HTML::EmailExtractor - Gegevensextractie van e-mailadressen van websites
Overzicht van de scraper
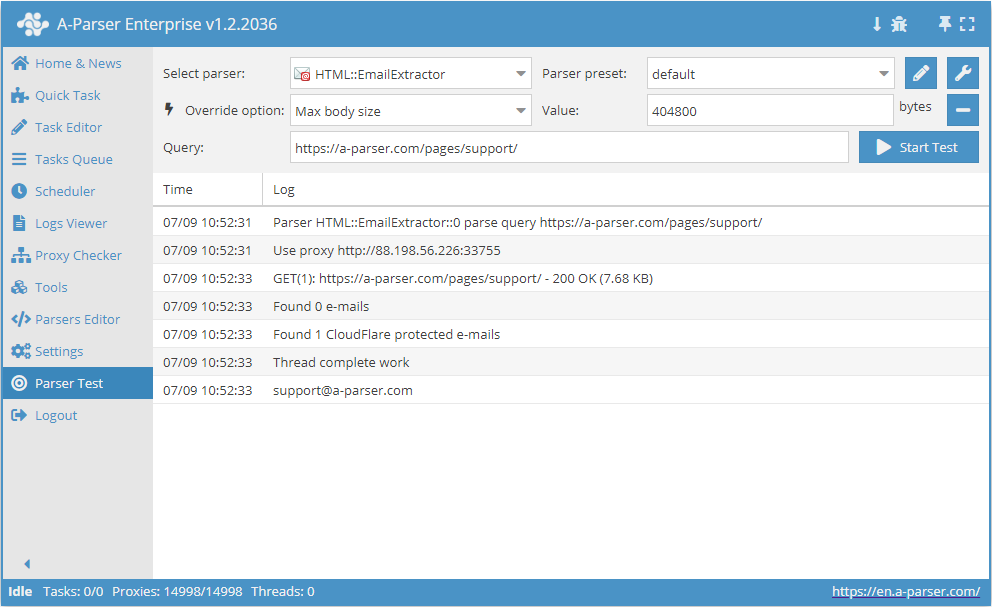
 HTML::EmailExtractor verzamelt e-mailadressen van de opgegeven pagina's. Ondersteunt navigatie door interne pagina's van de site tot een opgegeven diepte, waardoor u alle pagina's van de site kunt doorlopen en interne en externe links kunt verzamelen. De e-mail scraper heeft ingebouwde middelen om de beveiliging van CloudFlare te omzeilen en biedt ook de mogelijkheid om Chrome te kiezen als engine voor het scrapen van e-mails van pagina's waarvan de gegevens door scripts worden geladen. Kan een snelheid bereiken tot 250 verzoeken per minuut – dat zijn 15 000 links per uur.
HTML::EmailExtractor verzamelt e-mailadressen van de opgegeven pagina's. Ondersteunt navigatie door interne pagina's van de site tot een opgegeven diepte, waardoor u alle pagina's van de site kunt doorlopen en interne en externe links kunt verzamelen. De e-mail scraper heeft ingebouwde middelen om de beveiliging van CloudFlare te omzeilen en biedt ook de mogelijkheid om Chrome te kiezen als engine voor het scrapen van e-mails van pagina's waarvan de gegevens door scripts worden geladen. Kan een snelheid bereiken tot 250 verzoeken per minuut – dat zijn 15 000 links per uur.Use cases voor de scraper
E-mails scrapen van een site met diepe paginadoorgang tot een opgegeven limiet
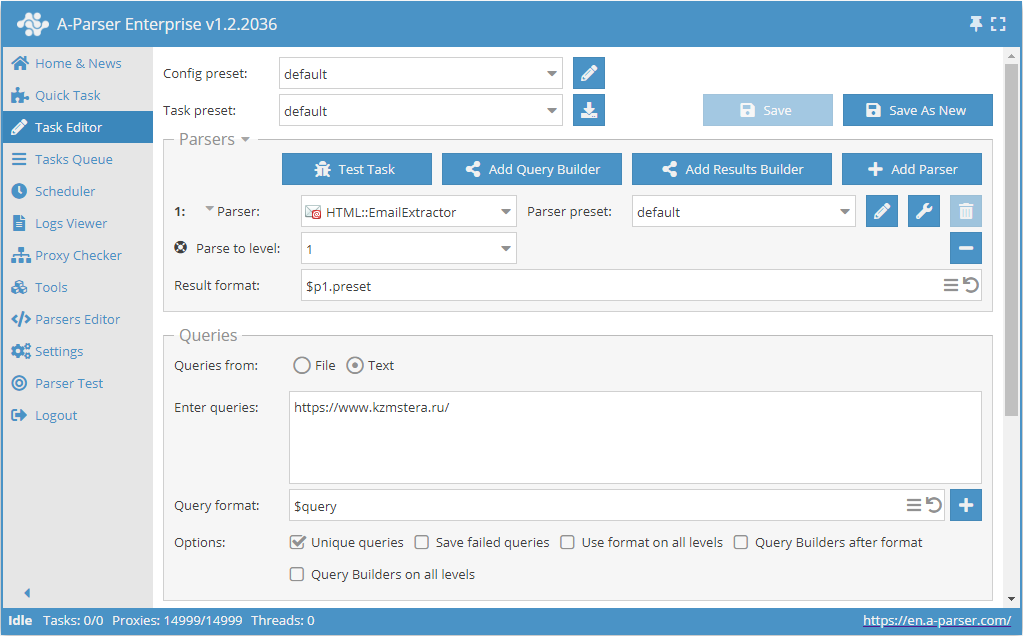
- Voeg de optie Parse to level toe en kies de gewenste waarde (limiet) in de lijst.
- Vink in de sectie Queries de optie
Unique queriesaan. - Vink in de sectie Results de optie
Unique stringaan. - Geef als query de link op naar de website waarvan e-mails gescrapt moeten worden.
Voorbeeld downloaden
Hoe een preset te importeren in A-Parser
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
E-mails scrapen op basis van een lijst met sites met diepe paginadoorgang per site
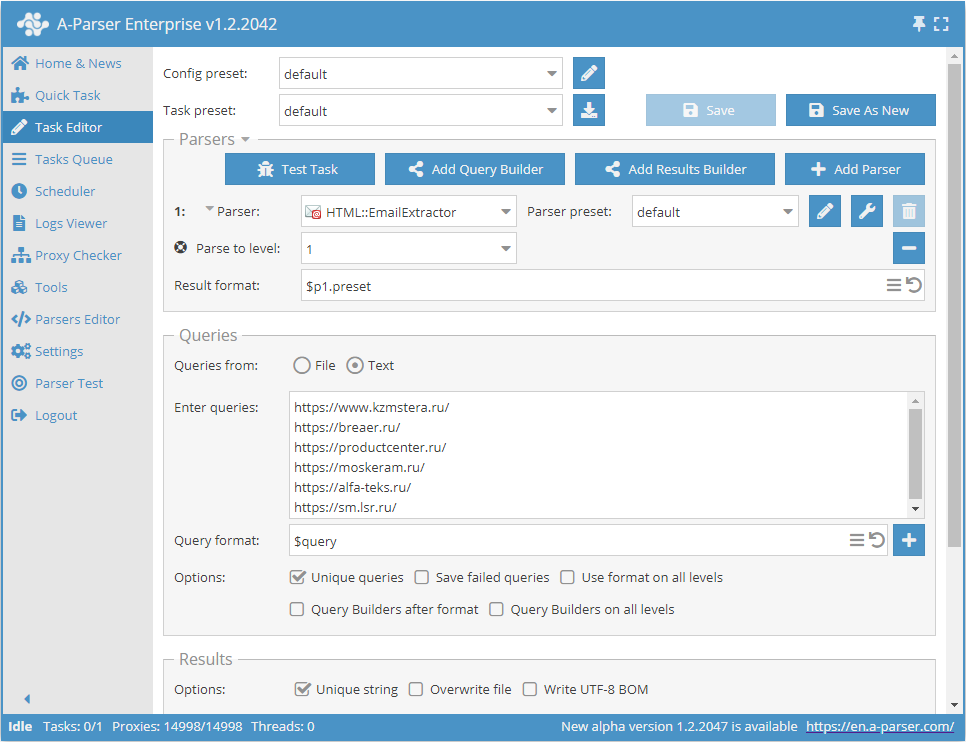
- Voeg de optie Parse to level toe en kies de gewenste waarde (limiet) in de lijst.
- Vink in de sectie Queries de optie
Unique queriesaan. - Vink in de sectie Results de optie
Unique stringaan. - Geef als query de links op naar de websites waarvan e-mails gescrapt moeten worden, of kies bij Queries from voor
Fileen upload een bestand met de lijst met sites.
Voorbeeld downloaden
Hoe een preset te importeren in A-Parser
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
E-mails scrapen op basis van een lijst met links
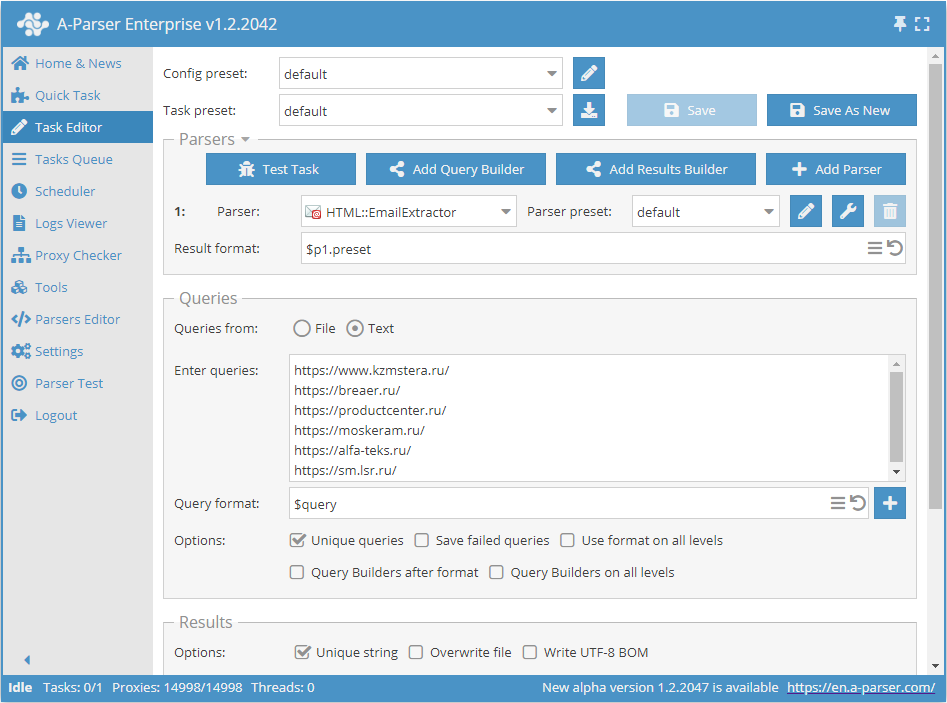
- Vink in de sectie Queries de optie
Unique queriesaan. - Vink in de sectie Results de optie
Unique stringaan. - Geef als query de links op waarvan e-mails gescrapt moeten worden, of kies bij Queries from voor
Fileen upload een bestand met de lijst met links.
Voorbeeld downloaden
Hoe een preset te importeren in A-Parser
eJxtU01z0zAQ/S+aHmAmOPTAxbc00wwwaV3a9BRyEPE6COuLXSkpePLfWTmOHZfe
tG/fvv1UI4Kkmh4QCAKJfN0I375FLkqoZNRBTISXSIDJvRafV3fLPL81Uunbl4By
Gxwy5UzebCaCBfhJC4dGJqErf511qr3zSe5h5dhZKQ0DvGDrXhpIUaUMkLxZ1Qq9
e5+Fl6Qgy1IF5azUpwypriHrs1W/Y4qngMrumM8mKqAFOsNwgFYkgX/OFa7FVWsL
lolt/LdTjMgDRpgI4moX3DGUvaOSmtijAqDkERQ+lcR4I5ydab2EPeiB1srfRKVL
nuOs4qAvXeDblOI/jWPf4WWqPeABuYZepbVuirshqnRLt+PGreO2tTIqsE1zF23a
zUcGawDfj+0+0YxD6NN0yl12PhUPtmTmsLWZH6BRG6PNjMGts5XaFdwAqhLOzGhX
fI+FnTvjNaS+bNSat0LwOFzIjLo1JGMo8HXwvE0xuuTgnKavT6dSPSq+wE+pQMOT
vMzaSW6l1s+Py0uPGC6KjZ8heMqn08PhkNV/DaWlZhin3+3Z8wMl4Bjy6Mq4DVuw
4bXLOKpZwoxRqSv5IUBNY5hMpqkVEKnUADvHN8yDPG76P9v/7Obtn5s3R76RX/Rw
oqeBJjJjvBniAxD59fEfH7B6cg==
Verzameld gegevens
- E-mailadressen
- Totaal aantal adressen op de pagina
- Array met alle verzamelde pagina's (gebruikt bij de optie Use Pages)
Mogelijkheden
- Gegevens verzamelen van meerdere pagina's (navigatie door pagina's)
- Navigatie door interne pagina's van de site tot een opgegeven diepte (optie Parse to level) – hiermee kunt u alle pagina's van de site doorlopen en interne en externe links verzamelen
- Detectie van follow links voor koppelingen
- Limiet voor paginanavigatie (optie Follow links limit)
- Mogelijkheid om subdomeinen als interne pagina's van de site te beschouwen
- Ondersteunt compressie gzip/deflate/brotli
- Detectie en conversie van website-coderingen naar UTF-8
- Omzeilen van CloudFlare-beveiliging
- Keuze van engine (HTTP of Chrome)
- Ondersteuning voor alle functionaliteit van
 HTML::LinkExtractor
HTML::LinkExtractor
Toepassingen
- Scrapen van e-mailadressen
- Weergave van het aantal e-mailadressen
Queries
Als queries moeten links naar pagina's worden opgegeven, bijvoorbeeld:
https://a-parser.com/pages/support/
Voorbeelden van resultaatuitvoer
A-Parser ondersteunt flexibele formattering van resultaten dankzij de ingebouwde sjabloon-engine Template Toolkit, waardoor resultaten in elke gewenste vorm kunnen worden uitgevoerd, inclusief gestructureerde formaten zoals CSV of JSON
Weergave van het aantal e-mailadressen
Resultaatformaat:
$mailcount
Voorbeeld resultaat:
4
Mogelijke instellingen
opmerking
| Naam parameter | Standaardwaarde | Beschrijving |
|---|---|---|
| Good status | All | Selectie van welk antwoord van de server als succesvol wordt beschouwd. Als er tijdens het scrapen een ander antwoord van de server komt, wordt de query herhaald met een andere proxy |
| Good code RegEx | Mogelijkheid om een reguliere expressie op te geven voor het controleren van de responscode | |
| Ban Proxy Code RegEx | Mogelijkheid om proxy's tijdelijk te blokkeren (Proxy ban time) op basis van de serverresponscode | |
| Method | GET | Verzoekmethode |
| POST body | Inhoud om naar de server te sturen bij gebruik van de POST-methode. Ondersteunt variabelen $query – query-URL, $query.orig – oorspronkelijke query en $pagenum - paginanummer bij gebruik van de optie Use Pages. | |
| Cookies | Mogelijkheid om cookies op te geven voor de query. | |
| User agent | _Automatisch ingevuld met de user-agent van de actuele Chrome-versie_ | De User-Agent header bij het opvragen van pagina's |
| Additional headers | Mogelijkheid om aangepaste query-headers op te geven met ondersteuning voor de sjabloon-engine en gebruik van variabelen uit de query-constructor | |
| Read only headers | ☐ | Alleen headers lezen. In sommige gevallen bespaart dit verkeer als het niet nodig is om de inhoud te verwerken |
| Detect charset on content | ☐ | Codering herkennen op basis van de pagina-inhoud |
| Emulate browser headers | ☐ | Browser-headers emuleren |
| Max redirects count | 0 | Maximaal aantal redirects dat de scraper zal volgen |
| Follow common redirects | ☑ | Maakt redirects mogelijk tussen http <-> https en www.domain <-> domain binnen hetzelfde domein, buiten de Max redirects count limiet om |
| Max cookies count | 16 | Maximaal aantal cookies om op te slaan |
| Engine | HTTP (Fast, JavaScript Disabled) | Hiermee kunt u de engine kiezen: HTTP (sneller, zonder JavaScript) of Chrome (langzamer, JavaScript ingeschakeld) |
| Chrome Headless | ☐ | Als deze optie is ingeschakeld, wordt de browser niet weergegeven |
| Chrome DevTools | ☑ | Maakt het gebruik van Chromium-ontwikkeltools mogelijk |
| Chrome Log Proxy connections | ☑ | Als deze optie is ingeschakeld, wordt informatie over Chrome-verbindingen in het logboek weergegeven |
| Chrome Wait Until | networkidle2 | Bepaalt wanneer een pagina als geladen wordt beschouwd. Meer over de waarden. |
| Use HTTP/2 transport | ☐ | Bepaalt of HTTP/2 moet worden gebruikt in plaats van HTTP/1.1. Google en Majestic blokkeren bijvoorbeeld onmiddellijk bij gebruik van HTTP/1.1. |
| Don't verify TLS certs | ☐ | TLS-certificaatvalidatie uitschakelen |
| Randomize TLS Fingerprint | ☐ | Deze optie maakt het mogelijk om blokkades van sites op basis van TLS-fingerprinting te omzeilen |
| Bypass CloudFlare | ☑ | Automatische omzeiling van CloudFlare-controle |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | CF omzeilen via Chrome |
| Bypass CloudFlare with Chrome Max Pages | 20 | Max. aantal pagina's bij het omzeilen van CF via Chrome |
| Subdomains are internal | ☐ | Subdomeinen als interne links beschouwen |
| Follow links | Internal only | Welke links te volgen |
| Follow links limit | 0 | Limiet voor Follow links, toegepast op elk uniek domein |
| Skip comment blocks | ☐ | Commentaarblokken overslaan |
| Search Cloudflare protected e-mails | ☑ | Cloudflare protected e-mails scrapen. |
| Skip non-HTML blocks | ☑ | Geen e-mailadressen verzamelen in tags (script, style, comment, etc.). |
| Skip meta tags | ☐ | Geen e-mailadressen verzamelen in meta-tags |
| Search URL encoded e-mails | ☐ | Verzamelen van URL-gecodeerde e-mails |