SE::Google::KeywordPlanner::Ideas - scraper d'idées de mots-clés de Google Keyword Planner
Présentation du scraper
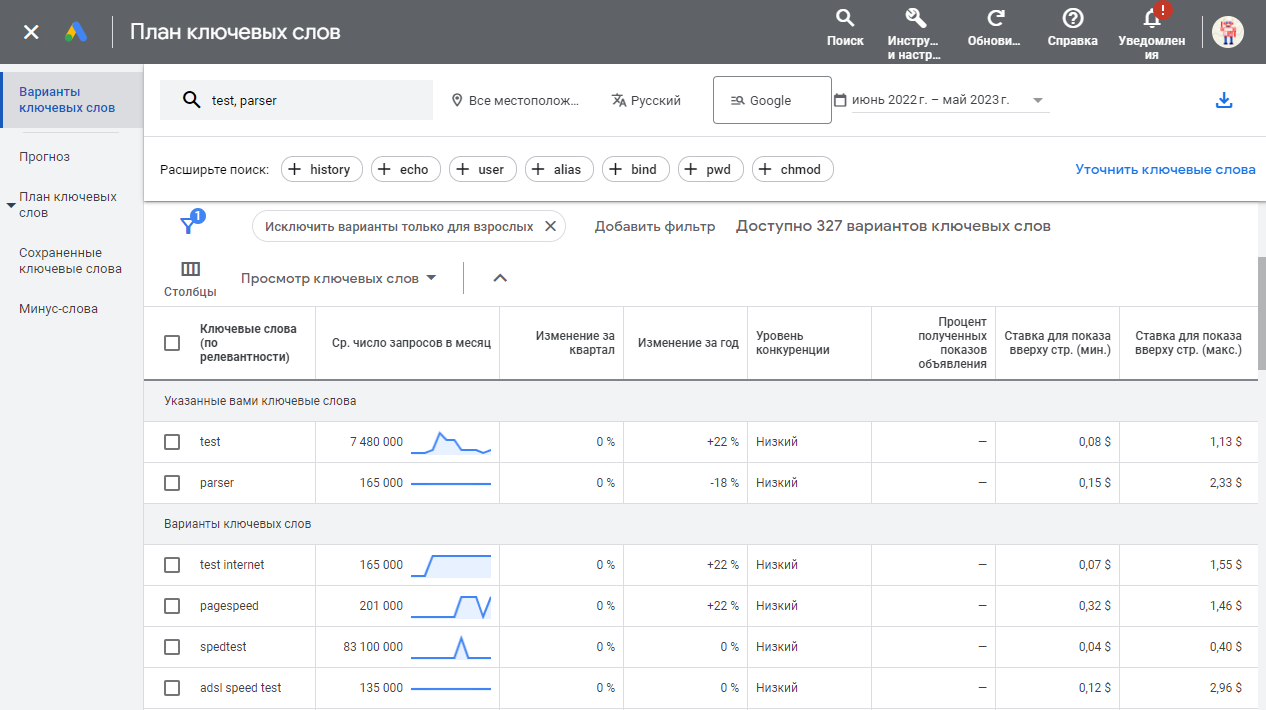
 SE::Google::KeywordPlanner::Ideas – collecte de données sur les variantes de mots-clés et les suggestions de Google Keyword Planner. De nombreuses données sont disponibles : collecte de listes de suggestions, évaluation de la concurrence pour les mots-clés, collecte du nombre moyen de requêtes mensuelles, des enchères minimales et maximales, recherche de nouveaux mots-clés de thématiques similaires. Dans les paramètres du scraper, vous pouvez spécifier la langue, la région, la localisation et la période d'échantillonnage des données. Un mode par lots est également disponible, permettant d'obtenir des données pour 20 mots-clés en une seule requête au service, accélérant ainsi considérablement la collecte de données.
SE::Google::KeywordPlanner::Ideas – collecte de données sur les variantes de mots-clés et les suggestions de Google Keyword Planner. De nombreuses données sont disponibles : collecte de listes de suggestions, évaluation de la concurrence pour les mots-clés, collecte du nombre moyen de requêtes mensuelles, des enchères minimales et maximales, recherche de nouveaux mots-clés de thématiques similaires. Dans les paramètres du scraper, vous pouvez spécifier la langue, la région, la localisation et la période d'échantillonnage des données. Un mode par lots est également disponible, permettant d'obtenir des données pour 20 mots-clés en une seule requête au service, accélérant ainsi considérablement la collecte de données.Grâce au traitement multithread de A-Parser, la vitesse de traitement des requêtes peut atteindre plusieurs milliers de requêtes par minute.
La fonctionnalité de A-Parser permet de sauvegarder les paramètres de collecte de données du scraper SE::Google::KeywordPlanner::Ideas pour une utilisation ultérieure (présélections), de définir un calendrier de collecte et bien plus encore.
La sauvegarde des résultats est possible dans la forme et la structure dont vous avez besoin, grâce au puissant moteur de gabarit intégré Template Toolkit qui permet d'appliquer une logique supplémentaire aux résultats et d'afficher les données dans divers formats, y compris JSON, SQL et CSV.
Données collectées
- Nombre moyen de requêtes par mois pour le mot-clé recherché
- Listes de suggestions
- Variantes de mots-clés
- Nombre moyen de requêtes par mois
- Concurrence
- Enchères minimales et maximales
- Tendances pour chaque variante obtenue
Fonctionnalités
- Prise en charge de l'authentification par login-mot de passe ou par substitution de cookies et d'en-têtes
- Détermination du degré de précision $volume - valeur exacte/arrondie
- Le mode par lots est pris en charge, plus de détails dans la section Queries (Requêtes)
- Prise en charge du multi-compte (pour choisir le bon compte, son
ocid(uscid)doit obligatoirement être indiqué) - Collecte de données sur les volumes de recherche pour chaque mot-clé par mois pour la période spécifiée (
$ideas.$i.trends). Les données sont présentées en JSON, exemple de leur affichage dans le résultat sur la capture d'écran ci-dessous :
Spoiler: Capture d'écran
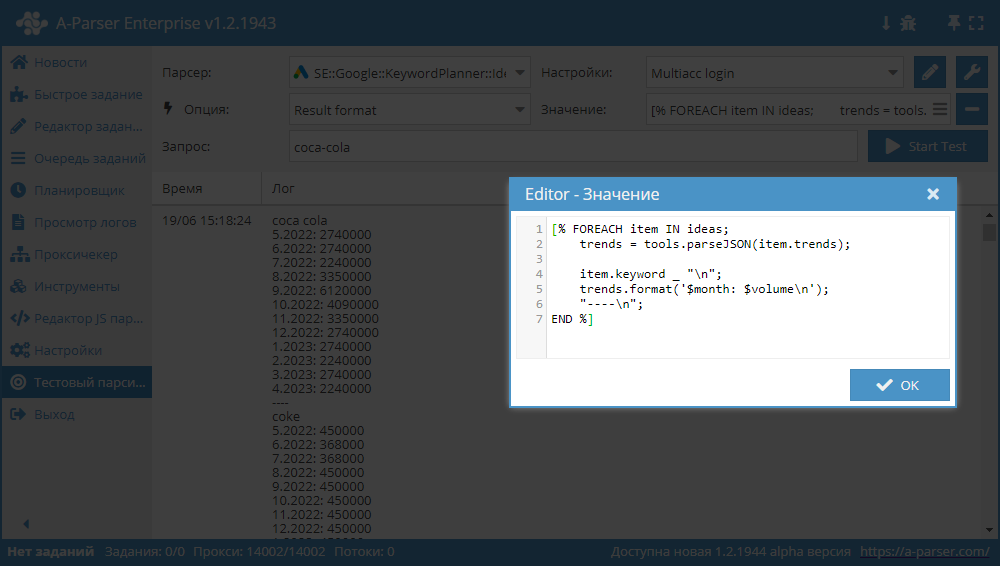
Gabarit :
[% FOREACH item IN ideas;
trends = tools.parseJSON(item.trends);
item.keyword _ "\n";
trends.format('$month: $volume\n');
"----\n";
END %]
Cas d'utilisation
- Collecte de listes de suggestions
- Évaluation de la concurrence pour les mots-clés
- Collecte du nombre moyen de requêtes par mois, des enchères minimales et maximales
- Recherche de nouveaux mots-clés de thématique similaire
Configuration
Il existe deux options pour configurer le scraper :
- indiquer l'e-mail\mot de passe du compte Keyword Planner
- s'authentifier dans le navigateur et copier les valeurs nécessaires
Soyez prudent avec le nombre de threads. Il est recommandé d'indiquer un petit nombre de threads, la collecte sans proxy étant tout à fait possible.
Authentification par e-mail et mot de passe
Vous devez redéfinir les options E-mail et Password en indiquant les données de votre compte Keyword Planner. Une campagne doit obligatoirement être créée sur le compte.
Spoiler: (Solution) Login failed TypeError: Cannot read property '1' of null
En cas d'apparition de cette erreur, vous devez supprimer votre compte Google du navigateur et vous reconnecter.
Authentification dans le navigateur et substitution d'en-têtes dans le scraper
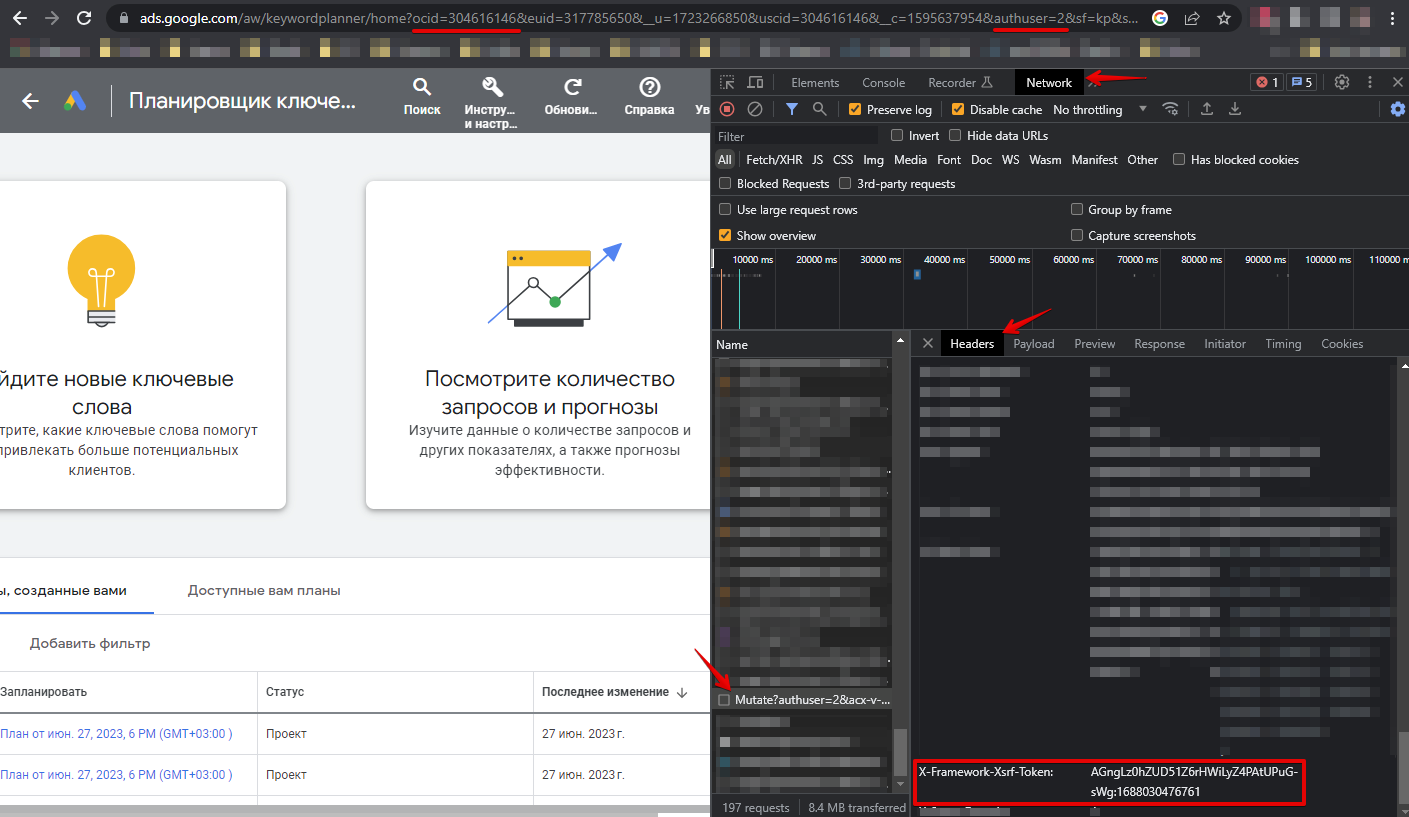
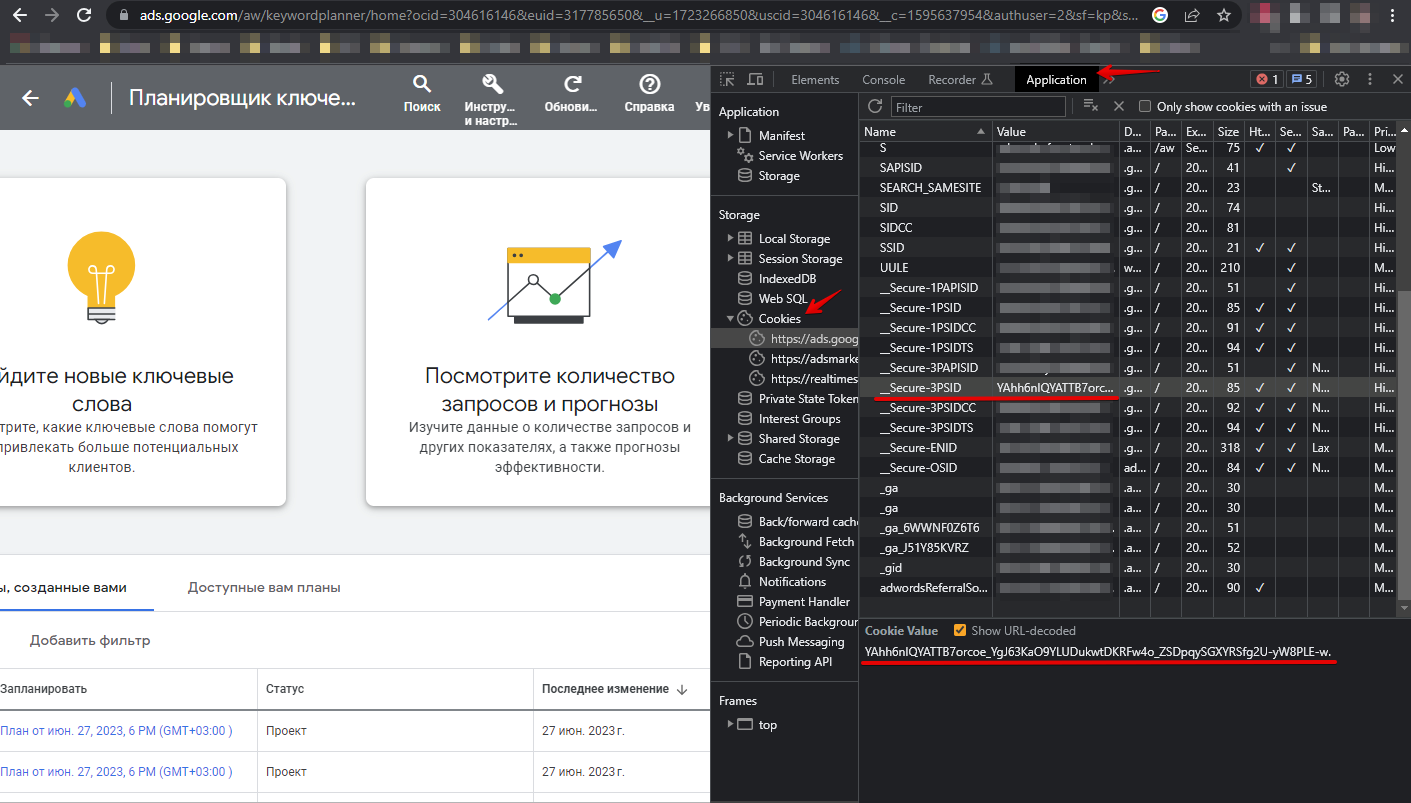
Il est nécessaire de s'authentifier dans le navigateur via le lien https://ads.google.com/aw/keywordplanner/home, de créer une première campagne si ce n'est pas déjà fait, de récupérer les données suivantes et de les indiquer dans les paramètres du scraper :
Les cookies peuvent être indiqués de deux manières :
- Indiquer tous les cookies dans l'option All cookies
- Indiquer les valeurs des cookies pour les options __Secure-3PSID, __Secure-3PSIDTS (__Secure-3PSIDTS doit être indiqué si authuser sur le compte est égal à 0)
Autres en-têtes :
- Valeur de l'en-tête x-framework-xsrf-token
- Valeur du paramètre ocid ou uscid de l'URL
- Valeur du paramètre authuser de l'URL
Spoiler: Comment trouver les paramètres nécessaires
Requêtes
Selon la valeur du paramètre Query type, les requêtes peuvent avoir différentes formes. Les options possibles sont énumérées ci-dessous, avec des exemples et une description des particularités des résultats obtenus.
Keyword
Les requêtes doivent être sous forme de mots-clés, un mot-clé par ligne. Exemple de requêtes :
test
scraper
Windows 11
comment faire pousser un arbre
Le mode par lots est pris en charge, activé par l'option Bulk (packet) mode. Dans ce mode, le scraper enverra des paquets de 20 mots-clés dans la requête au service, ce qui modifie la logique de remplissage des résultats :
$volumesera rempli pour chaque mot-clé$ideaset$suggestsne seront remplis que pour le premier mot-clé, mais ces tableaux contiendront tous les résultats cumulés pour tous les mots-clés utilisés dans ce paquet
Site + keyword
Les requêtes doivent être sous forme d'un site suivi d'un espace et d'un mot-clé. Exemple de requêtes :
speedtest.com Network speed
a-parser.com parser
Le mode par lots est également pris en charge ; pour l'utiliser, vous devez énumérer les mots-clés séparés par des virgules, exemple :
4pda.to android,ios,firmware
google.com google,ads,publicité,recherche de sites sur internet
$volumepour ce type de requêtes en mode par lots n'est pas collecté
Entire site
En tant que requêtes, vous devez indiquer des domaines, un par ligne. Par exemple :
apple.com
microsoft.com
$volumepour ce type de requêtes n'est pas collecté
URL
En tant que requêtes, vous devez indiquer des liens, un par ligne. Par exemple :
https://a-parser.com/docs/parsers/se-google-keywordplanner
https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/JavaScript_basics
$volumepour ce type de requêtes n'est pas collecté
Substitutions de requêtes
Vous pouvez utiliser les macros intégrées pour la substitution automatique de sous-requêtes à partir de fichiers, par exemple si nous voulons ajouter à chaque requête une liste d'autres mots, indiquons quelques requêtes de base :
fantasy
tower defense
rpg
Dans le format de requête, indiquons la macro de substitution de mots supplémentaires à partir du fichier keywords.txt, cette méthode permet d'augmenter considérablement la variabilité des requêtes :
{subs:keywords} $query
Cette macro créera autant de requêtes supplémentaires qu'il y en a dans le fichier pour chaque requête de recherche initiale, ce qui donnera au total [nombre de requêtes initiales] x [nombre de requêtes dans le fichier Keywords] = [nombre total de requêtes] suite au travail de la macro.
Par exemple, si le fichier keywords.txt contient :
free
online
Au final, la macro de substitution transformera 3 requêtes de base en 6 :
free fantasy
online fantasy
free tower defense
online tower defense
free rpg
online rpg
Exemples de formats de sortie
A-Parser prend en charge un formatage flexible des résultats grâce au moteur de gabarit intégré Template Toolkit, ce qui lui permet d'afficher les résultats sous une forme libre, ainsi que sous une forme structurée, par exemple CSV ou JSON.
Sortie par défaut
Format du résultat :
$ideas.format('$keyword\n')
Exemple de résultat :
coca cola
iphone 11 pro
winter
iphone 11 pro max
winter season
iphone11
iphone 11 price
apple iphone 11
iphone 11pro
coke
11 pro max
iphone 11 pro price
iphone 11 max
iphone pro max
iphone 11 128gb
11 pro
iphone 11 pro max price
apple iphone 11 pro
apple iphone 11 pro max
new iphone 11
iphone 11 max pro
apple 11 pro
iphone 11 deals
iphone 11 pro max 256gb
diet coke
first day of winter
iphone 11 pro 256gb
coke zero
iphone pro 11
apple 11 pro max
Sortie dans un tableau CSV
Format du résultat :
[% FOREACH i IN ideas;
tools.CSVline(i.keyword, i.volume, i.min_bid, i.max_bid);
END %]
Nom du fichier :
$datefile.format().csv
Texte initial :
Keyword,Volume,"Min bid","Max bid"
Dans le Format des résultats, le moteur de gabarit Template Toolkit est utilisé pour afficher le tableau $ideas dans une boucle FOREACH.
Dans le nom du fichier de résultats, il suffit de changer l'extension du fichier en csv.
Pour que l'option "Prepend text" soit disponible dans l'Éditeur de tâches, vous devez activer "More options". Dans "Prepend text", nous inscrivons les noms des colonnes séparés par des virgules et nous laissons la deuxième ligne vide.
Sauvegarde au format SQL
Format du résultat :
[% FOREACH ideas;
"INSERT INTO ideas VALUES('" _ keyword _ "', '" _ volume _ "')\n";
END %]
Exemple de résultat :
INSERT INTO ideas VALUES('parfum', '50000')
INSERT INTO ideas VALUES('eyfel perfume', '5000')
INSERT INTO ideas VALUES('memo marfa', '5000')
INSERT INTO ideas VALUES('duxi', '5000')
INSERT INTO ideas VALUES('kenzo intense', '5000')
INSERT INTO ideas VALUES('climat lancome', '5000')
INSERT INTO ideas VALUES('v canto', '5000')
INSERT INTO ideas VALUES('majda bekkali', '5000')
INSERT INTO ideas VALUES('v canto ricina', '500')
INSERT INTO ideas VALUES('v canto stramonio', '5000')
INSERT INTO ideas VALUES('terenzi kirke', '500')
INSERT INTO ideas VALUES('duhi', '500')
INSERT INTO ideas VALUES('max mara le parfum', '500')
INSERT INTO ideas VALUES('stramonio v canto', '500')
INSERT INTO ideas VALUES('sheikh parfum', '500')
INSERT INTO ideas VALUES('jacques zolty', '500')
INSERT INTO ideas VALUES('aj arabia', '500')
INSERT INTO ideas VALUES('christian lacroix bazar', '500')
INSERT INTO ideas VALUES('juliette has a gun romantina', '500')
INSERT INTO ideas VALUES('vilhelm parfumerie mango skin', '500')
INSERT INTO ideas VALUES('v canto mirabile', '500')
INSERT INTO ideas VALUES('donna karan dkny be delicious', '500')
INSERT INTO ideas VALUES('arteolfatto', '500')
INSERT INTO ideas VALUES('aquawoman rochas', '500')
INSERT INTO ideas VALUES('angel and demon givenchy', '500')
INSERT INTO ideas VALUES('venenum kiss', '500')
INSERT INTO ideas VALUES('v canto mandragola', '500')
INSERT INTO ideas VALUES('angel demon givenchy', '500')
INSERT INTO ideas VALUES('hugo boss boss ma vie pour femme', '500')
INSERT INTO ideas VALUES('nina ricci mademoiselle ricci', '500')
Dump des résultats en JSON
Format général du résultat :
[% data = [];
FOREACH p1.ideas;
item = {};
item.keyword = keyword;
item.volume = volume;
data.push(item);
END %]$data.json\n
Exemple de résultat :
[{"keyword":"parfum","volume":"50000"},{"keyword":"eyfel perfume","volume":"5000"},{"keyword":"memo marfa","volume":"5000"},{"keyword":"duxi","volume":"5000"},{"keyword":"kenzo intense","volume":"5000"},{"keyword":"climat lancome","volume":"5000"},{"keyword":"v canto","volume":"5000"},{"keyword":"majda bekkali","volume":"5000"},{"keyword":"v canto ricina","volume":"500"},{"keyword":"v canto stramonio","volume":"5000"},{"keyword":"terenzi kirke","volume":"500"},{"keyword":"duhi","volume":"500"},{"keyword":"max mara le parfum","volume":"500"},{"keyword":"stramonio v canto","volume":"500"},{"keyword":"sheikh parfum","volume":"500"},{"keyword":"jacques zolty","volume":"500"},{"keyword":"aj arabia","volume":"500"},{"keyword":"christian lacroix bazar","volume":"500"},{"keyword":"juliette has a gun romantina","volume":"500"},{"keyword":"vilhelm parfumerie mango skin","volume":"500"},{"keyword":"v canto mirabile","volume":"500"},{"keyword":"donna karan dkny be delicious","volume":"500"},{"keyword":"arteolfatto","volume":"500"},{"keyword":"aquawoman rochas","volume":"500"},{"keyword":"angel and demon givenchy","volume":"500"},{"keyword":"venenum kiss","volume":"500"},{"keyword":"v canto mandragola","volume":"500"},{"keyword":"angel demon givenchy","volume":"500"},{"keyword":"hugo boss boss ma vie pour femme","volume":"500"},{"keyword":"nina ricci mademoiselle ricci","volume":"500"},{"keyword":"mmmm juliette has a gun","volume":"500"},{"keyword":"v canto lucrethia","volume":"500"},{"keyword":"mango skin vilhelm parfumerie","volume":"500"},{"keyword":"dalissime salvador dali","volume":"500"},{"keyword":"molecula 02","volume":"50000"},{"keyword":"lucia parfum","volume":"500"},{"keyword":"boadicea pure narcotic","volume":"500"},{"keyword":"terenzi andromeda","volume":"500"}]
Plus de détails sur la sortie des résultats en JSON sont décrits dans cet article.
Paramètres possibles
| Paramètre | Valeur par défaut | Description |
|---|---|---|
| All cookies | Indication de tous les cookies | |
| Cookie "__Secure-3PSID" | Cookie "__Secure-3PSID" | |
| Cookie "__Secure-3PSIDTS" | Cookie "__Secure-3PSIDTS" | |
| Header "x-framework-xsrf-token" | En-tête "x-framework-xsrf-token" | |
| Url parameter "ocid"("uscid") | Paramètre "ocid"("uscid") | |
| Url parameter "authuser" | 0 | Paramètre "authuser" |
| E-mail pour l'authentification dans Keyword Planner | ||
| Password | Mot de passe pour l'authentification dans Keyword Planner | |
| Recovery e-mail | E-mail pour la récupération d'accès | |
| Browser headless (debug auth) | ☑ | Mode headless pour le navigateur utilisé pour l'authentification par login-mot de passe |
| Log Login Screenshot (debug auth) | ☐ | Création d'une capture d'écran de la page d'authentification et affichage dans le log de la tâche |
| Date from | Last 12 months | Date de |
| Date to | Last 12 months | Date à |
| Language | English | Langue |
| Search networks | Google | Réseau de recherche |
| Currency | USD | Devise |
| Location code | Localisation (ici vous devez indiquer l'id de la localisation, vous pouvez le récupérer dans la première colonne de ce tableau (copie)) | |
| Query type | Keyword | Type de requête |
| Exclude brand names in results | ☐ | Filtre de marques |
| Exclude adult ideas | ☑ | Filtre de contenu pour adultes |
| Bulk (packet) mode | ☐ | Activation du mode par lots |