SE::Google::KeywordPlanner::Ideas - Parser für Keyword-Ideen aus dem Google Keyword Planner
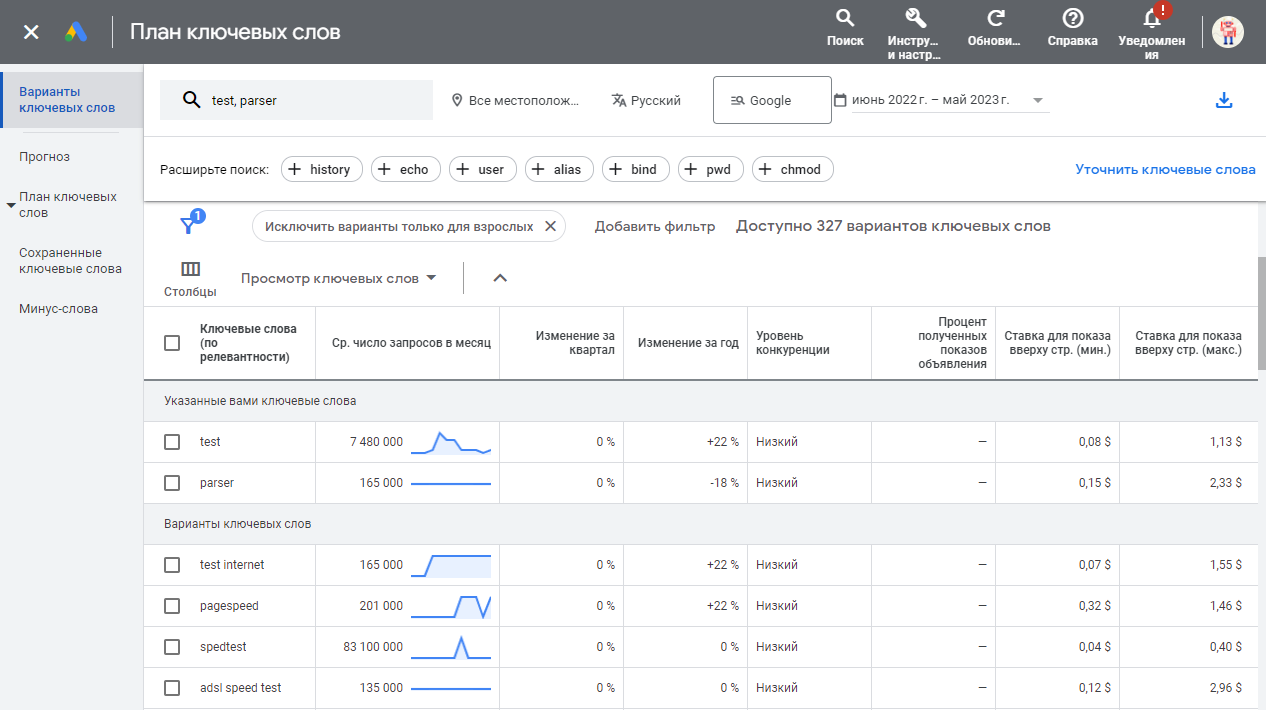
Übersicht des Parsers
 SE::Google::KeywordPlanner::Ideas – Datenerfassung von Keyword-Varianten und Vorschlägen aus dem Google Keyword Planner. Für die Nutzung stehen zahlreiche Daten zur Verfügung: Erfassung von Vorschlagslisten, Bewertung des Wettbewerbs für Keywords, Abruf des durchschnittlichen monatlichen Suchvolumens, minimale und maximale Gebote sowie die Suche nach neuen Keywords zu ähnlichen Themen. In den Einstellungen der Datenerfassung können Sie Sprache, Region, Standort und den Zeitraum der Datenauswahl festlegen. Zudem ist ein Batch-Modus verfügbar, mit dem pro Anfrage an den Dienst Daten für bis zu 20 Keywords gleichzeitig abgerufen werden können, was die Datenerfassung erheblich beschleunigt.
SE::Google::KeywordPlanner::Ideas – Datenerfassung von Keyword-Varianten und Vorschlägen aus dem Google Keyword Planner. Für die Nutzung stehen zahlreiche Daten zur Verfügung: Erfassung von Vorschlagslisten, Bewertung des Wettbewerbs für Keywords, Abruf des durchschnittlichen monatlichen Suchvolumens, minimale und maximale Gebote sowie die Suche nach neuen Keywords zu ähnlichen Themen. In den Einstellungen der Datenerfassung können Sie Sprache, Region, Standort und den Zeitraum der Datenauswahl festlegen. Zudem ist ein Batch-Modus verfügbar, mit dem pro Anfrage an den Dienst Daten für bis zu 20 Keywords gleichzeitig abgerufen werden können, was die Datenerfassung erheblich beschleunigt.Dank der Multithreading-Funktionalität von A-Parser kann die Geschwindigkeit der Abfrageverarbeitung mehrere tausend Anfragen pro Minute erreichen.
Die Funktionalität von A-Parser ermöglicht es, die Einstellungen für die Datenerfassung des Parsers SE::Google::KeywordPlanner::Ideas für die spätere Verwendung zu speichern (Presets), Zeitpläne für die Datenerfassung festzulegen und vieles mehr.
Das Speichern der Ergebnisse ist in jeder gewünschten Form und Struktur möglich, dank der integrierten leistungsstarken Template-Engine Template Toolkit, die es ermöglicht, zusätzliche Logik auf die Ergebnisse anzuwenden und Daten in verschiedenen Formaten auszugeben, einschließlich JSON, SQL und CSV.
Gesammelte Daten
- Durchschnittliche Anzahl der monatlichen Suchanfragen für das gesuchte Keyword
- Listen mit Vorschlägen
- Keyword-Varianten
- Durchschnittliche monatliche Suchanfragen
- Wettbewerb
- Minimale und maximale Gebote
- Trends für jede erhaltene Variante
Funktionen
- Unterstützung der Authentifizierung über Login/Passwort oder durch Einsetzen von Cookies und Headern
- Bestimmung der Genauigkeitsstufe von $volume - exakter/gerundeter Wert
- Paketmodus wird unterstützt, Details im Abschnitt Queries (Abfragen)
- Unterstützung für Multi-Accounts (zur Auswahl des richtigen Accounts muss dessen
ocid(uscid)angegeben werden) - Datenerfassung der Suchvolumina für jedes Keyword auf monatlicher Basis für den angegebenen Zeitraum (
$ideas.$i.trends). Die Daten werden in JSON bereitgestellt, ein Beispiel für deren Ausgabe im Ergebnis finden Sie im Screenshot unten:
Spoiler: Screenshot
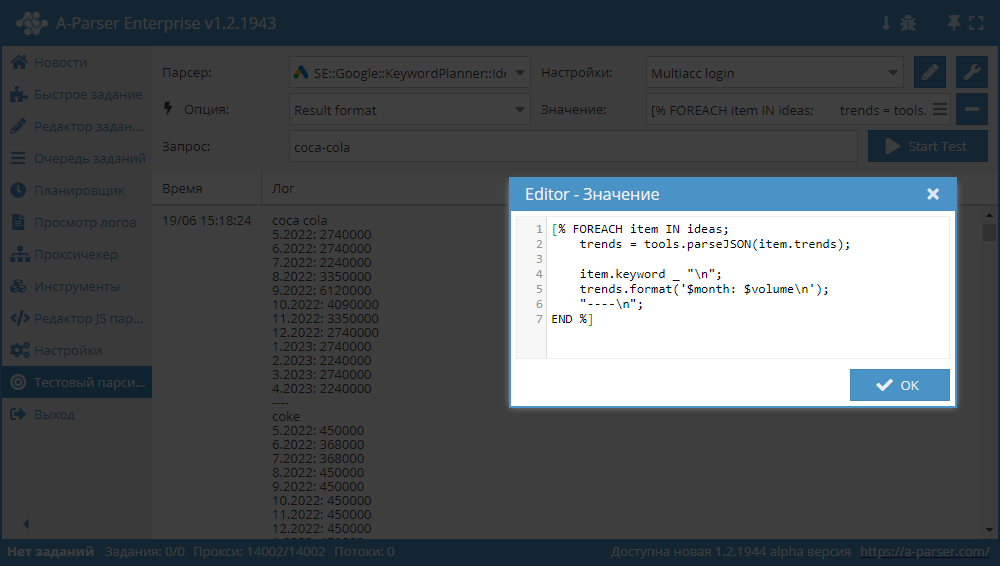
Template:
[% FOREACH item IN ideas;
trends = tools.parseJSON(item.trends);
item.keyword _ "\n";
trends.format('$month: $volume\n');
"----\n";
END %]
Anwendungsfälle
- Datenerfassung von Vorschlagslisten
- Bewertung des Wettbewerbs für Keywords
- Erfassung der durchschnittlichen monatlichen Suchanfragen, minimaler und maximaler Gebote
- Suche nach neuen Keywords zu ähnlichen Themen
Konfiguration
Es gibt zwei Möglichkeiten, den Parser zu konfigurieren:
- E-Mail/Passwort des Keyword Planner-Accounts angeben
- Im Browser anmelden und die erforderlichen Werte kopieren
Seien Sie vorsichtig mit der Anzahl der Threads. Es wird empfohlen, eine geringe Anzahl von Threads anzugeben; dabei ist eine Datenerfassung ohne Proxy durchaus möglich.
Authentifizierung über E-Mail und Passwort
Sie müssen die Optionen E-mail und Password überschreiben und die Daten Ihres Keyword Planner-Accounts angeben. Im Account muss zwingend eine Kampagne erstellt worden sein.
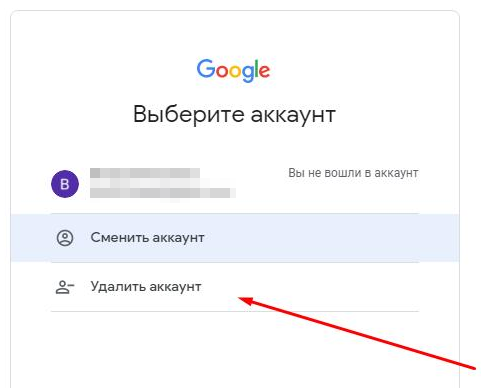
Spoiler: (Lösung) Login failed TypeError: Cannot read property '1' of null
Falls dieser Fehler auftritt, müssen Sie Ihr Google-Konto aus dem Browser löschen und sich erneut anmelden.
Authentifizierung im Browser und Einsetzen von Headern in den Parser
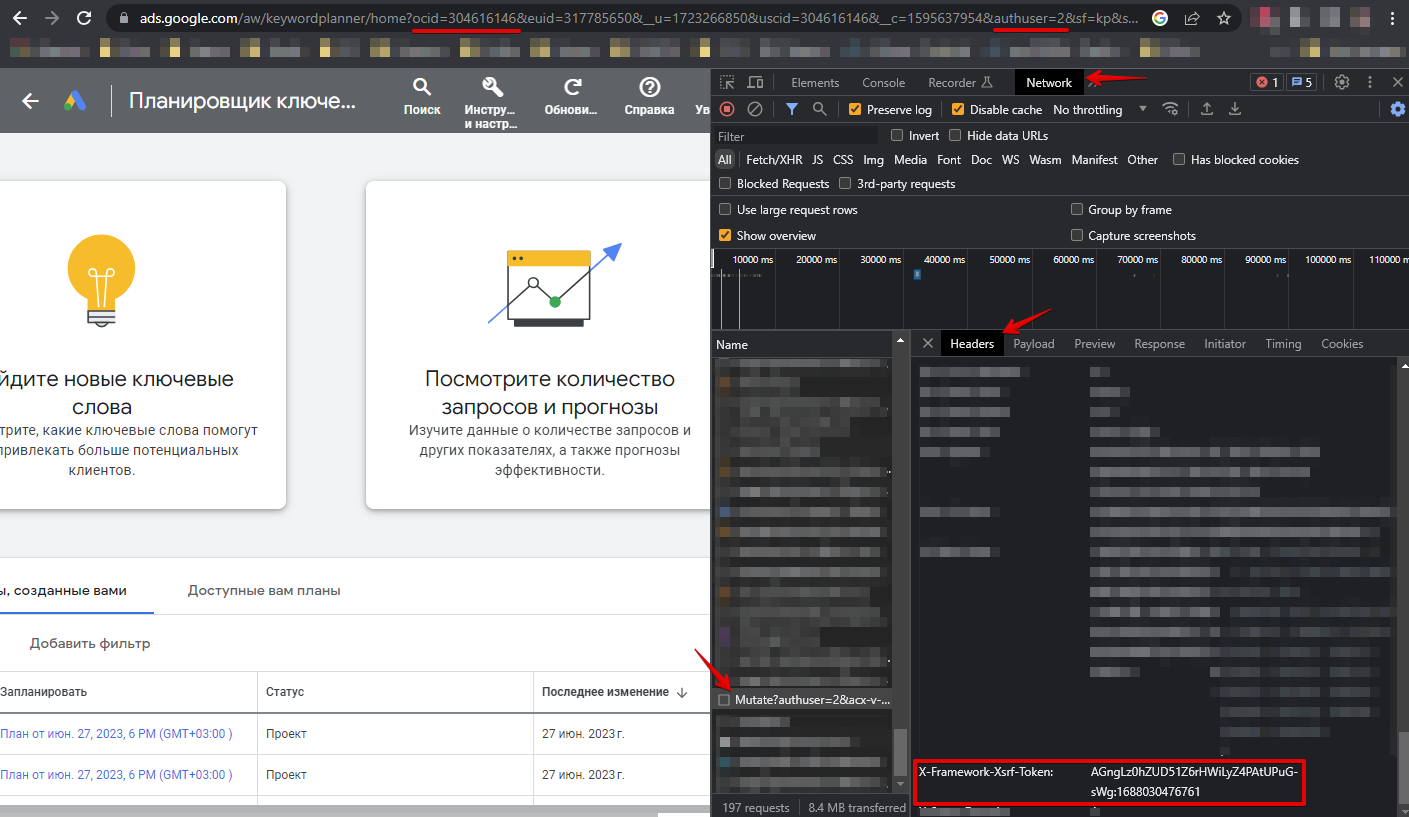
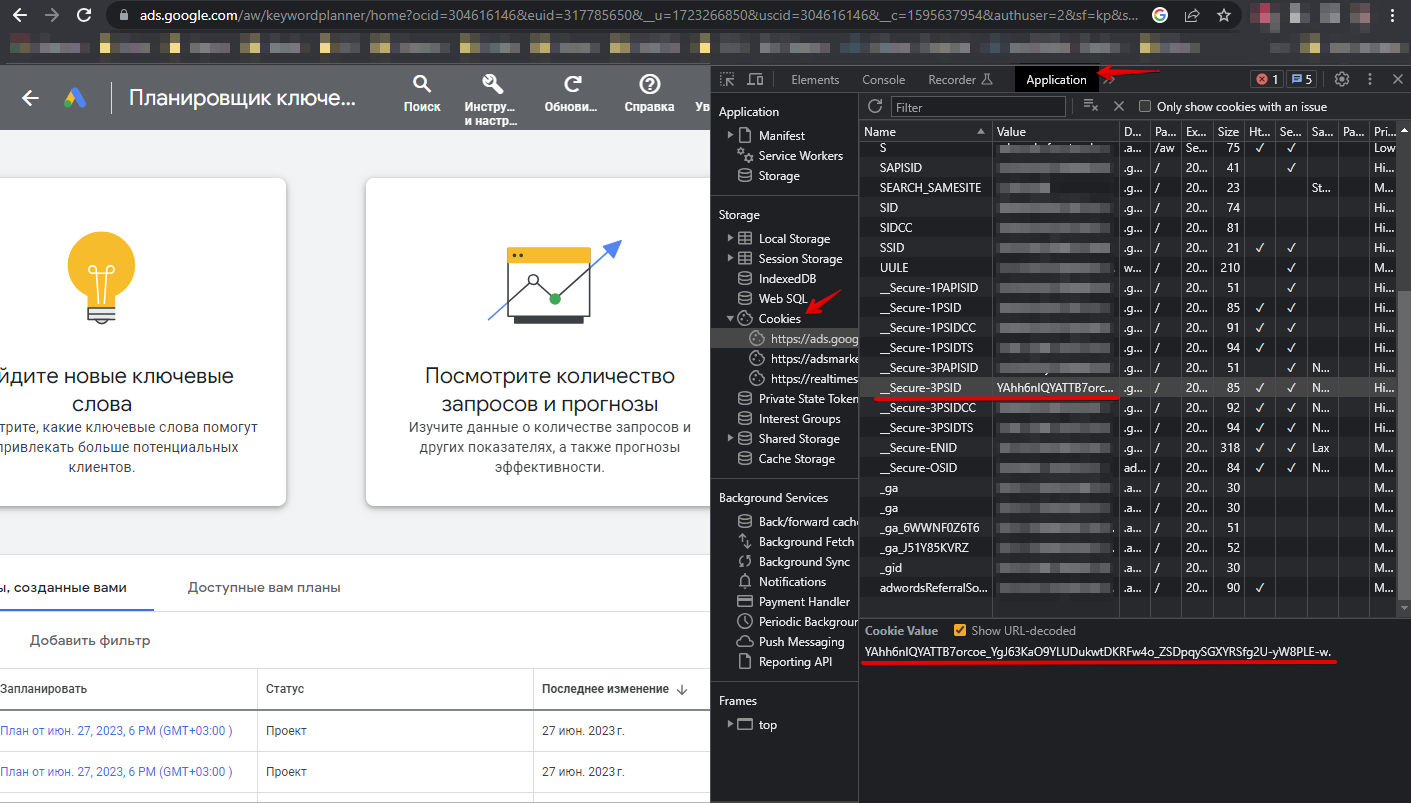
Sie müssen sich im Browser unter dem Link https://ads.google.com/aw/keywordplanner/home anmelden, die erste Kampagne erstellen (falls noch nicht geschehen), die folgenden Daten entnehmen und in den Parser-Einstellungen angeben:
Cookies können auf zwei Arten angegeben werden:
- Alle Cookies in der Option All cookies angeben
- Werte aus den Cookies für die Optionen __Secure-3PSID, __Secure-3PSIDTS angeben (__Secure-3PSIDTS muss angegeben werden, wenn authuser im Account 0 ist)
Weitere Header:
- Wert des Headers x-framework-xsrf-token
- Wert des Parameters ocid oder uscid aus der URL
- Wert des Parameters authuser aus der URL
Spoiler: So finden Sie die benötigten Parameter
Abfragen
Je nach Wert des Parameters Query type können die Abfragen unterschiedlich aussehen. Im Folgenden sind die möglichen Varianten aufgeführt, Beispiele gezeigt und Besonderheiten der erhaltenen Ergebnisse beschrieben.
Keyword
Abfragen müssen in Form von Keywords vorliegen, ein Keyword pro Zeile. Beispiel für Abfragen:
test
parser
Windows 11
wie man einen Baum züchtet
Der Paketmodus wird unterstützt, der über die Option Bulk (packet) mode aktiviert wird. In diesem Modus sendet der Parser Pakete von 20 Keywords in einer Anfrage an den Dienst, wodurch sich die Logik der Ergebnisbefüllung ändert:
$volumewird für jedes Keyword ausgefüllt$ideasund$suggestswerden nur für das erste Keyword ausgefüllt, aber diese Arrays enthalten alle Ergebnisse kumuliert für alle Keywords, die in diesem Paket verwendet wurden
Site + keyword
Abfragen müssen in Form einer Website und eines durch ein Leerzeichen getrennten Keywords vorliegen. Beispiel für Abfragen:
speedtest.com Network speed
a-parser.com parser
Ebenfalls wird der Paketmodus unterstützt; um diesen zu nutzen, müssen die Keywords durch Kommata getrennt werden, Beispiel:
4pda.to android,ios,Firmware
google.com google,ads,Werbung,Suche nach Websites im Internet
$volumewird für diesen Abfragetyp im Paketmodus nicht erfasst
Entire site
Als Abfragen müssen Domains angegeben werden, eine pro Zeile. Zum Beispiel:
apple.com
microsoft.com
$volumewird für diesen Abfragetyp nicht erfasst
URL
Als Abfragen müssen Links angegeben werden, einer pro Zeile. Zum Beispiel:
https://a-parser.com/docs/parsers/se-google-keywordplanner
https://developer.mozilla.org/en-US/docs/Learn/Getting_started_with_the_web/JavaScript_basics
$volumewird für diesen Abfragetyp nicht erfasst
Abfragesubstitutionen
Sie können integrierte Makros für die automatische Ersetzung von Unterabfragen aus Dateien verwenden. Wenn wir beispielsweise zu jeder Abfrage eine Liste anderer Wörter hinzufügen möchten, geben wir einige Hauptabfragen an:
fantasy
tower defense
rpg
Im Abfrageformat geben wir das Makro zur Ersetzung zusätzlicher Wörter aus der Datei keywords.txt an. Diese Methode ermöglicht es, die Variabilität der Abfragen um ein Vielfaches zu erhöhen:
{subs:keywords} $query
Dieses Makro erstellt für jede ursprüngliche Suchanfrage so viele zusätzliche Abfragen, wie in der Datei enthalten sind, was in der Summe [Anzahl der ursprünglichen Abfragen] x [Anzahl der Abfragen in der Datei Keywords] = [Gesamtanzahl der Abfragen] als Ergebnis der Makroarbeit ergibt.
Wenn die Datei keywords.txt beispielsweise Folgendes enthält:
free
online
Am Ende verwandelt das Substitutionsmakro 3 Hauptabfragen in 6:
free fantasy
online fantasy
free tower defense
online tower defense
free rpg
online rpg
Beispiele für die Ergebnisausgabe
A-Parser unterstützt eine flexible Formatierung der Ergebnisse dank der integrierten Template-Engine Template Toolkit, was es ermöglicht, Ergebnisse in beliebiger Form sowie strukturiert, zum Beispiel als CSV oder JSON, auszugeben.
Standardausgabe
Ergebnisformat:
$ideas.format('$keyword\n')
Beispielergebnis:
coca cola
iphone 11 pro
winter
iphone 11 pro max
winter season
iphone11
iphone 11 price
apple iphone 11
iphone 11pro
coke
11 pro max
iphone 11 pro price
iphone 11 max
iphone pro max
iphone 11 128gb
11 pro
iphone 11 pro max price
apple iphone 11 pro
apple iphone 11 pro max
new iphone 11
iphone 11 max pro
apple 11 pro
iphone 11 deals
iphone 11 pro max 256gb
diet coke
first day of winter
iphone 11 pro 256gb
coke zero
iphone pro 11
apple 11 pro max
Ausgabe in eine CSV-Tabelle
Ergebnisformat:
[% FOREACH i IN ideas;
tools.CSVline(i.keyword, i.volume, i.min_bid, i.max_bid);
END %]
Dateiname:
$datefile.format().csv
Anfangstext:
Keyword,Volume,"Min bid","Max bid"
Im Ergebnisformat wird die Template-Engine Template Toolkit verwendet, um das Array $ideas in einer FOREACH-Schleife auszugeben.
Im Dateinamen der Ergebnisse müssen Sie lediglich die Dateiendung in csv ändern.
Damit die Option "Prepend text" im Task-Editor verfügbar ist, müssen Sie "More options" aktivieren. In den "Prepend text" schreiben wir die Spaltennamen durch Kommata getrennt und lassen die zweite Zeile leer.
Speichern im SQL-Format
Ergebnisformat:
[% FOREACH ideas;
"INSERT INTO ideas VALUES('" _ keyword _ "', '" _ volume _ "')\n";
END %]
Beispielergebnis:
INSERT INTO ideas VALUES('Parfüm', '50000')
INSERT INTO ideas VALUES('eyfel perfume', '5000')
INSERT INTO ideas VALUES('memo marfa', '5000')
INSERT INTO ideas VALUES('duxi', '5000')
INSERT INTO ideas VALUES('kenzo intense', '5000')
INSERT INTO ideas VALUES('climat lancome', '5000')
INSERT INTO ideas VALUES('v canto', '5000')
INSERT INTO ideas VALUES('majda bekkali', '5000')
INSERT INTO ideas VALUES('v canto ricina', '500')
INSERT INTO ideas VALUES('v canto stramonio', '5000')
INSERT INTO ideas VALUES('terenzi kirke', '500')
INSERT INTO ideas VALUES('duhi', '500')
INSERT INTO ideas VALUES('max mara le parfum', '500')
INSERT INTO ideas VALUES('stramonio v canto', '500')
INSERT INTO ideas VALUES('sheikh parfum', '500')
INSERT INTO ideas VALUES('jacques zolty', '500')
INSERT INTO ideas VALUES('aj arabia', '500')
INSERT INTO ideas VALUES('christian lacroix bazar', '500')
INSERT INTO ideas VALUES('juliette has a gun romantina', '500')
INSERT INTO ideas VALUES('vilhelm parfumerie mango skin', '500')
INSERT INTO ideas VALUES('v canto mirabile', '500')
INSERT INTO ideas VALUES('donna karan dkny be delicious', '500')
INSERT INTO ideas VALUES('arteolfatto', '500')
INSERT INTO ideas VALUES('aquawoman rochas', '500')
INSERT INTO ideas VALUES('angel and demon givenchy', '500')
INSERT INTO ideas VALUES('venenum kiss', '500')
INSERT INTO ideas VALUES('v canto mandragola', '500')
INSERT INTO ideas VALUES('angel demon givenchy', '500')
INSERT INTO ideas VALUES('hugo boss boss ma vie pour femme', '500')
INSERT INTO ideas VALUES('nina ricci mademoiselle ricci', '500')
Dump der Ergebnisse in JSON
Allgemeines Ergebnisformat:
[% data = [];
FOREACH p1.ideas;
item = {};
item.keyword = keyword;
item.volume = volume;
data.push(item);
END %]$data.json\n
Beispielergebnis:
[{"keyword":"Parfüm","volume":"50000"},{"keyword":"eyfel perfume","volume":"5000"},{"keyword":"memo marfa","volume":"5000"},{"keyword":"duxi","volume":"5000"},{"keyword":"kenzo intense","volume":"5000"},{"keyword":"climat lancome","volume":"5000"},{"keyword":"v canto","volume":"5000"},{"keyword":"majda bekkali","volume":"5000"},{"keyword":"v canto ricina","volume":"500"},{"keyword":"v canto stramonio","volume":"5000"},{"keyword":"terenzi kirke","volume":"500"},{"keyword":"duhi","volume":"500"},{"keyword":"max mara le parfum","volume":"500"},{"keyword":"stramonio v canto","volume":"500"},{"keyword":"sheikh parfum","volume":"500"},{"keyword":"jacques zolty","volume":"500"},{"keyword":"aj arabia","volume":"500"},{"keyword":"christian lacroix bazar","volume":"500"},{"keyword":"juliette has a gun romantina","volume":"500"},{"keyword":"vilhelm parfumerie mango skin","volume":"500"},{"keyword":"v canto mirabile","volume":"500"},{"keyword":"donna karan dkny be delicious","volume":"500"},{"keyword":"arteolfatto","volume":"500"},{"keyword":"aquawoman rochas","volume":"500"},{"keyword":"angel and demon givenchy","volume":"500"},{"keyword":"venenum kiss","volume":"500"},{"keyword":"v canto mandragola","volume":"500"},{"keyword":"angel demon givenchy","volume":"500"},{"keyword":"hugo boss boss ma vie pour femme","volume":"500"},{"keyword":"nina ricci mademoiselle ricci","volume":"500"},{"keyword":"mmmm juliette has a gun","volume":"500"},{"keyword":"v canto lucrethia","volume":"500"},{"keyword":"mango skin vilhelm parfumerie","volume":"500"},{"keyword":"dalissime salvador dali","volume":"500"},{"keyword":"molecula 02","volume":"50000"},{"keyword":"lucia parfum","volume":"500"},{"keyword":"boadicea pure narcotic","volume":"500"},{"keyword":"terenzi andromeda","volume":"500"}]
Details zur Ausgabe der Ergebnisse in JSON sind in diesem Artikel beschrieben.
Mögliche Einstellungen
| Parameter | Standardwert | Beschreibung |
|---|---|---|
| All cookies | Angabe aller Cookies | |
| Cookie "__Secure-3PSID" | Cookie "__Secure-3PSID" | |
| Cookie "__Secure-3PSIDTS" | Cookie "__Secure-3PSIDTS" | |
| Header "x-framework-xsrf-token" | Header "x-framework-xsrf-token" | |
| Url parameter "ocid"("uscid") | Parameter "ocid"("uscid") | |
| Url parameter "authuser" | 0 | Parameter "authuser" |
| E-Mail zur Authentifizierung im Keyword Planner | ||
| Password | Passwort zur Authentifizierung im Keyword Planner | |
| Recovery e-mail | E-Mail zur Wiederherstellung des Zugangs | |
| Browser headless (debug auth) | ☑ | Headless-Modus für den Browser, der für die Authentifizierung über Login/Passwort verwendet wird |
| Log Login Screenshot (debug auth) | ☐ | Erstellung eines Screenshots der Authentifizierungsseite und Ausgabe im Aufgaben-Log |
| Date from | Last 12 months | Datum von |
| Date to | Last 12 months | Datum bis |
| Language | English | Sprache |
| Search networks | Google | Suchnetzwerk |
| Currency | USD | Währung |
| Location code | Standort (hier muss die Standort-ID angegeben werden, diese kann der ersten Spalte dieser Tabelle (Kopie) entnommen werden) | |
| Query type | Keyword | Abfragetyp |
| Exclude brand names in results | ☐ | Markenfilter |
| Exclude adult ideas | ☑ | Filter für Inhalte für Erwachsene |
| Bulk (packet) mode | ☐ | Aktivierung des Paketmodus |