionen sowie die Liste der zusätzlichen Keywords und deren monatliche Impressionen angezeigt:
!fenster !moskau - 10368, updated: 16/05/2013
keywords:
fenster moskau: 32367
kunststofffenster moskau: 8994
pvc fenster moskau: 4813
fenster kaufen moskau: 2561
fenster preise moskau: 1706
moskau arbeit fenster: 1547
stellenangebote fenster moskau: 1187
holzfenster moskau: 1087
service +eines fensters moskau: 1021
...
additional keywords:
produktion von pvc fenstern: 8512
fenster rehau: 15686
fenster salamander: 1576
fenster kbe: 3798
fenster kbe: 6089
fenster kve: 3227
balkonverglasung: 83216
pavillons: 471213
loggiaverglasung: 26366
bürotrennwände: 18740
fenstermontage: 26223
Ausgabe in eine CSV-Tabelle
Ergebnisformat:
[% FOREACH i IN keys;
tools.CSVline(query, i. key, i.count);
END %]
Beispielergebnis:
website parser, website parser, 8055
website parser, kostenloser website parser, 1122
website parser, parser offizielle website, 666
website parser, websites cloud parser, 507
website parser, email parser +von website, 477
website parser, website parser download, 434
website parser, website adressen parser, 390
website parser, website parser online, 366
website parser, turbo website parser, 342
website parser, turbo parser offizielle website, 309
website parser, cloud parser offizielle website, 308
website parser, website parser excel, 276
website parser, sliza parser website, 259
Speichern im SQL-Format
Ergebnisformat:
[% FOREACH i IN keys;
"INSERT INTO keys VALUES('" _ query _ "', '"; i.key _ "', '"; i.count _ "')\n";
END %]
Beispielergebnis:
INSERT INTO serp VALUES('test', 'test', '10837937')
INSERT INTO serp VALUES('test', 'testdrive', '1164338')
INSERT INTO serp VALUES('test', 'teig +für test', '879980')
INSERT INTO serp VALUES('test', 'tests online', '792560')
INSERT INTO serp VALUES('test', 'testdrive video', '550164')
INSERT INTO serp VALUES('test', 'teigrezept', '484489')
INSERT INTO serp VALUES('test', 'tests +mit antworten', '449401')
INSERT INTO serp VALUES('test', 'test 2014', '427602')
INSERT INTO serp VALUES('test', 'tests kostenlos', '315144')
INSERT INTO serp VALUES('test', 'kostenlose tests', '315096')
INSERT INTO serp VALUES('test', 'tests +für mädchen', '309355')
INSERT INTO serp VALUES('test', 'tests +nach themen', '293917')
INSERT INTO serp VALUES('test', 'spiele tests', '288989')
Ergebnis-Dump in JSON
Allgemeines Ausgabeformat:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.updatedate = p1.updatedate;
obj.totalcount = p1.totalcount;
obj.keys = [];
FOREACH item IN p1.keys;
obj.keys.push({
key = item.key
count = item.count
});
END;
obj.json %]
Anfangstext:
[
Endtext:
]
Beispielergebnis:
[{
"updatedate": "12.03.2014",
"totalcount": "10837937",
"keys": [
{
"count": "10837937",
"key": "test"
},
{
"count": "1164338",
"key": "testdrive"
},
{
"count": "879980",
"key": "teig +für test"
},
{
"count": "792560",
"key": "tests online"
},
]
}]
Siehe auch: Ergebnisfilter
Mögliche Einstellungen
| Parameter | Standardwert | Beschreibung |
|---|---|---|
| Pages count | 10 | Anzahl der zu scrapenden Seiten |
| Region | All | Suchregion |
| Remove + from keywords | ☐ | Plus-Symbol (+) aus gefundenen Abfragen entfernen |
| AntiGate preset | default | Zuerst muss der Scraper  Util::AntiGate konfiguriert werden - geben Sie Ihren Zugriffsschlüssel und andere Parameter an und wählen Sie dann hier das erstellte Preset aus Util::AntiGate konfiguriert werden - geben Sie Ihren Zugriffsschlüssel und andere Parameter an und wählen Sie dann hier das erstellte Preset aus |
| AntiGate preset for Login | default | AntiGate-Preset für den Login. Zuerst muss der Scraper Util::AntiGate mit Parametern konfiguriert werden, und wählen Sie dann hier das erstellte Preset aus |
| Type | All | Auswahl des Gerätetyps |
| Accounts | Only from "accounts.txt" | Auswahl der Methode zur Arbeit mit Accounts: Always auto register - Accounts immer automatisch "on-the-fly" registrieren, erfordert die Auswahl eines konfigurierten Presets im Parameter SE::Yandex::Register preset. Auto register if no more in "accounts.txt" - zuerst werden vorhandene Accounts aus accounts.txt verwendet, und wenn diese aufgebraucht sind, wird die automatische Registrierung "on-the-fly" genutzt, wofür entsprechend ein konfiguriertes Preset im Parameter SE::Yandex::Register preset gewählt werden muss. Only from "accounts.txt" - nur vorhandene Accounts aus accounts.txt verwenden, und wenn diese aufgebraucht sind - die festgelegte Zeit warten (Parameter Wait new accounts in "accounts.txt"), bis neue erscheinen. Only by session_id from "accounts.txt" - Autorisierung über Cookies. |
| Wait new accounts in "accounts.txt" | 0 | Wartezeit auf das Erscheinen neuer Accounts in accounts.txt |
| Remove bad accounts | Always, except wrong login/password | Automatisches Löschen "schlechter" Accounts: Always - immer löschen. Always, except wrong login/password - immer löschen, außer wenn Yandex meldet, dass Login/Passwort falsch sind. Dies liegt daran, dass Yandex eine solche Meldung auch bei einer IP-Sperre für einen voll funktionsfähigen Account ausgeben kann, daher können solche Accounts optional zur Wiederverwendung behalten werden. Never - niemals löschen. Unabhängig von der gewählten Option werden Accounts bei Proxy-/Browserfehlern nicht gelöscht |
| SE::Yandex::Register preset | default | Auswahl des Einstellungs-Presets für SE::Yandex::Register |
| Authorization method | HTTP | Autorisierungsmethode: HTTP - schnell, ressourcensparend. Chrome - langsam, ressourcenintensiv, kann theoretisch die Lebensdauer von Accounts verlängern |
| Chrome headless | ☑ | Wenn diese Option aktiviert ist, wird der Browser nicht angezeigt |
| Use sessions | ☑ | Verwendung von Sitzungen |
| Do not reset session if authorization passed | ☑ | Sitzung bei Fehlern nicht zurücksetzen, wenn der Parser bereits autorisiert ist |
| Use Wordstat 2 | ☐ | Verwendung von Wordstat 2 |
| Wordstat 2 parse all table data | ☑ | Ermöglicht das sofortige Herunterladen aller 2000 Ergebnisse pro Abfrage, ohne die Paginierung zu durchlaufen |
