SE::Yandex::WordStat - Scraper Wordstat. Zbieranie słów kluczowych i statystyk wyszukiwań
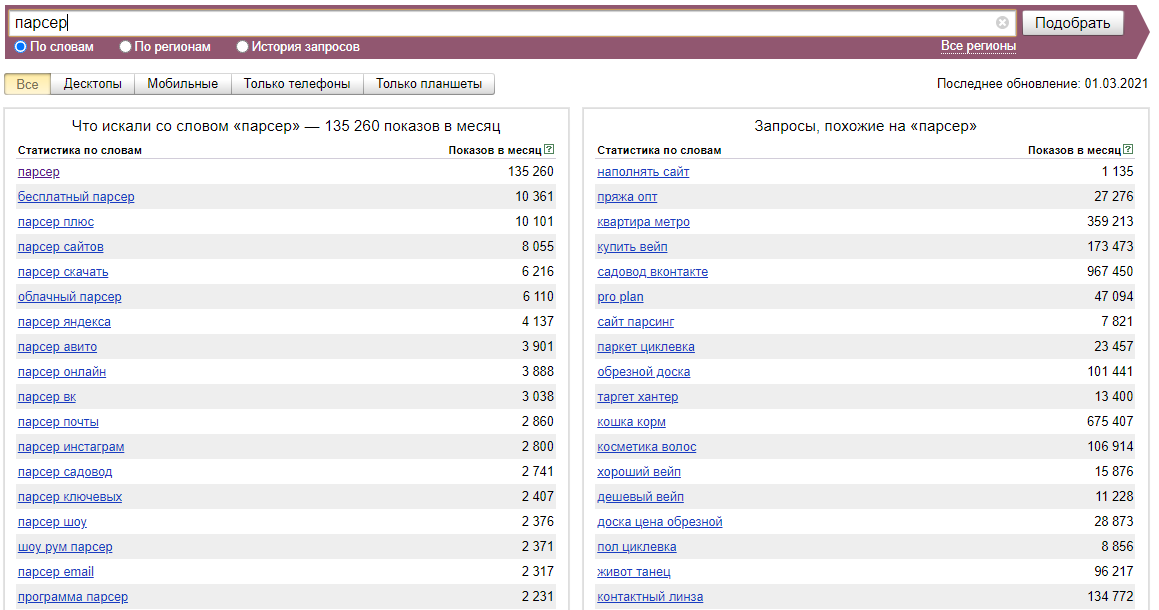
Przegląd scrapera
Wordstat to usługa firmy Yandex, przeznaczona do oceny zainteresowania użytkowników różnymi tematami oraz doboru słów kluczowych dla optymalizacji SEO i reklamy kontekstowej. Ponadto, za pomocą Wordstat Yandex można ocenić sezonowość i zależność geograficzną zapytań wyszukiwania.
Scraper słów kluczowych Yandex WordStat obsługuje automatyczne powielanie zapytań, dzięki czemu możesz mieć pewność, że otrzymasz maksymalną liczbę wyników z wyników wyszukiwania. Ponadto A-Parser może automatycznie przechodzić przez powiązane zapytania na określoną głębokość.
Funkcjonalność A-Parser pozwala na zapisywanie ustawień scrapowania do późniejszego wykorzystania (presety), ustalanie harmonogramu scrapowania i wiele więcej. Możesz korzystać z automatycznego powielania zapytań, podstawiania podzapytań z plików, iteracji kombinacji alfanumerycznych i list, aby uzyskać maksymalną możliwą liczbę wyników podczas scrapowania Yandex Wordstat.
Zapisywanie wyników jest możliwe w dowolnej formie i strukturze, której potrzebujesz, dzięki wbudowanemu potężnemu silnikowi szablonów Template Toolkit, który pozwala na stosowanie dodatkowej logiki do wyników i wyprowadzanie danych w różnych formatach, w tym JSON, SQL i CSV.
Przypadki użycia scrapera
🔗 Scrapowanie Wordstat w głąb
Wykorzystanie scrapera Yandex WordStat do scrapowania w głąb.
🔗 Ocena częstotliwości według WordStat
Ocena częstotliwości według WordStat
Konta
Do działania scrapera  SE::Yandex::WordStat wymagane są konta Yandex. Konta można zarejestrować za pomocą scrapera
SE::Yandex::WordStat wymagane są konta Yandex. Konta można zarejestrować za pomocą scrapera  SE::Yandex::Register lub po prostu dodać istniejące konta do pliku
SE::Yandex::Register lub po prostu dodać istniejące konta do pliku files/SE-Yandex/accounts.txt w obsługiwanym formacie.
Można również włączyć rejestrację kont "w locie".
Aby korzystać z autoryzacji sesyjnej, ciąg danych musi być w następującym formacie:
[email protected];MAQT78Z31Rinx4H;{"answer":"qmfhsxdcrk","proxy":"185.104.120.45:3128","session_id":"3:1748440908.5.0.1748440867459:ZXBxpg:47e4.1.2:1|2191075974.41.2.2:41.3:1748440908|3:10308131.797655.5pfkoRZWgLJGntKTlcUhYdysNfk"}
Zbierane dane
- Liczba wyświetleń dla określonego zapytania
- Data aktualizacji statystyk
- Lista wszystkich słów kluczowych powiązanych z podanym oraz liczba ich wyświetleń miesięcznie
- Lista wszystkich dodatkowych słów kluczowych, których szukali użytkownicy, oraz liczba ich wyświetleń miesięcznie
Możliwości
- Scrapuje maksymalną liczbę wyników udostępnianą przez Wordstat - 40 stron po 50 elementów wyników
- Obsługuje wybór regionu wyszukiwania (z podgrupami)
- Może automatycznie podstawiać znalezione słowa kluczowe ponownie do zapytań (opcja Parse to level)
- Możliwość wyboru wielu regionów jednocześnie do oceny
- Wsparcie dla automatycznego omijania Smart captcha oraz możliwość omijania captcha graficznej za pomocą serwisu AntiCaptcha lub dowolnego innego obsługującego ich API
- Wybór typu urządzenia
- Możliwość wyboru metody autoryzacji
- Możliwość rejestracji kont "w locie"
- Obsługuje pracę z rozszerzonym formatem kont i potrafi odpowiadać na pytanie pomocnicze (jeśli odpowiedź znajduje się w
info). Wykorzystuje również zapisane proxy do autoryzacji (jeśli znajduje się winfo).
Zastosowania
- Ocena ilości ruchu dla słowa kluczowego (częstotliwość)
- Wyszukiwanie nowych słów kluczowych o podobnej tematyce
- Budowanie dużych baz słów kluczowych o różnej tematyce
- Wszelkie inne warianty zakładające scrapowanie Yandex.WordStat w tej czy innej formie
Zapytania
Jako zapytania należy podawać słowa kluczowe, dokładnie tak samo, jak gdyby były wpisywane bezpośrednio w formularzu wyszukiwania Wordstat, na przykład:
okna warszawa
"okna warszawa"
!okna !warszawa
Warianty wyprowadzania wyników
A-Parser obsługuje elastyczne formatowanie wyników dzięki wbudowanemu silnikowi szablonów Template Toolkit, co pozwala mu na wyprowadzanie wyników w dowolnej formie, a także w formie ustrukturyzowanej, na przykład CSV lub JSON
Wynik domyślny
Format wyniku:
$query - $totalcount, updated: $updatedate\nkeywords:\n$keys.format('$key: $count\n')\nadditional keywords:\n$search.format('$key: $count\n')
W wyniku wyświetlane jest zapytanie źródłowe, liczba jego wyświetleń, data aktualizacji statystyk, lista powiązanych słów kluczowych i ich wyświetlenia miesięcznie, lista dodatkowych słów kluczowych i ich wyświetlenia miesięcznie:
!okna !moskwa - 10368, updated: 16/05/2013
keywords:
okna moskwa: 32367
okna plastikowe moskwa: 8994
okna pcv moskwa: 4813
kupić okna moskwa: 2561
okna ceny moskwa: 1706
moskwa praca okna: 1547
oferty pracy okna moskwa: 1187
okna drewniane moskwa: 1087
biuro +jednego okienka moskwa: 1021
...
additional keywords:
produkcja okien pcv: 8512
okna rehau: 15686
okna salamander: 1576
okna kbe: 3798
okna kbe: 6089
okna kve: 3227
przeszklenia balkonów: 83216
altany: 471213
przeszklenia loggii: 26366
ścianki biurowe: 18740
montaż okien: 26223
Wynik w tabeli CSV
Format wyniku:
[% FOREACH i IN keys;
tools.CSVline(query, i. key, i.count);
END %]
Przykład wyniku:
scraper stron, scraper stron, 8055
scraper stron, darmowy scraper stron, 1122
scraper stron, scraper oficjalna strona, 666
scraper stron, strony scraper chmurowy, 507
scraper stron, scraper email +ze strony, 477
scraper stron, scraper strony pobierz, 434
scraper stron, scraper adresów stron, 390
scraper stron, scraper stron online, 366
scraper stron, turbo scraper stron, 342
scraper stron, turbo scraper oficjalna strona, 309
scraper stron, scraper chmurowy oficjalna strona, 308
scraper stron, scraper stron excel, 276
scraper stron, sliza scraper strona, 259
Zapisywanie w formacie SQL
Format wyniku:
[% FOREACH i IN keys;
"INSERT INTO keys VALUES('" _ query _ "', '"; i.key _ "', '"; i.count _ "')\n";
END %]
Przykład wyniku:
INSERT INTO serp VALUES('test', 'test', '10837937')
INSERT INTO serp VALUES('test', 'test drive', '1164338')
INSERT INTO serp VALUES('test', 'ciasto +do testu', '879980')
INSERT INTO serp VALUES('test', 'testy online', '792560')
INSERT INTO serp VALUES('test', 'test drive wideo', '550164')
INSERT INTO serp VALUES('test', 'przepis na ciasto', '484489')
INSERT INTO serp VALUES('test', 'testy +z odpowiedziami', '449401')
INSERT INTO serp VALUES('test', 'test 2014', '427602')
INSERT INTO serp VALUES('test', 'testy za darmo', '315144')
INSERT INTO serp VALUES('test', 'darmowe testy', '315096')
INSERT INTO serp VALUES('test', 'testy +dla dziewczyn', '309355')
INSERT INTO serp VALUES('test', 'testy +według tematów', '293917')
INSERT INTO serp VALUES('test', 'gry testy', '288989')
Zrzut wyników do JSON
Ogólny format wyniku:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.updatedate = p1.updatedate;
obj.totalcount = p1.totalcount;
obj.keys = [];
FOREACH item IN p1.keys;
obj.keys.push({
key = item.key
count = item.count
});
END;
obj.json %]
Tekst początkowy:
[
Tekst końcowy:
]
Przykład wyniku:
[{
"updatedate": "12.03.2014",
"totalcount": "10837937",
"keys": [
{
"count": "10837937",
"key": "test"
},
{
"count": "1164338",
"key": "test drive"
},
{
"count": "879980",
"key": "ciasto +do testu"
},
{
"count": "792560",
"key": "testy online"
},
]
}]
Zobacz również: Filtry wyników
Możliwe ustawienia
| Parametr | Wartość domyślna | Opis |
|---|---|---|
| Pages count | 10 | Liczba stron do scrapowania |
| Region | All | Region wyszukiwania |
| Remove + from keywords | ☐ | Usuń symbol plusa (+) ze znalezionych zapytań |
| AntiGate preset | default | Należy wcześniej skonfigurować scraper  Util::AntiGate - podać swój klucz dostępu i inne parametry, a następnie wybrać utworzony preset tutaj Util::AntiGate - podać swój klucz dostępu i inne parametry, a następnie wybrać utworzony preset tutaj |
| AntiGate preset for Login | default | Preset AntiGate dla logowania. Należy wcześniej skonfigurować scraper Util::AntiGate z parametrami, a następnie wybrać utworzony preset tutaj |
| Type | All | Wybór typu urządzenia |
| Accounts | Only from "accounts.txt" | Wybór metody pracy z kontami: Always auto register - zawsze automatycznie rejestruj konta "w locie", wymaga wybrania skonfigurowanego presetu w parametrze SE::Yandex::Register preset. Auto register if no more in "accounts.txt" - najpierw używane są istniejące konta z accounts.txt, a jeśli się skończą - używana jest automatyczna rejestracja "w locie", dla której należy wybrać skonfigurowany preset w parametrze SE::Yandex::Register preset. Only from "accounts.txt" - używaj tylko istniejących kont z accounts.txt, a jeśli się skończą - czekaj określony czas (parametr Wait new accounts in "accounts.txt") na pojawienie się nowych. Only by session_id from "accounts.txt" - autoryzacja przez ciasteczka. |
| Wait new accounts in "accounts.txt" | 0 | Czas oczekiwania na nowe konta w accounts.txt |
| Remove bad accounts | Always, except wrong login/password | Automatyczne usuwanie "złych" kont: Always - zawsze usuwaj. Always, except wrong login/password - usuwaj zawsze, z wyjątkiem sytuacji, gdy Yandex poinformował o błędnym loginie/haśle. Wynika to z faktu, że taki komunikat Yandex może wyświetlać przy blokadzie IP dla całkowicie sprawnego konta, dlatego opcjonalnie można zostawić takie konta do ponownego użycia. Never - nigdy nie usuwaj. Niezależnie od wybranej opcji, konta nie są usuwane przy błędach proxy/przeglądarki |
| SE::Yandex::Register preset | default | Wybór presetu ustawień dla SE::Yandex::Register |
| Authorization method | HTTP | Metoda autoryzacji: HTTP - szybko, mało wymagające zasobowo. Chrome - wolno, wymagające zasobowo, teoretycznie może przedłużać żywotność kont |
| Chrome headless | ☑ | Jeśli opcja jest włączona, przeglądarka nie będzie wyświetlana |
| Use sessions | ☑ | Użycie sesji |
| Do not reset session if authorization passed | ☑ | Nie resetuj sesji przy błędach, jeśli scraper już się autoryzował |
| Use Wordstat 2 | ☐ | Użycie Wordstat 2 |
| Wordstat 2 parse all table data | ☑ | Pozwala na natychmiastowe pobranie wszystkich 2000 wyników dla zapytania bez przechodzenia przez paginację |
