SE::Yandex::WordStat - Scraper WordStat. Raccolta di parole chiave e statistiche di visualizzazione
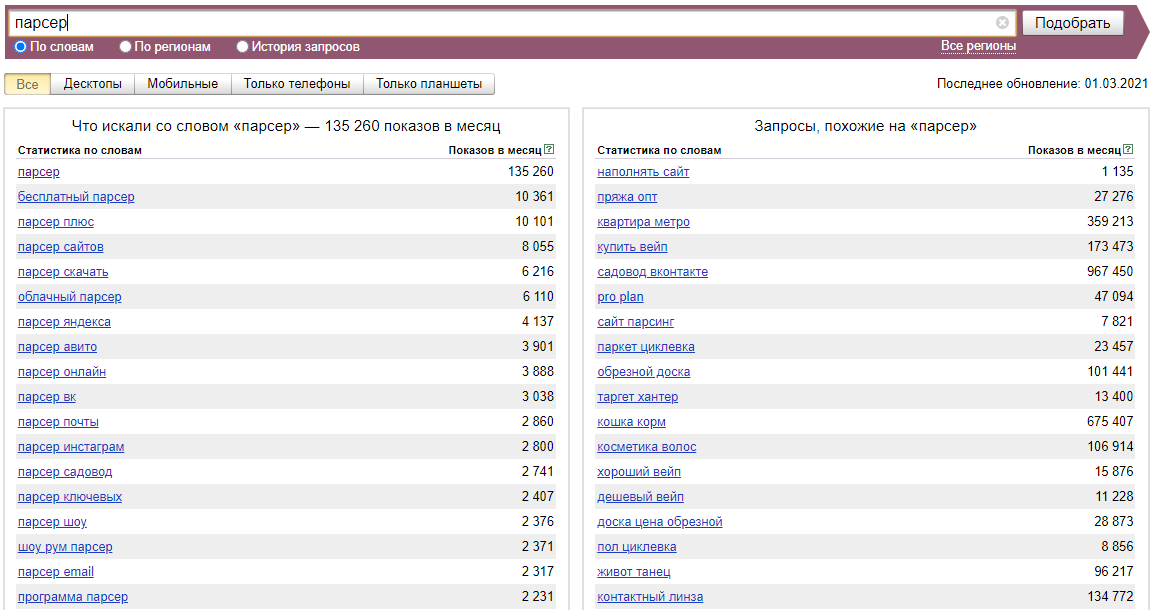
Panoramica dello scraper
Wordstat è un servizio di Yandex progettato per valutare l'interesse degli utenti per vari argomenti e selezionare parole chiave per l'ottimizzazione SEO e la pubblicità contestuale. Inoltre, con l'aiuto di Wordstat Yandex, è possibile valutare la stagionalità e la dipendenza geografica delle query di ricerca.
Lo scraper di parole chiave Yandex WordStat supporta la moltiplicazione automatica delle query, garantendo di ottenere il numero massimo di risultati dai dati forniti. Inoltre, A-Parser può navigare automaticamente attraverso le query correlate fino a una profondità specificata.
La funzionalità di A-Parser consente di salvare le impostazioni di scraping per un uso futuro (preset), impostare pianificazioni di scraping e molto altro. È possibile utilizzare la moltiplicazione automatica delle query, la sostituzione di sotto-query da file, la generazione di combinazioni alfanumeriche e liste per ottenere il massimo numero possibile di risultati durante lo scraping di Yandex Wordstat.
Il salvataggio dei risultati è possibile nella forma e nella struttura necessarie, grazie al potente motore di modelli integrato Template Toolkit che consente di applicare logica aggiuntiva ai risultati e di esportare dati in vari formati, inclusi JSON, SQL e CSV.
Casi d'uso dello scraper
🔗 Scraping Wordstat in profondità
Utilizzo dello scraper Yandex WordStat per lo scraping in profondità.
🔗 Valutazione della frequenza tramite WordStat
Valutazione della frequenza tramite WordStat
Account
Per il funzionamento dello scraper  SE::Yandex::WordStat sono necessari account Yandex. Gli account possono essere registrati utilizzando lo scraper
SE::Yandex::WordStat sono necessari account Yandex. Gli account possono essere registrati utilizzando lo scraper  SE::Yandex::Register o semplicemente aggiungendo gli account esistenti al file
SE::Yandex::Register o semplicemente aggiungendo gli account esistenti al file files/SE-Yandex/accounts.txt nel formato supportato.
In alternativa, è possibile abilitare la registrazione degli account "al volo".
Per lavorare utilizzando l'autorizzazione tramite sessione, è necessario che la stringa con i dati sia in questo formato:
[email protected];MAQT78Z31Rinx4H;{"answer":"qmfhsxdcrk","proxy":"185.104.120.45:3128","session_id":"3:1748440908.5.0.1748440867459:ZXBxpg:47e4.1.2:1|2191075974.41.2.2:41.3:1748440908|3:10308131.797655.5pfkoRZWgLJGntKTlcUhYdysNfk"}
Dati raccolti
- Numero di visualizzazioni per la query specificata
- Data di aggiornamento delle statistiche
- Elenco di tutte le parole chiave correlate a quella specificata e il loro numero di visualizzazioni mensili
- Elenco di tutte le parole chiave aggiuntive cercate dagli utenti e il loro numero di visualizzazioni mensili
Funzionalità
- Scraper del numero massimo di risultati forniti da Wordstat - 40 pagine con 50 elementi per pagina
- Supporta la selezione della regione di ricerca (with subgroups)
- Può inserire automaticamente le parole chiave trovate nuovamente nelle query (opzione Parse to level)
- Possibilità di selezionare più regioni contemporaneamente per la valutazione
- Supporto per il superamento automatico di Smart captcha e possibilità di superare captcha grafici utilizzando il servizio AntiCaptcha o qualsiasi altro che supporti le loro API
- Selezione del tipo di dispositivo
- Possibilità di scegliere il metodo di autorizzazione
- Possibilità di registrare account "al volo"
- Supporta il lavoro con il formato esteso degli account e sa rispondere alla domanda segreta (se la risposta è presente in
info). Inoltre, utilizza un proxy salvato per l'autorizzazione (se presente ininfo).
Varianti di utilizzo
- Valutazione del volume di traffico per parola chiave (frequenza)
- Ricerca di nuove parole chiave di argomenti simili
- Raccolta di grandi database di parole chiave di vari argomenti
- Qualsiasi altra variante che implichi lo scraping di Yandex.WordStat in un modo o nell'altro
Query
Come query, è necessario specificare le parole chiave, esattamente come se venissero inserite direttamente nel modulo di ricerca di Wordstat, ad esempio:
okna moskva
"okna moskva"
!okna !moskva
Varianti di output dei risultati
A-Parser supporta la formattazione flessibile dei risultati grazie al motore di modelli integrato Template Toolkit, che gli consente di produrre risultati in forma arbitraria, così come in forma strutturata, ad esempio CSV o JSON
Output predefinito
Formato del risultato:
$query - $totalcount, updated: $updatedate\nkeywords:\n$keys.format('$key: $count\n')\nadditional keywords:\n$search.format('$key: $count\n')
Il risultato mostra la query originale, il numero delle sue visualizzazioni, la data di aggiornamento delle statistiche, l'elenco delle parole chiave correlate e le loro visualizzazioni mensili, l'elenco delle parole chiave aggiuntive e le loro visualizzazioni mensili:
!okna !moskva - 10368, updated: 16/05/2013
keywords:
okna moskva: 32367
plastikovye okna moskva: 8994
okna pvkh moskva: 4813
kupit' okna moskva: 2561
okna tseny moskva: 1706
moskva rabota okna: 1547
vakansii okna moskva: 1187
derevyannye okna moskva: 1087
sluzhba +odnogo okna moskva: 1021
...
additional keywords:
proizvodstvo okon pvkh: 8512
okna rehau: 15686
okna salamander: 1576
okna kbe: 3798
okna kbe: 6089
okna kve: 3227
osteklenie balkonov: 83216
besedki: 471213
osteklenie lodzhiy: 26366
ofisnye peregorodki: 18740
montazh okon: 26223
Output in tabella CSV
Formato del risultato:
[% FOREACH i IN keys;
tools.CSVline(query, i. key, i.count);
END %]
Esempio di risultato:
scraper di siti, scraper di siti, 8055
scraper di siti, scraper di siti gratuito, 1122
scraper di siti, sito ufficiale scraper, 666
scraper di siti, siti cloud scraper, 507
scraper di siti, scraper email +dal sito, 477
scraper di siti, scaricare scraper sito, 434
scraper di siti, scraper indirizzi siti, 390
scraper di siti, scraper di siti online, 366
scraper di siti, turbo scraper di siti, 342
scraper di siti, turbo scraper sito ufficiale, 309
scraper di siti, cloud scraper sito ufficiale, 308
scraper di siti, scraper di siti excel, 276
scraper di siti, sliza scraper sito, 259
Salvataggio in formato SQL
Formato del risultato:
[% FOREACH i IN keys;
"INSERT INTO keys VALUES('" _ query _ "', '"; i.key _ "', '"; i.count _ "')\n";
END %]
Esempio di risultato:
INSERT INTO serp VALUES('test', 'test', '10837937')
INSERT INTO serp VALUES('test', 'test drive', '1164338')
INSERT INTO serp VALUES('test', 'impasto +per test', '879980')
INSERT INTO serp VALUES('test', 'test online', '792560')
INSERT INTO serp VALUES('test', 'video test drive', '550164')
INSERT INTO serp VALUES('test', 'ricetta impasto', '484489')
INSERT INTO serp VALUES('test', 'test +con risposte', '449401')
INSERT INTO serp VALUES('test', 'test 2014', '427602')
INSERT INTO serp VALUES('test', 'test gratis', '315144')
INSERT INTO serp VALUES('test', 'test gratuiti', '315096')
INSERT INTO serp VALUES('test', 'test +per ragazze', '309355')
INSERT INTO serp VALUES('test', 'test +per argomenti', '293917')
INSERT INTO serp VALUES('test', 'giochi test', '288989')
Dump dei risultati in JSON
Formato comune del risultato:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.updatedate = p1.updatedate;
obj.totalcount = p1.totalcount;
obj.keys = [];
FOREACH item IN p1.keys;
obj.keys.push({
key = item.key
count = item.count
});
END;
obj.json %]
Testo iniziale:
[
Testo finale:
]
Esempio di risultato:
[{
"updatedate": "12.03.2014",
"totalcount": "10837937",
"keys": [
{
"count": "10837937",
"key": "test"
},
{
"count": "1164338",
"key": "test drive"
},
{
"count": "879980",
"key": "impasto +per test"
},
{
"count": "792560",
"key": "test online"
},
]
}]
Vedi anche: Filtri dei risultati
Impostazioni possibili
| Parametro | Valore predefinito | Descrizione |
|---|---|---|
| Pages count | 10 | Numero di pagine da sottoporre a scraping |
| Region | All | Regione di ricerca |
| Remove + from keywords | ☐ | Rimuovere il simbolo più (+) dalle query trovate |
| AntiGate preset | default | È necessario configurare preventivamente lo scraper  Util::AntiGate - indicare la propria chiave di accesso e altri parametri, quindi selezionare il preset creato qui Util::AntiGate - indicare la propria chiave di accesso e altri parametri, quindi selezionare il preset creato qui |
| AntiGate preset for Login | default | Preset AntiGate per il login. È necessario configurare preventivamente lo scraper Util::AntiGate con i parametri, quindi selezionare il preset creato qui |
| Type | All | Selezione del tipo di dispositivo |
| Accounts | Only from "accounts.txt" | Scelta del metodo di lavoro con gli account: Always auto register - registra sempre automaticamente gli account "al volo", è necessario selezionare un preset configurato nel parametro SE::Yandex::Register preset. Auto register if no more in "accounts.txt" - vengono prima utilizzati gli account esistenti da accounts.txt, e se terminano viene utilizzata la registrazione automatica "al volo", per la quale è necessario selezionare un preset configurato nel parametro SE::Yandex::Register preset. Only from "accounts.txt" - utilizza solo account esistenti da accounts.txt, e se terminano aspetta il tempo specificato (parametro Wait new accounts in "accounts.txt") per la comparsa di nuovi. Only by session_id from "accounts.txt" - autorizzazione tramite cookie. |
| Wait new accounts in "accounts.txt" | 0 | Tempo di attesa per la comparsa di nuovi account in accounts.txt |
| Remove bad accounts | Always, except wrong login/password | Rimozione automatica degli account "cattivi": Always - rimuovi sempre. Always, except wrong login/password - rimuovi sempre, tranne quando Yandex segnala che sono stati inseriti login/password errati. Il fatto è che Yandex può restituire tale messaggio in caso di ban dell'IP per un account perfettamente funzionante, quindi opzionalmente è possibile lasciare tali account per un riutilizzo. Never - non rimuovere mai. Indipendentemente dall'opzione scelta, in caso di errori di proxy/browser gli account non vengono rimossi |
| SE::Yandex::Register preset | default | Selezione del preset di impostazioni per SE::Yandex::Register |
| Authorization method | HTTP | Metodo di autorizzazione: HTTP - veloce, non richiede molte risorse. Chrome - lento, richiede molte risorse, teoricamente può prolungare la vita degli account |
| Chrome headless | ☑ | Se l'opzione è abilitata, il browser non verrà visualizzato |
| Use sessions | ☑ | Utilizzo delle sessioni |
| Do not reset session if authorization passed | ☑ | Non resettare la sessione in caso di errori se lo scraper è già autorizzato |
| Use Wordstat 2 | ☐ | Utilizzo di Wordstat 2 |
| Wordstat 2 parse all table data | ☑ | Consente di scaricare immediatamente tutti i 2000 risultati per query senza passare per la paginazione |
