SE::Google::KeywordPlanner::Ideas - scraper voor zoekwoordvarianten uit Google Keyword Planner
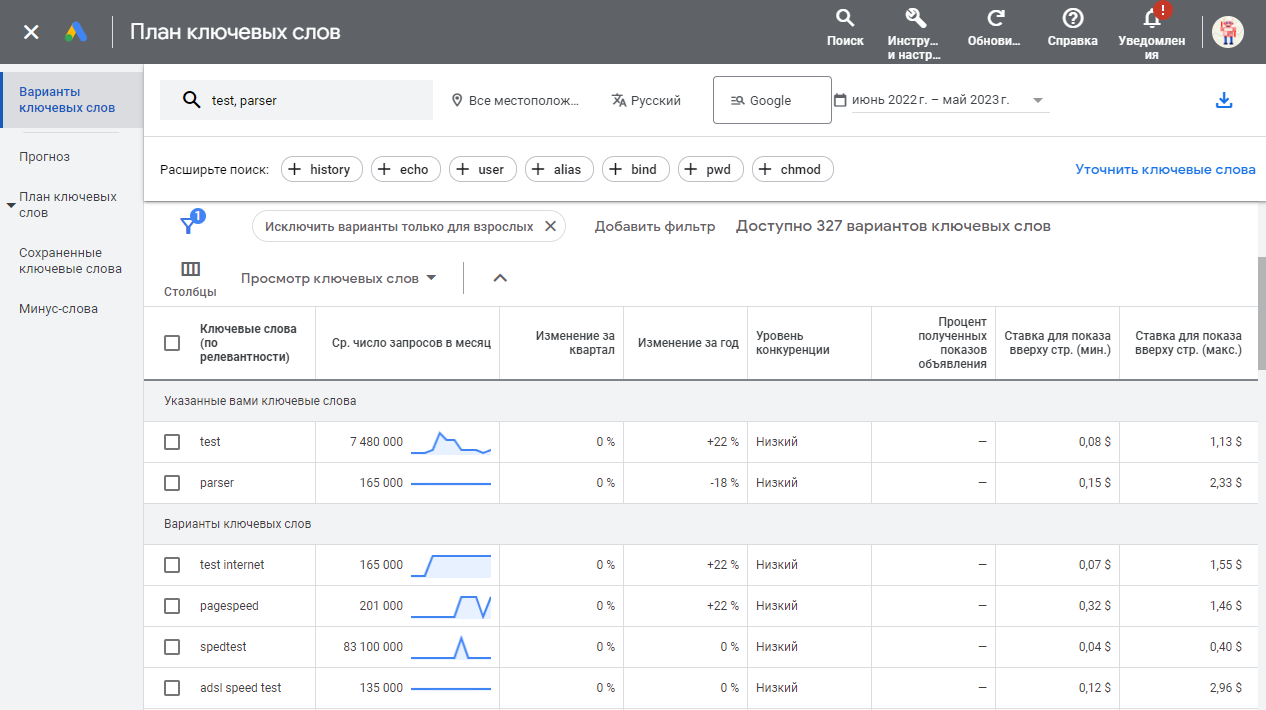
Overzicht van de scraper
 SE::Google::KeywordPlanner::Ideas – gegevensextractie van zoekwoordvarianten en suggesties uit Google Keyword Planner. Er is een grote hoeveelheid data beschikbaar voor gebruik: extractie van lijsten met suggesties, beoordeling van concurrentie voor zoekwoorden, verzamelen van het gemiddelde aantal zoekopdrachten per maand, minimale en maximale biedingen, en het vinden van nieuwe zoekwoorden in vergelijkbare thema's. In de instellingen van de scraper kunt u de taal, regio, locatie en de periode voor de gegevensselectie opgeven. Ook is er een batchmodus beschikbaar, waardoor u met één verzoek aan de service gegevens voor 20 zoekwoorden tegelijk kunt ontvangen, wat de gegevensextractie aanzienlijk versnelt.
SE::Google::KeywordPlanner::Ideas – gegevensextractie van zoekwoordvarianten en suggesties uit Google Keyword Planner. Er is een grote hoeveelheid data beschikbaar voor gebruik: extractie van lijsten met suggesties, beoordeling van concurrentie voor zoekwoorden, verzamelen van het gemiddelde aantal zoekopdrachten per maand, minimale en maximale biedingen, en het vinden van nieuwe zoekwoorden in vergelijkbare thema's. In de instellingen van de scraper kunt u de taal, regio, locatie en de periode voor de gegevensselectie opgeven. Ook is er een batchmodus beschikbaar, waardoor u met één verzoek aan de service gegevens voor 20 zoekwoorden tegelijk kunt ontvangen, wat de gegevensextractie aanzienlijk versnelt.Dankzij de multithreading-werking van A-Parser kan de snelheid van de verwerking oplopen tot enkele duizenden aanvragen per minuut.
De functionaliteit van A-Parser maakt het mogelijk om instellingen voor de scraper SE::Google::KeywordPlanner::Ideas op te slaan voor toekomstig gebruik (presets), een schema voor gegevensextractie in te stellen en nog veel meer.
Het opslaan van resultaten is mogelijk in de vorm en structuur die u nodig heeft, dankzij de ingebouwde krachtige sjabloon-engine Template Toolkit waarmee u extra logica op de resultaten kunt toepassen en gegevens in verschillende formaten kunt uitvoeren, waaronder JSON, SQL en CSV.
Verzamelde gegevens
- Gemiddeld aantal zoekopdrachten per maand voor het gezochte zoekwoord
- Lijsten met suggesties
- Zoekwoordvarianten
- Gemiddeld aantal zoekopdrachten per maand
- Concurrentie
- Minimale en maximale biedingen
- Trends voor elke verkregen variant
Mogelijkheden
- Ondersteuning voor autorisatie via login-wachtwoord of via het invoegen van cookies en headers
- Bepaling van de nauwkeurigheid van $volume - exacte/afgeronde waarde
- Batchmodus wordt ondersteund, meer details in de sectie Queries (Query's)
- Ondersteuning voor multi-accounts (om het juiste account te selecteren moet de
ocid(uscid)worden opgegeven) - Gegevensextractie van zoekvolumes voor elk zoekwoord per maand voor de opgegeven periode (
$ideas.$i.trends). De gegevens worden gepresenteerd in JSON, een voorbeeld van de uitvoer in het resultaat staat in de onderstaande screenshot:
Spoiler: Screenshot
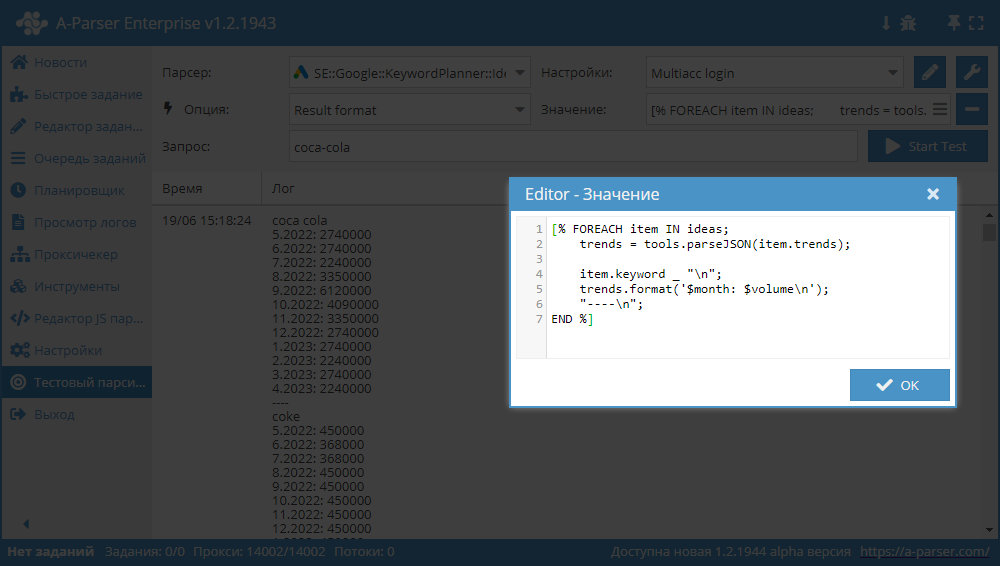
Sjabloon:
[% FOREACH item IN ideas;
trends = tools.parseJSON(item.trends);
item.keyword _ "\n";
trends.format('$month: $volume\n');
"----\n";
END %]
Toepassingen
- Gegevensextractie van lijsten met suggesties
- Beoordeling van concurrentie voor zoekwoorden
- Verzamelen van gemiddeld aantal zoekopdrachten per maand, minimale en maximale biedingen
- Zoeken naar nieuwe zoekwoorden in een vergelijkbaar thema
Instelling
Er zijn twee opties om de scraper in te stellen:
- e-mail\wachtwoord van het Keyword Planner-account opgeven
- autoriseren in de browser en de benodigde waarden kopiëren
Wees voorzichtig met het aantal threads. Het wordt aanbevolen om een klein aantal threads op te geven, waarbij gegevensextractie zonder proxy heel goed mogelijk is.
Autorisatie via e-mail en wachtwoord
U moet de opties E-mail en Password overschrijven door de gegevens van uw Keyword Planner-account op te geven. Er moet een actieve campagne op het account aanwezig zijn.
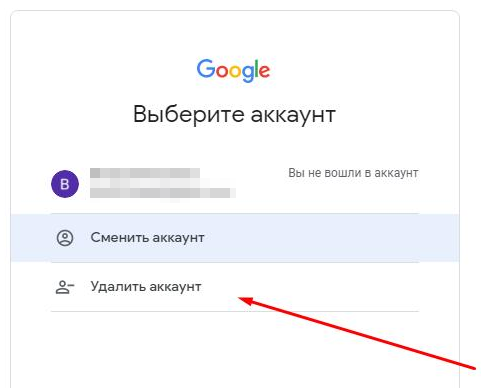
Spoiler: (Oplossing) Login failed TypeError: Cannot read property '1' of null
In het geval van deze fout moet u uw Google-account uit de browser verwijderen en opnieuw inloggen.
Autorisatie in de browser en headers invoegen in de scraper
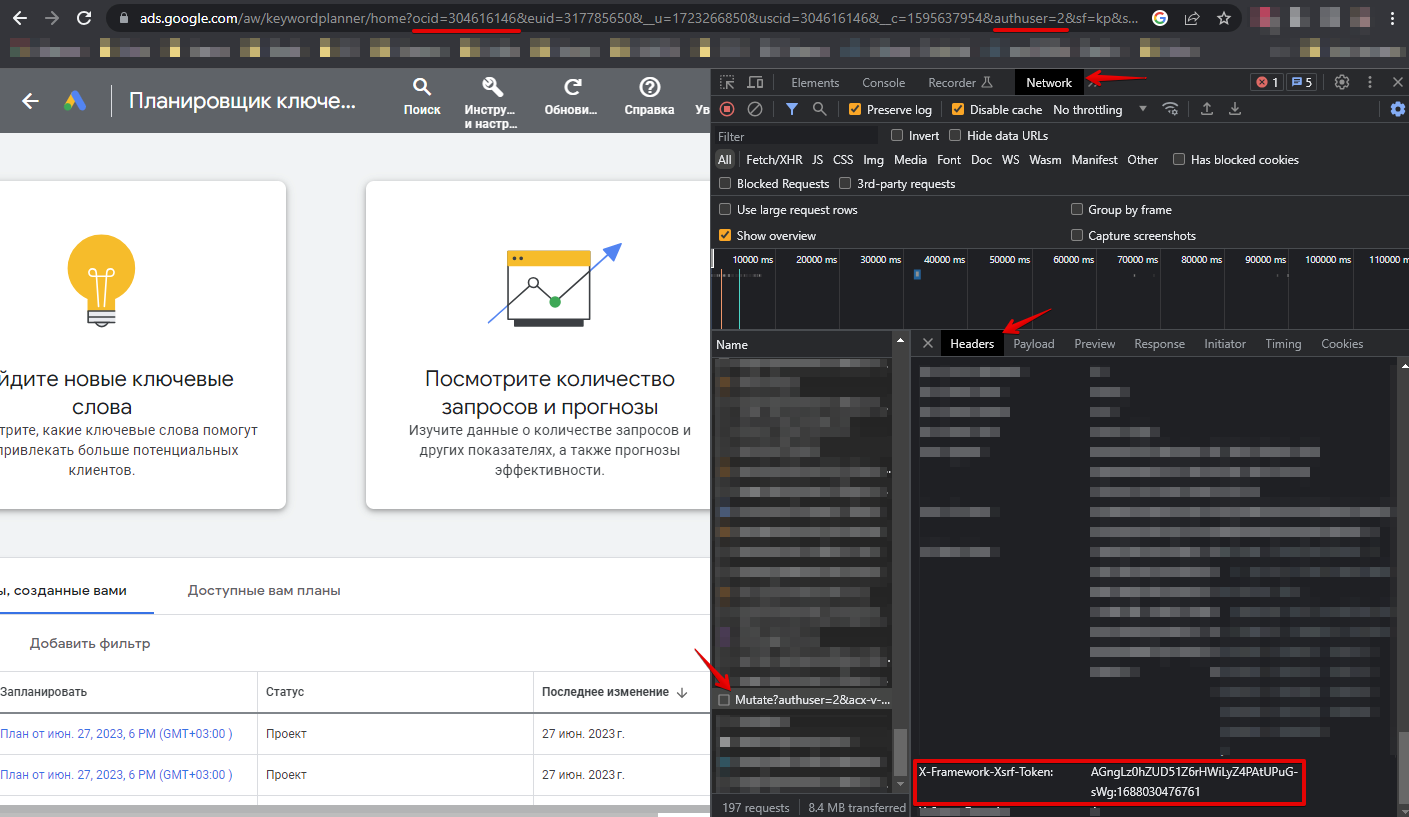
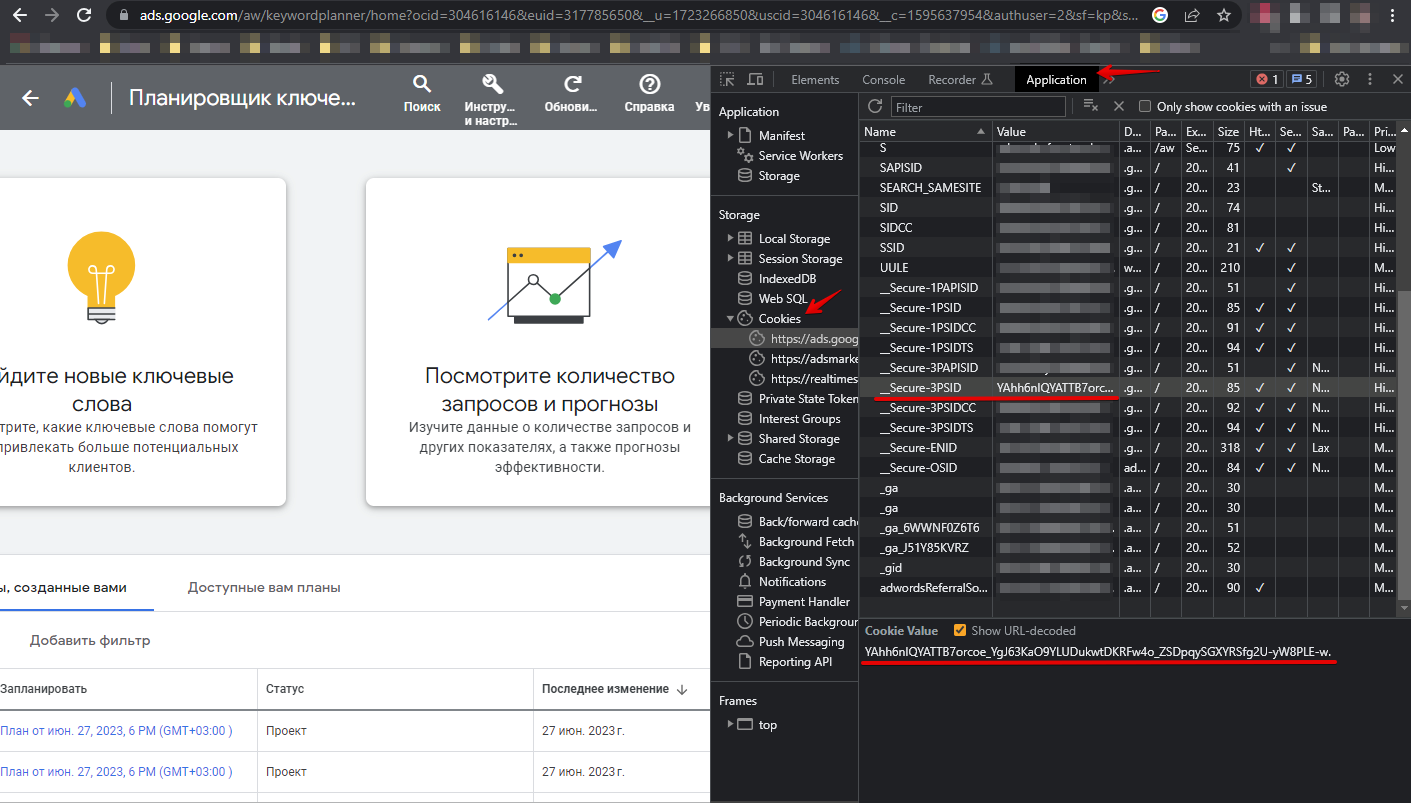
U moet in de browser autoriseren via de link https://ads.google.com/aw/keywordplanner/home, de eerste campagne maken als die er nog niet was, de volgende gegevens ophalen en deze in de instellingen van de scraper opgeven:
Cookies kunnen op twee manieren worden opgegeven:
- Alle cookies opgeven in de optie All cookies
- Waarden uit cookies opgeven voor de opties __Secure-3PSID, __Secure-3PSIDTS (__Secure-3PSIDTS moet worden opgegeven als authuser op het account gelijk is aan 0)
Overige headers:
- Waarde van de header x-framework-xsrf-token
- Waarde van de parameter ocid of uscid uit de URL
- Waarde van de parameter authuser uit de URL
Spoiler: Hoe de benodigde parameters te vinden
Query's
Afhankelijk van de waarde van de parameter Query type kunnen query's er verschillend uitzien. Hieronder worden de mogelijke opties vermeld, voorbeelden getoond en de kenmerken van de verkregen resultaten beschreven.
Keyword
Query's moeten in de vorm van zoekwoorden zijn, één zoekwoord per regel. Voorbeeld van query's:
test
scraper
Windows 11
hoe kweek je een boom
De batchmodus wordt ondersteund, die wordt geactiveerd door de optie Bulk (packet) mode. In deze modus verzendt de scraper in de aanvraag naar de service pakketten van 20 zoekwoorden, waardoor de logica voor het vullen van de resultaten verandert:
$volumewordt voor elk zoekwoord ingevuld$ideasen$suggestsworden alleen voor het eerste zoekwoord ingevuld, maar deze arrays bevatten alle resultaten gezamenlijk voor alle zoekwoorden die in dit pakket worden gebruikt
Site + keyword
Query's moeten in de vorm van een website en na een spatie een zoekwoord zijn. Voorbeeld van query's:
speedtest.com Network speed
a-parser.com parser
Ook de batchmodus wordt ondersteund; om deze te gebruiken moet u de zoekwoorden opsommen gescheiden door een komma, voorbeeld:
4pda.to android,ios,firmware
google.com google,ads,reclame,websites zoeken op internet
$volumewordt voor dit type query's in batchmodus niet gescraped
Entire site
Als query's moeten domeinen worden opgegeven, één per regel. Bijvoorbeeld:
apple.com
microsoft.com
$volumewordt voor dit type query's niet gescraped
URL
Als query's moeten links worden opgegeven, één per regel. Bijvoorbeeld:
https://a-parser.com/docs/parsers/se-google-keywordplanner
https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/JavaScript_basics
$volumewordt voor dit type query's niet gescraped
Query-substituties
U kunt ingebouwde macro's gebruiken voor automatische substitutie van subquery's uit bestanden. Als we bijvoorbeeld aan elke query een lijst met andere woorden willen toevoegen, geven we enkele basisquery's op:
fantasy
tower defense
rpg
In het queryformaat geven we de macro op voor de substitutie van extra woorden uit het bestand keywords.txt. Deze methode maakt het mogelijk om de variatie van query's aanzienlijk te vergroten:
{subs:keywords} $query
Deze macro maakt evenveel extra query's aan als er in het bestand staan voor elke oorspronkelijke zoekopdracht, wat in totaal resulteert in [aantal oorspronkelijke query's] x [aantal query's in het Keywords-bestand] = [totaal aantal query's] als resultaat van de macro.
Bijvoorbeeld, als het bestand keywords.txt het volgende bevat:
free
online
Uiteindelijk zal de substitutie-macro de 3 basisquery's omzetten in 6:
free fantasy
online fantasy
free tower defense
online tower defense
free rpg
online rpg
Voorbeelden van resultaatuitvoer
A-Parser ondersteunt flexibele formattering van resultaten dankzij de ingebouwde sjabloon-engine Template Toolkit, waardoor resultaten in een willekeurige vorm kunnen worden uitgevoerd, evenals in gestructureerde formaten zoals CSV of JSON.
Standaarduitvoer
Resultaatformaat:
$ideas.format('$keyword\n')
Voorbeeld van resultaat:
coca cola
iphone 11 pro
winter
iphone 11 pro max
winter season
iphone11
iphone 11 price
apple iphone 11
iphone 11pro
coke
11 pro max
iphone 11 pro price
iphone 11 max
iphone pro max
iphone 11 128gb
11 pro
iphone 11 pro max price
apple iphone 11 pro
apple iphone 11 pro max
new iphone 11
iphone 11 max pro
apple 11 pro
iphone 11 deals
iphone 11 pro max 256gb
diet coke
first day of winter
iphone 11 pro 256gb
coke zero
iphone pro 11
apple 11 pro max
Uitvoer naar CSV-tabel
Resultaatformaat:
[% FOREACH i IN ideas;
tools.CSVline(i.keyword, i.volume, i.min_bid, i.max_bid);
END %]
Bestandsnaam:
$datefile.format().csv
Begintekst:
Keyword,Volume,"Min bid","Max bid"
In het Resultaatformaat wordt de sjabloon-engine Template Toolkit toegepast om de array $ideas in een FOREACH-lus uit te voeren.
In de bestandsnaam van de resultaten hoeft u alleen de bestandsextensie te wijzigen naar csv.
Om de optie "Prepend text" beschikbaar te maken in de Taak-editor, moet u "More options" activeren. In "Prepend text" schrijven we de kolomnamen gescheiden door een komma en maken we de tweede regel leeg.
Opslaan in SQL-formaat
Resultaatformaat:
[% FOREACH ideas;
"INSERT INTO ideas VALUES('" _ keyword _ "', '" _ volume _ "')\n";
END %]
Voorbeeld van resultaat:
INSERT INTO ideas VALUES('parfum', '50000')
INSERT INTO ideas VALUES('eyfel perfume', '5000')
INSERT INTO ideas VALUES('memo marfa', '5000')
INSERT INTO ideas VALUES('duxi', '5000')
INSERT INTO ideas VALUES('kenzo intense', '5000')
INSERT INTO ideas VALUES('climat lancome', '5000')
INSERT INTO ideas VALUES('v canto', '5000')
INSERT INTO ideas VALUES('majda bekkali', '5000')
INSERT INTO ideas VALUES('v canto ricina', '500')
INSERT INTO ideas VALUES('v canto stramonio', '5000')
INSERT INTO ideas VALUES('terenzi kirke', '500')
INSERT INTO ideas VALUES('duhi', '500')
INSERT INTO ideas VALUES('max mara le parfum', '500')
INSERT INTO ideas VALUES('stramonio v canto', '500')
INSERT INTO ideas VALUES('sheikh parfum', '500')
INSERT INTO ideas VALUES('jacques zolty', '500')
INSERT INTO ideas VALUES('aj arabia', '500')
INSERT INTO ideas VALUES('christian lacroix bazar', '500')
INSERT INTO ideas VALUES('juliette has a gun romantina', '500')
INSERT INTO ideas VALUES('vilhelm parfumerie mango skin', '500')
INSERT INTO ideas VALUES('v canto mirabile', '500')
INSERT INTO ideas VALUES('donna karan dkny be delicious', '500')
INSERT INTO ideas VALUES('arteolfatto', '500')
INSERT INTO ideas VALUES('aquawoman rochas', '500')
INSERT INTO ideas VALUES('angel and demon givenchy', '500')
INSERT INTO ideas VALUES('venenum kiss', '500')
INSERT INTO ideas VALUES('v canto mandragola', '500')
INSERT INTO ideas VALUES('angel demon givenchy', '500')
INSERT INTO ideas VALUES('hugo boss boss ma vie pour femme', '500')
INSERT INTO ideas VALUES('nina ricci mademoiselle ricci', '500')
Dump van resultaten naar JSON
Algemeen resultaatformaat:
[% data = [];
FOREACH p1.ideas;
item = {};
item.keyword = keyword;
item.volume = volume;
data.push(item);
END %]$data.json\n
Voorbeeld van resultaat:
[{"keyword":"parfum","volume":"50000"},{"keyword":"eyfel perfume","volume":"5000"},{"keyword":"memo marfa","volume":"5000"},{"keyword":"duxi","volume":"5000"},{"keyword":"kenzo intense","volume":"5000"},{"keyword":"climat lancome","volume":"5000"},{"keyword":"v canto","volume":"5000"},{"keyword":"majda bekkali","volume":"5000"},{"keyword":"v canto ricina","volume":"500"},{"keyword":"v canto stramonio","volume":"5000"},{"keyword":"terenzi kirke","volume":"500"},{"keyword":"duhi","volume":"500"},{"keyword":"max mara le parfum","volume":"500"},{"keyword":"stramonio v canto","volume":"500"},{"keyword":"sheikh parfum","volume":"500"},{"keyword":"jacques zolty","volume":"500"},{"keyword":"aj arabia","volume":"500"},{"keyword":"christian lacroix bazar","volume":"500"},{"keyword":"juliette has a gun romantina","volume":"500"},{"keyword":"vilhelm parfumerie mango skin","volume":"500"},{"keyword":"v canto mirabile","volume":"500"},{"keyword":"donna karan dkny be delicious","volume":"500"},{"keyword":"arteolfatto","volume":"500"},{"keyword":"aquawoman rochas","volume":"500"},{"keyword":"angel and demon givenchy","volume":"500"},{"keyword":"venenum kiss","volume":"500"},{"keyword":"v canto mandragola","volume":"500"},{"keyword":"angel demon givenchy","volume":"500"},{"keyword":"hugo boss boss ma vie pour femme","volume":"500"},{"keyword":"nina ricci mademoiselle ricci","volume":"500"},{"keyword":"mmmm juliette has a gun","volume":"500"},{"keyword":"v canto lucrethia","volume":"500"},{"keyword":"mango skin vilhelm parfumerie","volume":"500"},{"keyword":"dalissime salvador dali","volume":"500"},{"keyword":"molecula 02","volume":"50000"},{"keyword":"lucia parfum","volume":"500"},{"keyword":"boadicea pure narcotic","volume":"500"},{"keyword":"terenzi andromeda","volume":"500"}]
Meer details over het uitvoeren van resultaten naar JSON worden beschreven in dit artikel.
Mogelijke instellingen
| Parameter | Standaardwaarde | Beschrijving |
|---|---|---|
| All cookies | Alle cookies opgeven | |
| Cookie "__Secure-3PSID" | Cookie "__Secure-3PSID" | |
| Cookie "__Secure-3PSIDTS" | Cookie "__Secure-3PSIDTS" | |
| Header "x-framework-xsrf-token" | Header "x-framework-xsrf-token" | |
| Url parameter "ocid"("uscid") | Parameter "ocid"("uscid") | |
| Url parameter "authuser" | 0 | Parameter "authuser" |
| E-mail voor autorisatie in Keyword Planner | ||
| Password | Wachtwoord voor autorisatie in Keyword Planner | |
| Recovery e-mail | E-mail voor herstel van toegang | |
| Browser headless (debug auth) | ☑ | Headless-modus voor de browser die wordt gebruikt voor autorisatie via login-wachtwoord |
| Log Login Screenshot (debug auth) | ☐ | Maken van een screenshot van de autorisatiepagina en uitvoer naar het taaklogboek |
| Date from | Last 12 months | Datum vanaf |
| Date to | Last 12 months | Datum tot |
| Language | English | Taal |
| Search networks | Google | Zoeknetwerk |
| Currency | USD | Valuta |
| Location code | Locatie (hier moet de locatie-id worden opgegeven, deze is te vinden in de eerste kolom van deze tabel (kopie)) | |
| Query type | Keyword | Type query |
| Exclude brand names in results | ☐ | Merkfilter |
| Exclude adult ideas | ☑ | Filter voor volwassen content |
| Bulk (packet) mode | ☐ | Batchmodus inschakelen |