HTML::TextExtractor - Gegevensextractie van content (tekst) van websites
Overzicht van de scraper
 HTML::TextExtractor scrapt tekstblokken van de opgegeven pagina. Deze content-scraper ondersteunt paginanavigatie (doorbladeren van pagina's). Heeft ingebouwde middelen voor het omzeilen van beveiliging CloudFlare en ook de mogelijkheid om te kiezen voor Chrome als engine voor het scrapen van content van pagina's waarvan de gegevens via scripts worden geladen. Kan een snelheid bereiken tot 2000 verzoeken per minuut – dat zijn 120 000 links per uur.
HTML::TextExtractor scrapt tekstblokken van de opgegeven pagina. Deze content-scraper ondersteunt paginanavigatie (doorbladeren van pagina's). Heeft ingebouwde middelen voor het omzeilen van beveiliging CloudFlare en ook de mogelijkheid om te kiezen voor Chrome als engine voor het scrapen van content van pagina's waarvan de gegevens via scripts worden geladen. Kan een snelheid bereiken tot 2000 verzoeken per minuut – dat zijn 120 000 links per uur.Toepassingen van de scraper
Tekst extraheren via Chrome aan de hand van lingualeo.com
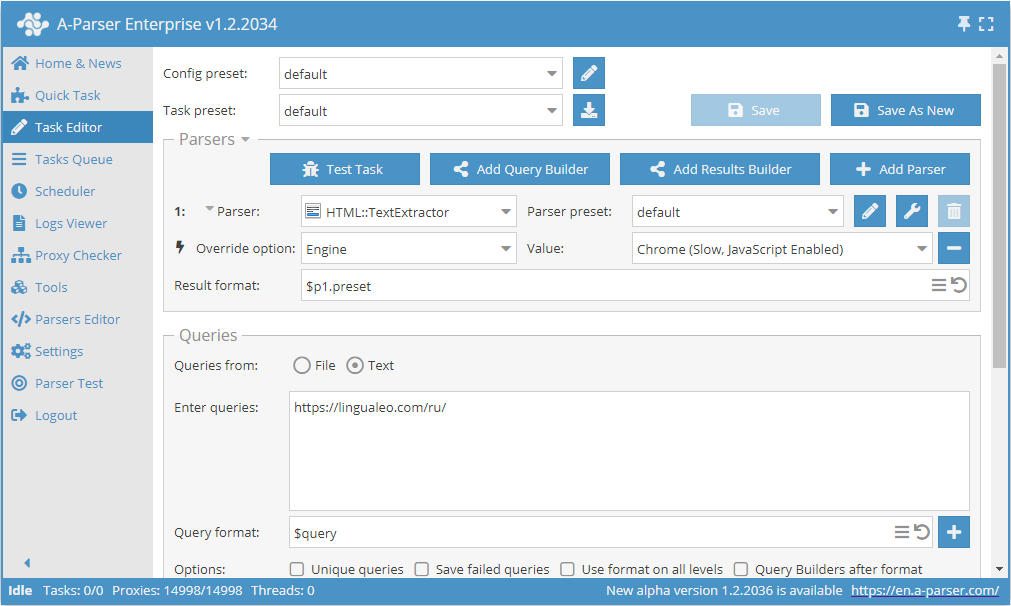
- Voeg de optie Engine toe en selecteer in de lijst de engine
Chrome (Slow, JavaScript Enabled). - Geef als query de link op naar de website waarvan de tekst moet worden gescraped.
Deze optie kan nuttig zijn in gevallen waarin een website de hoofdtekst via scripts inlaadt tijdens het laden van de pagina, en bij gebruik van HTTP (Fast, JavaScript Disabled) het resultaat ontbreekt of onvolledig is.
Download voorbeeld
Hoe een voorbeeld in A-Parser te importeren
eJxtU01v2zAM/S9EDhsQJO1hF9/SYME6pHXXpqcgB8GmXa2ypOkjS2Hkv+/Jce2k
680kHx8fxeeWgvCv/sGx5+Ap27Zku2/KqORKRBVoSlY4zy6Vt/Rjc7fOsg0fwvdD
cKIIxgExYFsKb5bRbfbsnCwZRVkiZl1LnaK9UDEBihdnGqbjbjcljES3XxnXiDR6
Yq9nvY6h+CT2vDEoVlLxmF4huhdNYpyUInCqzqqO6MvXWTgkBlGWMkijhTpNSJuM
U5+1/NMp8sFJXQOP0En2KwhEOnBHkpJv7wq3NOliAk3s+n+deigLLvKUPNSuBLSU
Q6ESyqMiAzuBV8ttkoR8S0YvlFrzntUI6+hvolQlXn5Roem2b/wckv/HcRw2PB+F
s/x10DCwdNFNfjd2lWZtaiyuDdZWspEBsV+aqNNtrpB8ZbbDs90nWGMcD2N65n46
zGVZJw+MV1vYMXWxxsVlLpOF0ZWs895X78ioN3BwrpemsYrTXjoqhat4fhwdsvD9
GVIwCvzYvOxGXHg/GKP8z6eTVOskHPgtCWzwkudTe8pCKPX8uD6v0OgoBC8hWJ/N
5wpWi0KxmRWmmbs4p9QcuDZwFVY77ob/bvg720//vqw94mi//cMJnTZMWOTwVB4X
oez6+A9VbWHX
Tekst extraheren met paginanavigatie aan de hand van nieuws
Resultaten worden opgeslagen in de map aparser/results/example/textextractor in een apart bestand voor elke query. Als naam wordt het volgnummer van de query gebruikt.
- Voeg de optie Check next page toe en geef als regex
(forum\/news\/page-\d+)"[^>]+>Volgendeop. - Voeg de optie Page as new query toe.
- Wijzig de File name (Bestandsnaam) naar
example/textextractor/${query.num}.txt. - Geef als query de link op naar de eerste pagina met A-Parser nieuws:
https://a-parser.com/forum/news/.
Download voorbeeld
Hoe een voorbeeld in A-Parser te importeren
eJx1VN1v2jAQ/18sHjaVEtjoSx4qUVS0TRRoS58Ik6zkQj0c27UdPhTlf9/ZCQmw
7sXJne/jd7+7c0EsNVuz0GDAGhKuCqL8PwnJ44FmikMYLuFgHw9W09hKHYYzFBd0
A6RLFNUGtPNbkR/Lp+mVLVokkNKcW9ItiD0qwLBSWSaFwTuWoBi/Q7w9C7mjPHdm
X1Kp8yyKAgF7gx+F17dRlNx8jcjq9/365j7K+8PBN3d+T/15585h3513A68ZYkCa
JMxlpJyExWW6KcuYq7RPyvK/AF3ikZnB/jkHfWwRWp3DdfQtgPJmU9gBavpluV53
CTKKHJiJ1Bl1+Tpq0Ktpbi5f6Q6WEi9TxqFVT1Ca0czhgqofgUX0cKI46BQfLmFP
5FnZswd7UXGV0fWnRfEm2IdnWEi0dc4MzETLDFUubq08ntCuSMfLBEPk3ve58iFh
SrlBDgxCn1AEmlzfMAuaIsp5TSlSJMWIc09Pa+bjP+SMJzhMoxSdftaOn5vM/4lR
NuWdp9qB3mvE0ETx0sP8qfVK5FRuTmRwNw8om7HMRTUYXd/ThrOZM8ukhiZNHbnO
joukQLixaVs4Uq3qooyLtlwqYylStpljAZolcLLMxRK3dS7G0g2Cq0vknGNbDLy0
4zIydRuc0AK8dh77FAirWVFipeTm12sFVWmG43jnAGbI5HnWOmRMOX97mZ7fkHak
UHi3VpkwCOht9VD0YpkFfq/9VgfExbCwkThdWGG5bl6U5kEqPn1XwgIXlvwxi8ra
FepsUYeMGWwMCQflX6y1tO0=
Verzamelde gegevens
- Scrapt tekstblokken van de opgegeven pagina
- Array met alle verzamelde pagina's (wordt gebruikt bij de optie Use Pages)
Mogelijkheden
- Tekstextractie over meerdere pagina's (paginanavigatie)
- Automatisch opschonen van tekst van HTML-tags
- Mogelijkheid om een minimale lengte voor tekstblokken in te stellen
- Optionele verwijdering van link-anchors uit de tekst
- Ondersteunt compressie gzip/deflate/brotli
- Detectie en conversie van website-coderingen naar UTF-8
- Omzeilen van CloudFlare-beveiliging
- Keuze van engine (HTTP of Chrome)
Gebruiksscenario's
- Scrapen van tekstuele content van willekeurige websites
Query's
Als query's moeten links naar de pagina's worden opgegeven waarvan de tekstblokken moeten worden gescraped, bijvoorbeeld:
https://a-parser.com/
Voorbeelden van resultaatuitvoer
A-Parser ondersteunt flexibele formattering van resultaten dankzij de ingebouwde sjabloon-engine Template Toolkit, waardoor resultaten in een vrije vorm of gestructureerd zoals CSV of JSON kunnen worden uitgevoerd.
Standaarduitvoer
Resultaatindeling:
$texts.format('$text\n')
Voorbeeldresultaat:
Hallo, Superteam van Hoogste Professionals in hun vak! Bedankt voor de mogelijkheid om Spaans, Turks en Portugees te leren! Ik wens jullie een verdere uitbreiding van jullie Mogelijkheden! Inspiratie en Creativiteit! En het verzoek om de mogelijkheid toe te voegen om Duits en Frans te leren!”
Ik gebruik Lingualeo al vele jaren, de eerste keer dat ik begon was toen er nog helemaal geen app was, alleen de website) Bedankt aan de ontwikkelaars, ga zo door, met creativiteit en veel liefde voor het vak)
Technisch Engels voor IT: woordenboeken, leerboeken, tijdschriften
Leer talen online Leer Engels online Leer Vietnamees online Leer Grieks online Leer Indonesisch online Leer Spaans online Leer Italiaans online Leer Chinees online Leer Koreaans online Leer Duits online Leer Nederlands online Leer Pools online Leer Portugees online Leer Servisch online Leer Turks online Leer Oekraïens online Leer Frans online Leer Hindi online Leer Tsjechisch online Leer Japans online
Mogelijke instellingen
| Naam parameter | Standaardwaarde | Beschrijving |
|---|---|---|
| Min block length | 50 | Minimale lengte van een tekstblok in tekens. |
| Skip anchor text | ☐ | Of anchors in de tekst moeten worden overgeslagen. |
| Ignore tags list | Optie om tags op te geven die genegeerd moeten worden. Voorbeeld: div,span,p | |
| Good status | All | Keuze welk antwoord van de server als succesvol wordt beschouwd. Als er tijdens het scrapen een ander antwoord van de server komt, wordt de query herhaald met een andere proxy. |
| Good code RegEx | Mogelijkheid om een reguliere expressie op te geven voor het controleren van de responscode. | |
| Method | GET | Verzoekmethode. |
| POST body | Content die naar de server moet worden verzonden bij gebruik van de POST-methode. Ondersteunt variabelen $query – URL van de query, $query.orig – oorspronkelijke query en $pagenum - paginanummer bij gebruik van de optie Use Pages. | |
| Cookies | Mogelijkheid om cookies voor de query op te geven. | |
| User agent | `_Automatisch wordt de user-agent van de actuele Chrome-versie ingevuld_ | De User-Agent header bij het opvragen van pagina's. |
| Additional headers | Mogelijkheid om willekeurige verzoekheaders op te geven met ondersteuning voor de sjabloon-engine en gebruik van variabelen uit de query builder. | |
| Read only headers | ☐ | Alleen headers lezen. In sommige gevallen bespaart dit verkeer als het niet nodig is om de content te verwerken. |
| Detect charset on content | ☐ | Codering herkennen op basis van de pagina-inhoud. |
| Emulate browser headers | ☐ | Browserheaders emuleren. |
| Max redirects count | 7 | Maximaal aantal redirects dat de scraper zal volgen. |
| Max cookies count | 16 | Maximaal aantal cookies om op te slaan. |
| Bypass CloudFlare | ☑ | Automatische omzeiling van CloudFlare-controle. |
| Follow common redirects | ☑ | Maakt redirects mogelijk tussen http <-> https en www.domein <-> domein binnen hetzelfde domein, buiten de limiet van Max redirects count. |
| Engine | HTTP (Fast, JavaScript Disabled) | Hiermee kunt u de engine kiezen: HTTP (sneller, zonder JavaScript) of Chrome (langzamer, JavaScript ingeschakeld). |
| Chrome Headless | ☐ | Als deze optie is ingeschakeld, wordt de browser niet weergegeven. |
| Chrome DevTools | ☑ | Maakt het gebruik van Chromium-foutopsporingstools mogelijk. |
| Chrome Log Proxy connections | ☑ | Als deze optie is ingeschakeld, wordt informatie over Chrome-verbindingen in het logboek weergegeven. |
| Chrome Wait Until | networkidle2 | Bepaalt wanneer de pagina als geladen wordt beschouwd. Meer informatie over de waarden. |
| Use HTTP/2 transport | ☐ | Bepaalt of HTTP/2 moet worden gebruikt in plaats van HTTP/1.1. Google en Majestic bannen bijvoorbeeld onmiddellijk bij gebruik van HTTP/1.1. |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | CF-omzeiling via Chrome. |
| Bypass CloudFlare with Chrome Max Pages | Max. aantal pagina's bij CF-omzeiling via Chrome. |