SE::Yandex::Position - Websiteposities controleren op trefwoorden in Yandex
Overzicht van de scraper
Scraper voor het controleren van websiteposities op trefwoorden in Yandex. Dankzij de SE::Yandex::Position scraper kunt u automatisch posities in de zoekresultaten van Yandex controleren met uw eigen domeindatabases. Met de SE::Yandex::Position scraper kunt u eenvoudig, nauwkeurig en snel de positie van een website in Yandex bepalen. Het controleren van posities in Yandex gebeurt in multithreading-modus, met de mogelijkheid om captcha-oplossingsdiensten te gebruiken (AntiCaptcha of elke andere dienst die hun API ondersteunt). De Yandex positie-scraper is altijd actueel, omdat deze regelmatig wordt bijgewerkt door onze specialisten.
De functionaliteit van A-Parser stelt u in staat om de instellingen voor gegevensextractie van de SE::Yandex::Position scraper op te slaan voor toekomstig gebruik (presets), extractieschema's in te stellen en nog veel meer. U kunt automatische substitutie van subquery's uit bestanden gebruiken.
Het opslaan van resultaten is mogelijk in de vorm en structuur die u nodig heeft, dankzij de ingebouwde krachtige sjabloon-engine Template Toolkit waarmee u extra logica op de resultaten kunt toepassen en gegevens in verschillende formaten kunt uitvoeren, waaronder JSON, SQL en CSV.
Toepassingen van de scraper
🔗 Overzicht van weergaveopties
In dit artikel worden 4 verschillende opties voor resultaatweergave behandeld: tekst, CSV, JSON, HTML
🔗 ⏩Posities voor meerdere regio's
Websiteposities gelijktijdig ophalen voor meerdere regio's
Verzamelde gegevens
- Websitepositie en de link naar de websitepagina
- Lijst van alle websiteposities en links naar pagina's
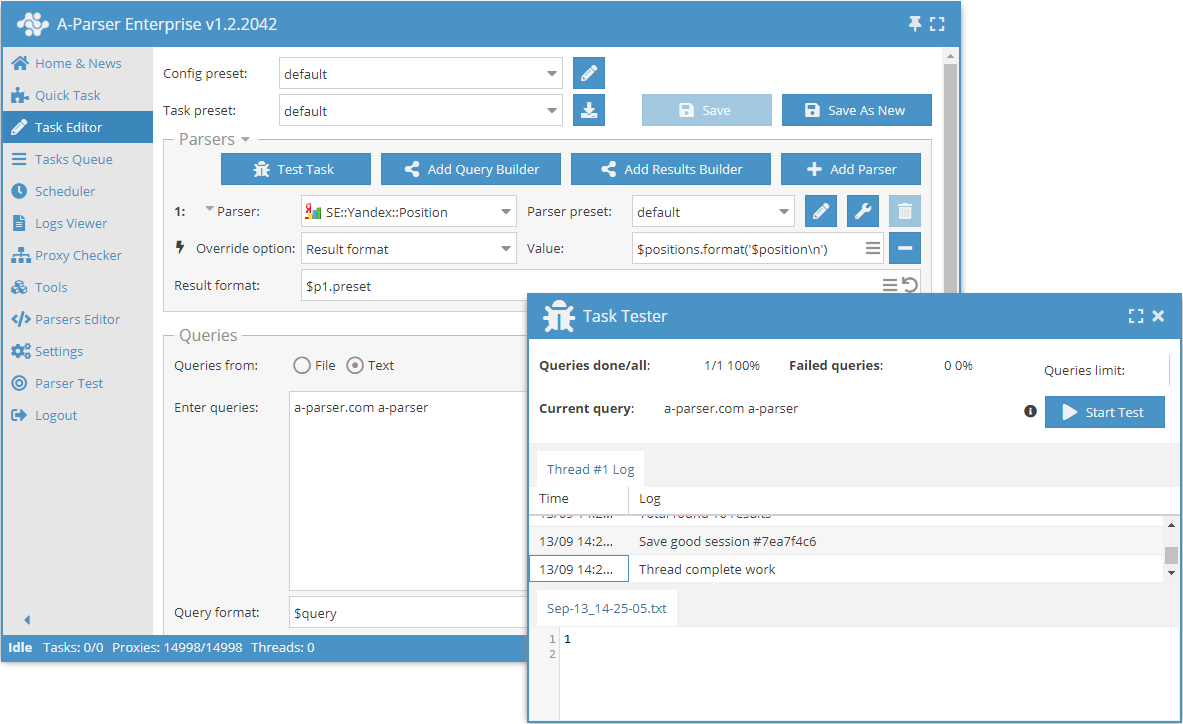
Mogelijkheden
- Alle mogelijkheden van de scraper
 SE::Yandex
SE::Yandex - Stopt automatisch de gegevensextractie zodra de website is gevonden
- Ondersteunt het zoeken naar subdomeinen
- Mogelijkheid om de gezochte positie te vergelijken op domein, hoofddomein en volledige link
- Posities verzamelen voor meerdere domeinen tegelijk
Gebruiksscenario's
- Controleren van posities van eigen websites en die van concurrenten
- Zoeken naar pagina's met veel verkeer
Query's
Als query's moet u het domein van de gezochte website en de zoekopdracht opgeven, gescheiden door een spatie, bijvoorbeeld:
lenta.ru nieuws
lenta.ru nieuws online
Als u één website wilt controleren op een lijst met query's, kunt u het domein opgeven in het query-formaat (Query format):
lenta.ru $query
Of gebruik gewoon een lijst met trefwoorden. Om meerdere domeinen tegelijk in een query te gebruiken, moet u een lijst met domeinen opgeven gescheiden door komma's en na een spatie het trefwoord, bijvoorbeeld:
lenta.ru,ria.ru,notfound.com nieuws feed
De resultaten worden opgeslagen in de array $bulkcheck.
De optie Stop when found wordt ook ondersteund; de gegevensextractie eindigt als voor alle domeinen posities zijn gevonden.
Query-substituties
U kunt ingebouwde macro's gebruiken voor automatische substitutie van subquery's uit bestanden. Stel dat we websites/een website willen controleren tegen een database met trefwoorden, dan geven we enkele hoofddomeinen op:
ria.ru
lenta.ru
rbc.ru
yandex.ru
In het query-formaat geven we de macro op voor het invoegen van extra woorden uit het bestand Keywords.txt. Deze methode maakt het mogelijk om een database van websites te controleren tegen een database van trefwoorden en als resultaat de posities te verkrijgen:
$query {subs:Keywords}
Deze macro zal voor elke oorspronkelijke zoekopdracht evenveel extra query's aanmaken als er in het bestand staan, wat in totaal resulteert in [aantal oorspronkelijke query's (domeinen)] x [aantal query's in bestand Keywords] = [totaal aantal query's] als resultaat van de macro.
Varianten voor resultaatuitvoer
A-Parser ondersteunt flexibele formattering van resultaten dankzij de ingebouwde sjabloon-engine Template Toolkit, waardoor resultaten in elke gewenste vorm kunnen worden uitgevoerd, evenals in gestructureerde formaten zoals CSV of JSON.
Export van de positielijst
Resultaat verkrijgen in de vorm van:
gezocht domein - trefwoord: positienummer in de zoekresultaten
Resultaatformaat:
$domain - $key: $position\n
Voorbeeld van resultaat:
lenta.ru - nieuws: 3
lenta.ru - nieuws online: 13
...
Gelijktijdige controle van meerdere domeinen (batchcontrole)
Informatie over alle domeinen bij een gelijktijdige controle van meerdere domeinen bevindt zich in de array $bulkcheck.
Resultaatformaat:
$bulkcheck.format('$domain - $position\n')
Voorbeeld van een query:
lenta.ru,ria.ru,notfound.com nieuws feed
Voorbeeld van resultaat:
lenta.ru - 1
ria.ru - 4
notfound.com - 0
Links + ankers + snippets met positieweergave
Uitvoer van links, ankers en snippets in een CSV-tabel
Gerelateerde trefwoorden opslaan
Trefwoordconcurrentie
Indexeringscontrole van links
Opslaan in SQL-formaat
Resultaten dumpen naar JSON
Resultaatverwerking
A-Parser maakt het mogelijk om resultaten direct tijdens de gegevensextractie te verwerken. In dit gedeelte hebben we de meest populaire scenario's voor de SE::Yandex::Position scraper verzameld.
Domeinen opslaan zonder nulposities
Als basis is het voorbeeld van de gelijktijdige controle van meerdere domeinen genomen (zie hierboven bij de uitvoervarianten) en is er een filter toegevoegd.
Voeg een filter toe en kies in de vervolgkeuzelijst de uitvoervariabele voor de positie. Kies type: >. Vul vervolgens bij Number (Getal) 0 in. Met dit filter kunt u alle resultaten met een nulpositie verwijderen.
Voorbeeld downloaden
Hoe een voorbeeld te importeren in A-Parser
eJx1VE1v2zAM/SuGEKAr4AXJ1gKDDwPSYAE2dE3Xj8OQ5KBGdKtFFj1JTpsF/u+j
ZNlOuu4im9Qj+fhEac8ctxt7bcCCsyxb7FkZ/lnGbr9k2U+uBbxk2TVa6STq5H1y
y7eQCCy41DZ5lu4JK5fw5A8YTMoIYykrubFgfMrFm5kIIiDnlXIs3TO3K4FK4haM
kQJoUwqyczQFd0QowNiWq8rDBg+V2qyfYL0ZNoh3J4OGEfEbtCSWS31yyur/Z68s
lAZfdn3mnCsLBxG5VA4M7UcK2YJ1pX2PbS+rNELvmrjPB2RH9I9lgGXMgrasXq3a
jHYW+PueyvEwSt9teqnvsOEBvXtG1hUvghKCO/C7rRCnQ/fiM3AhAjWumgr+IPqq
91r+DuQ0EpZ+jQQ7M1iQy0FI4J27lt2CDYLtG61C7I8mJkqWMktUZ5yIiNc7kmTh
Ds08aED+PUM9UeoStqB6WMh/UUklaGomOQV9jYFvQ+b/5Ki79g5L0Zk/G+LQZQnW
xfx7HyXwEh+pc/FAfStZSEe2nWKlXTy/DUDZaXblNSvQQFcmZo7V6TKVoP2A9Uc2
KXvXURtHx3LsXKPO5eM8Dm2LrPQd3di5nmJRKvB96Uqp1A/zTT8eExuPwRs9wdfB
01DCt95eReYQlf1221AtjaTxO/cEC1LysGpMueZK3d9cHu6wfqTIUKAdH5oqNTJ8
NLqclBXDNRbJshqdfRRhhbB+6P/PxmFtPJ8a6ENYz/uwuD1a+vdkTXfhEWlKSal6
1T1B3eO2f/shyvY1DcEve93AvWIeTD6S3gbEuP4LmbnKEA==
Zie ook: Resultaatfilters
Deduplicatie van links
Deduplicatie van links per domein
Domeinen extraheren
Tags verwijderen uit ankers en snippets
Links filteren op basis van trefwoord
Mogelijke instellingen
Ondersteunt alle instellingen van de scraper SE::Yandex, evenals extra:
| Parameter-naam | Standaardwaarde | Beschrijving |
|---|---|---|
| Pages count | 1 | Aantal te scrapen pagina's met zoekresultaten (van 1 tot 25) |
| Links per page | 20 | Aantal links per pagina in de zoekresultaten (10 / 20 / 30 / 50) |
| Result format | $domain - $key: $position\n | Standaardformaat voor resultaatuitvoer |
| Stop when found | ☑ | Gegevensextractie stoppen als het domein is gevonden, gaat niet verder naar de volgende pagina's |
| Match type | Exact domain | Mogelijkheid om de gezochte positie te vergelijken op domein, op hoofddomein en op volledige link (Exact domain / Top level domain / Exact url) |