HTML::LinkExtractor - 指定したサイトの外部リンクおよび内部リンク用スクレイパー
スクレイパーの概要
 HTML::LinkExtractor – 指定されたサイトから外部および内部リンクを抽出するスクレイパーです。マルチページスクレイピングと、指定した深さまでのサイト内ページ遷移をサポートしており、サイトの全ページを巡回して内部および外部リンクを収集できます。内蔵の CloudFlare 回避機能や、スクリプトでデータが読み込まれるページからリンクを抽出するためのエンジンとして Chrome を選択する機能も備えています。最大で 2000 リクエスト/分の速度を出すことができ、これは 1時間あたり 120,000 リンクに相当します。
HTML::LinkExtractor – 指定されたサイトから外部および内部リンクを抽出するスクレイパーです。マルチページスクレイピングと、指定した深さまでのサイト内ページ遷移をサポートしており、サイトの全ページを巡回して内部および外部リンクを収集できます。内蔵の CloudFlare 回避機能や、スクリプトでデータが読み込まれるページからリンクを抽出するためのエンジンとして Chrome を選択する機能も備えています。最大で 2000 リクエスト/分の速度を出すことができ、これは 1時間あたり 120,000 リンクに相当します。スクレイパーの活用事例
サイトからすべての外部リンクを収集する
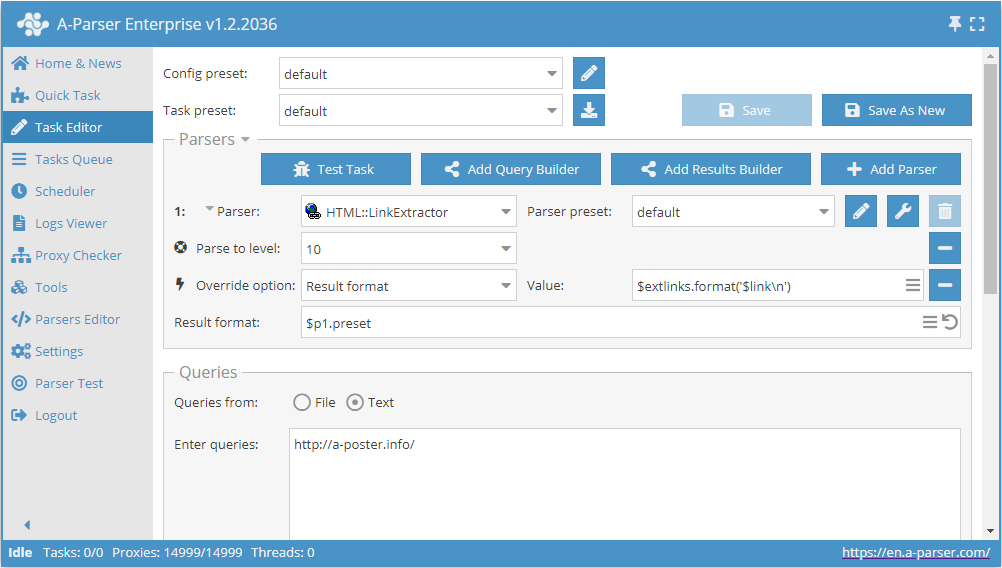
- Parse to level (指定レベルまでスクレイピング) オプションを追加し、リストから
10(10階層目までの隣接ページへの遷移) を選択します。 - Result format オプションを追加し、値として
$extlinks.format('$link\n')(外部リンクの出力) を指定します。 - Queries (クエリ) セクションで、
Unique queriesオプションにチェックを入れます。 - Results (結果) セクションで、
Unique stringオプションにチェックを入れます。 - クエリとして、外部リンクをスクレイピングしたいサイトのURLを指定します。
サンプルをダウンロード
eJxtU01v2zAM/S9CgK5AlrSHXnxLgwZb4dZdm57SHISYztTIoirRWQrD/32U7NjJ
1ptIvsfHL9WCpN/5JwceyItkVQsb3yIRORSy0iTGwkrnwYXwSvxYPqRJkiqzuzuQ
kxtCx4geWwv6tMBstKTQeI6pnM2YIoU9aPbspa4Yc33VnOD34JzK4Ugo0JWSuJa2
hI4iRnAgzeJ+0gK+XYyC+fZmLi5Fs16PRUvxixgODHs96Xrqgy9yD0sMKkrD4F6w
9SjLqJNLghA96lxO6BAyyDxXoTOpW4UwlUH11aiPWKcnp8yW8Ww6BX7hsGQ3QUwS
nJ/HCldiFG3BaarI/9VyREKugrHwXO1Cci15Hyik9hxRBE7yBrJu2Ekt0My0joMe
YDH9baV0zlucFUz62RG/hmT/5Wj6Dk+leGV/HNfQZ4nWbfYwsHJMccuNG+S2tSoV
se3nWJmwmyt27gBsP7bHACvRQS/TZe7U+VAtmHAfw9ZmdnCdtXG2mXPnBk2htll3
c0dkZZb8GzIzx9JqCH2ZSmveiofn4UJmvltDMIYC/yXPo8TZPyJE7e9f2lKtU3yB
N6HAkid5qtql3EitX5/T04gYLoqN30Q2mU7ld4ueFzpRpsCpCESCLfJFcVvNuv+/
/S+vv/zFSd3wwt79U4sO3QUs+3hMnrfBP7b5C6wbebo=
ヒント
サイトからすべての内部リンクを収集する
最初のケースと同様ですが、ステップ2で値として $intlinks.format('$link\n') (内部リンクの出力) を指定する必要があります。
サンプルをダウンロード
eJxtU8tu2zAQ/BfCQBrAtZNDL7o5Roy2cOI0j5PjA2GtXNYUyZIrN4Ggf++QkiW7
zY27O7OzL9aCZdiHB0+BOIhsXQuX3iITORWy0izGwkkfyMfwWnx9vltm2VKZ/e0b
e7ll64HosbXgd0dgW8fKmoCYymGmFEs6kIbnIHUFzPVVc4I/kPcqpyOhsL6UjFra
EjqKGCnDGuJh0gI+XYyi+fpqLi5Fs9mMRUsJixSODHc96Xrqg0/yQM82qihNg3sB
616WSSeXTDF61Lmc8FvMIPNcxc6kbhXiVAbVF6N+pzoDe2V2wMP0isLC2xJuppQk
Ot+PFa7FKNkCaarE/9FyRMa+orEIqHYhUUveBwqpAyKKyUtsYNUNO6uFNTOt06AH
WEp/UymdY4uzAqRvHfFjyOq/HE3f4akUVvbHo4Y+S7JuVncDK7dLu0PjxqJtrUrF
sMPcVibu5grOPZHrx3YfYaX11Mt0mTt1HKojE+9j2NrMDa6zNs42c+7cWlOo3aq7
uSOyMs/4DSszt6XTFPsyldbYSqDH4UJmoVtDNIYC/yXPk8TZP2Jrdfj+1JbqvMIF
fokFlpjkqWqXciu1fnlcnkbEcFEwfjK7bDqVn50NWOhEmcJORSQy7SwuCm01m/7/
9r+8/vAXZ3WDhf0KDy06dhex8GFMAdvAj23+ApcrebQ=
「forum」という単語を含まないリンクのみを辿る
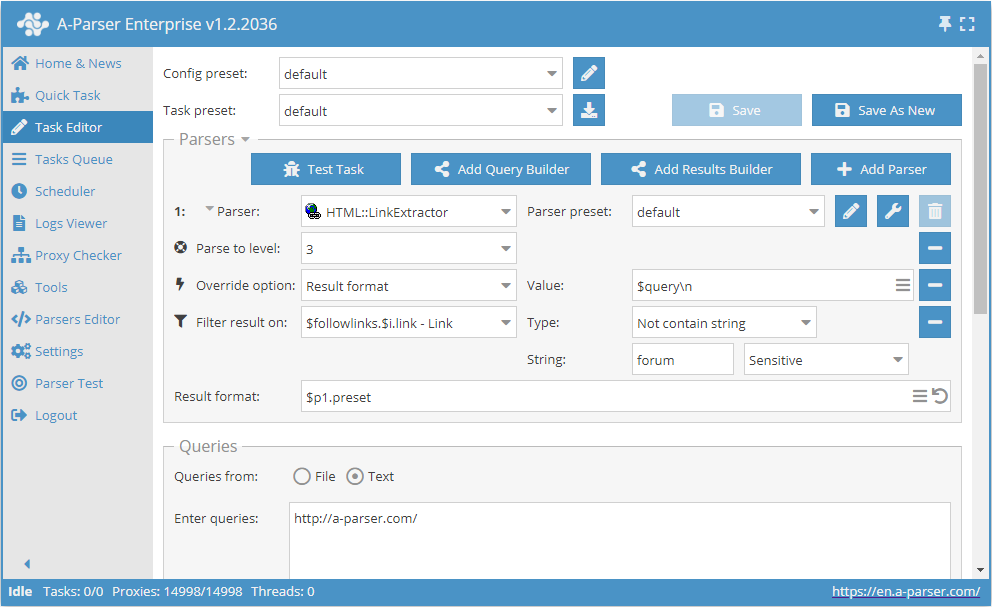
- Parse to level (指定レベルまでスクレイピング) オプションを追加し、リストから
3(3階層目までの隣接ページへの遷移) を選択します。 - Result format オプションを追加し、値として
$queryを指定します。 - フィルタを追加します。
$followlinks.$i.link - Linkでフィルタリングし、タイプはNot contain stringを選択し、文字列としてforumを指定します。 - Queries (クエリ) セクションで、
Unique queriesオプションにチェックを入れます。 - Results (結果) セクションで、
Unique stringオプションにチェックを入れます。 - クエリとして、リンクをスクレイピングしたいサイトのURLを指定します。
サンプルをダウンロード
eJxtVE1v2zAM/S/CDhuQJS2GXXxLgwbd4DZdm57SHISYzrTIkipRaQvD/33UR2xn
6ykh+R75+CG3DLk7uHsLDtCxYtMyE/+zglVQcy+RTZjh1oEN4Q27Wd+WRVEKdbh+
Q8t3qC0hemzL8N0AsbVBoZWjmKjIjClKOIIkz5FLT5hv3Qh+BGtFBSd8rW3DkaQk
BZnBPr14sO/Pz4qNuLWQCEFFhhcbokupXyWpDArCL9tOMnCdWErjTivkQo3yU1nf
kJ3Uk8MB9dBtt6fkbhmFBSnmcppn1Qcf+RHWOkmCwb0k6443sYGKI4ToNHX4+csU
30IGXlUi1OQyVQjTHqo+KfESBTq0Qu0JHwYhwC2tbsiNEJPE6ZwUbvK0Quc+8n8l
DivQepgwR2qXnLRUfaDm0lFE0Jg4bXaVl1i0TKu5lHGBAyymv/JCVnQd85pIPzLx
Y8jqvxxd3+G4FN3CqyUNfZZoXa1uB1alS72PW4z7bQSS7Rbaq7CbC3IeAEw/trsA
a7SFvkzOnKvTAzCgwuENW5ubwXXWxtlmzp10UbXYr/Ixn5BeremVrdRCN0ZC6Et5
KWkrDh6GC5m7vIZgDAL/JS9iibP3iVpL9/MxSTVW0AV+DwIbmuS4ak6541I+PZTj
CBsuiozfiKaYzfjX9PCnO93MWOAh7DUdFHXVbfvPQv/xaD/8OBRtR/v64+4TOjQX
sOSjKbn4yi67v8azl7c=
ヒント
収集されるデータ
- 外部リンク数
- 内部リンク数
- 外部リンク:
- リンク自体
- アンカーテキスト
- HTMLタグを除去したアンカーテキスト
- nofollowパラメータ
<a>タグ全体
- 内部リンク:
- リンク自体
- アンカーテキスト
- HTMLタグを除去したアンカーテキスト
- nofollowパラメータ
<a>タグ全体
- 収集されたすべてのページの配列 (Use Pages オプション使用時に利用)
機能
- マルチページスクレイピング(ページ遷移)
- 指定した深さまでのサイト内ページ遷移(Parse to levelオプション) – サイトの全ページを巡回し、内部および外部リンクを収集可能
- ページ遷移制限(Follow links limitオプション)
- アンカーテキストからのHTMLタグ自動除去
- 各リンクのnofollow判定
- サブドメインを内部ページとして扱うかどうかの指定
- gzip/deflate/brotli 圧縮をサポート
- サイトの文字コードを判定し UTF-8 に変換
- CloudFlare保護の回避
- エンジンの選択(HTTPまたはChrome)
ユースケース
- 完全なサイトマップの取得(すべての内部リンクの保存)
- サイトからのすべての外部リンクの取得
- 自サイトへのバックリンクの確認
クエリ
クエリには、リンクを収集したいページのURL、または Parse to level オプションを使用する場合はエントリポイント(例:サイトのトップページ)を指定する必要があります:
https://lenta.ru/
https://a-parser.com/wiki/index/
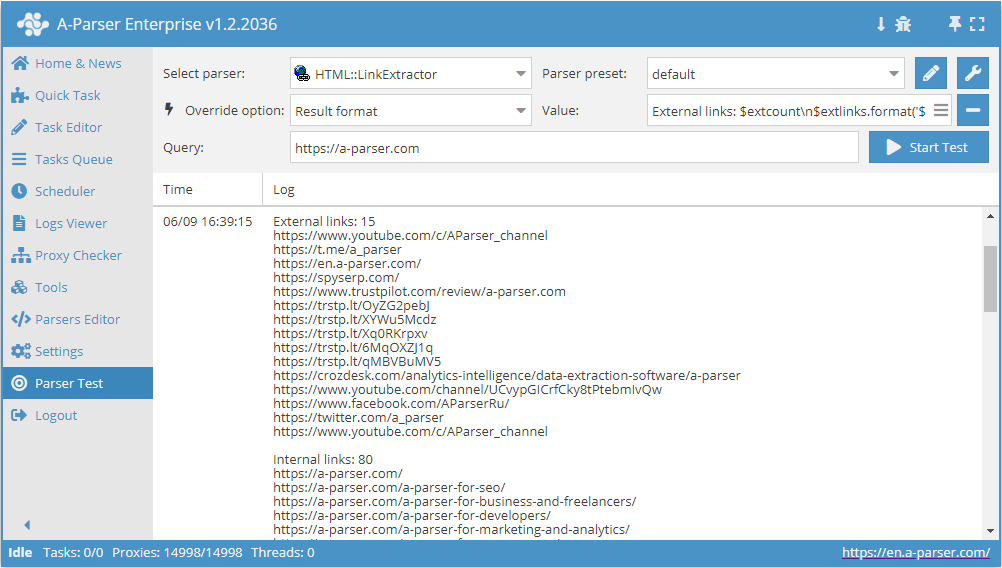
結果出力例
A-Parserは内蔵のテンプレートエンジン Template Toolkit により柔軟な結果フォーマットをサポートしており、任意の形式やCSV、JSONなどの構造化データで結果を出力できます。
外部リンクと内部リンクをそれぞれの件数とともに出力
結果フォーマット:
External links: $extcount\n$extlinks.format('$link\n')
Internal links: $intcount\n$intlinks.format('$link\n')
結果の例:
External links: 12
https://www.youtube.com/c/AParser_channel
https://t.me/a_parser
https://en.a-parser.com/
https://spyserp.com/ru/
https://sitechecker.pro/
https://arsenkin.ru/tools/
https://spyserp.com/
http://www.promkaskad.ru/
https://www.youtube.com/channel/UCvypGICrfCky8tPtebmIvQw
https://www.facebook.com/AParserRu
https://twitter.com/a_parser
https://www.youtube.com/c/AParser_channel
Internal links: 129
https://a-parser.com/
https://a-parser.com/
https://a-parser.com/a-parser-for-seo/
https://a-parser.com/a-parser-for-business-and-freelancers/
https://a-parser.com/a-parser-for-developers/
https://a-parser.com/a-parser-for-marketing-and-analytics/
https://a-parser.com/a-parser-for-e-commerce/
https://a-parser.com/a-parser-for-cpa/
https://a-parser.com/wiki/features-and-benefits/
https://a-parser.com/wiki/parsers/
設定可能な項目
| パラメータ名 | デフォルト値 | 説明 |
|---|---|---|
| Good status | All | サーバーからのどのレスポンスを成功とみなすかを選択します。スクレイピング中にサーバーから別のレスポンスがあった場合、別のプロキシでリクエストが再試行されます |
| Good code RegEx | レスポンスコードをチェックするための正規表現を指定できます | |
| Ban Proxy Code RegEx | サーバーのレスポンスコードに基づいて、プロキシを一定時間(Proxy ban time)禁止できます | |
| Method | GET | リクエストメソッド |
| POST body | POSTメソッド使用時にサーバーに送信するコンテンツ。変数 $query(リクエストURL)、$query.orig(元のクエリ)、および Use Pages オプション使用時の $pagenum(ページ番号)をサポートします。 | |
| Cookies | リクエストに使用するCookieを指定できます。 | |
| User agent | _最新バージョンのChromeのUser-Agentが自動的に設定されます_ | ページリクエスト時の User-Agent ヘッダー |
| Additional headers | テンプレートエンジンの機能やクエリコンストラクタの変数を使用して、任意の形式のリクエストヘッダーを指定できます | |
| Read only headers | ☐ | ヘッダーのみを読み取ります。コンテンツを処理する必要がない場合、トラフィックを節約できます |
| Detect charset on content | ☐ | ページの内容に基づいて文字コードを認識します |
| Emulate browser headers | ☐ | ブラウザのヘッダーをエミュレートします |
| Max redirects count | 0 | スクレイパーが追跡するリダイレクトの最大数 |
| Follow common redirects | ☑ | Max redirects count の制限を回避して、同一ドメイン内での http <-> https および www.domain <-> domain のリダイレクトを許可します |
| Max cookies count | 16 | 保存するCookieの最大数 |
| Engine | HTTP (Fast, JavaScript Disabled) | HTTPエンジン(高速、JavaScriptなし)またはChromeエンジン(低速、JavaScript有効)を選択できます |
| Chrome Headless | ☐ | このオプションが有効な場合、ブラウザは表示されません |
| Chrome DevTools | ☑ | Chromiumのデバッグツールを使用できます |
| Chrome Log Proxy connections | ☑ | このオプションが有効な場合、Chromeの接続に関する情報がログに出力されます |
| Chrome Wait Until | networkidle2 | ページがいつ読み込まれたとみなすかを定義します。値の詳細。 |
| Use HTTP/2 transport | ☐ | HTTP/1.1の代わりにHTTP/2を使用するかどうかを決定します。例えば、GoogleやMajesticはHTTP/1.1を使用すると即座に禁止されます。 |
| Don't verify TLS certs | ☐ | TLS証明書の検証を無効にします |
| Randomize TLS Fingerprint | ☐ | このオプションにより、TLSフィンガープリントによるサイトの禁止を回避できます |
| Bypass CloudFlare | ☑ | CloudFlareのチェックを自動的に回避します |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Chrome経由でCFを回避します |
| Bypass CloudFlare with Chrome Max Pages | 20 | Chrome経由でCFを回避する際の最大ページ数 |
| Subdomains are internal | ☐ | サブドメインを内部リンクとしてカウントするかどうか |
| Follow links | Internal only | どのリンクを辿るか |
| Follow links limit | 0 | Follow linksの制限。各ユニークドメインに適用されます |
| Skip comment blocks | ☐ | コメントブロックをスキップするかどうか |