HTML::LinkExtractor - Scraper zewnętrznych i wewnętrznych linków z podanej strony
Przegląd scrapera
 HTML::LinkExtractor – scraper linków zewnętrznych i wewnętrznych z podanej witryny. Obsługuje wielostronicowe scrapowanie i przechodzenie po wewnętrznych stronach witryny do określonej głębokości, co pozwala przejść przez wszystkie strony witryny, zbierając linki wewnętrzne i zewnętrzne. Posiada wbudowane narzędzia do omijania zabezpieczeń CloudFlare a także możliwość wyboru Chrome jako silnika do scrapowania e-maili ze stron, na których dane są ładowane przez skrypty. Jest w stanie osiągnąć prędkość do 2000 zapytań na minutę – to 120 000 linków na godzinę.
HTML::LinkExtractor – scraper linków zewnętrznych i wewnętrznych z podanej witryny. Obsługuje wielostronicowe scrapowanie i przechodzenie po wewnętrznych stronach witryny do określonej głębokości, co pozwala przejść przez wszystkie strony witryny, zbierając linki wewnętrzne i zewnętrzne. Posiada wbudowane narzędzia do omijania zabezpieczeń CloudFlare a także możliwość wyboru Chrome jako silnika do scrapowania e-maili ze stron, na których dane są ładowane przez skrypty. Jest w stanie osiągnąć prędkość do 2000 zapytań na minutę – to 120 000 linków na godzinę.Przypadki użycia scrapera
Zbieranie wszystkich linków zewnętrznych z witryny
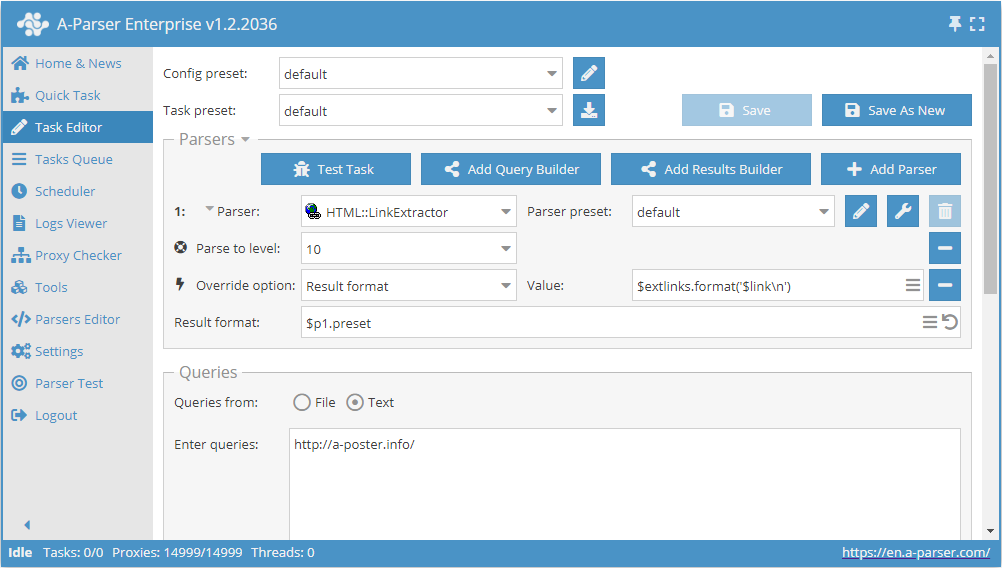
- Dodaj opcję Parse to level, z listy wybierz wartość
10(przechodzenie po sąsiednich stronach do 10 poziomu). - Dodaj opcję Result format, jako wartość podaj
$extlinks.format('$link\n')(wyświetlanie linków zewnętrznych). - W sekcji Queries (Zapytania) zaznacz opcję
Unique queries. - W sekcji Results (Wyniki) zaznacz opcję
Unique string. - Jako zapytanie podaj link do strony, z której chcesz scrapować linki zewnętrzne.
Pobierz przykład
Jak importować przykład do A-Parser
eJxtU01v2zAM/S9CgK5AlrSHXnxLgwZb4dZdm57SHISYztTIoirRWQrD/32U7NjJ
1ptIvsfHL9WCpN/5JwceyItkVQsb3yIRORSy0iTGwkrnwYXwSvxYPqRJkiqzuzuQ
kxtCx4geWwv6tMBstKTQeI6pnM2YIoU9aPbspa4Yc33VnOD34JzK4Ugo0JWSuJa2
hI4iRnAgzeJ+0gK+XYyC+fZmLi5Fs16PRUvxixgODHs96Xrqgy9yD0sMKkrD4F6w
9SjLqJNLghA96lxO6BAyyDxXoTOpW4UwlUH11aiPWKcnp8yW8Ww6BX7hsGQ3QUwS
nJ/HCldiFG3BaarI/9VyREKugrHwXO1Cci15Hyik9hxRBE7yBrJu2Ekt0My0joMe
YDH9baV0zlucFUz62RG/hmT/5Wj6Dk+leGV/HNfQZ4nWbfYwsHJMccuNG+S2tSoV
se3nWJmwmyt27gBsP7bHACvRQS/TZe7U+VAtmHAfw9ZmdnCdtXG2mXPnBk2htll3
c0dkZZb8GzIzx9JqCH2ZSmveiofn4UJmvltDMIYC/yXPo8TZPyJE7e9f2lKtU3yB
N6HAkid5qtql3EitX5/T04gYLoqN30Q2mU7ld4ueFzpRpsCpCESCLfJFcVvNuv+/
/S+vv/zFSd3wwt79U4sO3QUs+3hMnrfBP7b5C6wbebo=
wskazówka
Zbieranie wszystkich linków wewnętrznych z witryny
Analogicznie do pierwszego przypadku, ale w kroku 2 jako wartość należy podać $intlinks.format('$link\n') (wyświetlanie linków wewnętrznych).
Pobierz przykład
Jak importować przykład do A-Parser
eJxtU8tu2zAQ/BfCQBrAtZNDL7o5Roy2cOI0j5PjA2GtXNYUyZIrN4Ggf++QkiW7
zY27O7OzL9aCZdiHB0+BOIhsXQuX3iITORWy0izGwkkfyMfwWnx9vltm2VKZ/e0b
e7ll64HosbXgd0dgW8fKmoCYymGmFEs6kIbnIHUFzPVVc4I/kPcqpyOhsL6UjFra
EjqKGCnDGuJh0gI+XYyi+fpqLi5Fs9mMRUsJixSODHc96Xrqg0/yQM82qihNg3sB
616WSSeXTDF61Lmc8FvMIPNcxc6kbhXiVAbVF6N+pzoDe2V2wMP0isLC2xJuppQk
Ot+PFa7FKNkCaarE/9FyRMa+orEIqHYhUUveBwqpAyKKyUtsYNUNO6uFNTOt06AH
WEp/UymdY4uzAqRvHfFjyOq/HE3f4akUVvbHo4Y+S7JuVncDK7dLu0PjxqJtrUrF
sMPcVibu5grOPZHrx3YfYaX11Mt0mTt1HKojE+9j2NrMDa6zNs42c+7cWlOo3aq7
uSOyMs/4DSszt6XTFPsyldbYSqDH4UJmoVtDNIYC/yXPk8TZP2Jrdfj+1JbqvMIF
fokFlpjkqWqXciu1fnlcnkbEcFEwfjK7bDqVn50NWOhEmcJORSQy7SwuCm01m/7/
9r+8/vAXZ3WDhf0KDy06dhex8GFMAdvAj23+ApcrebQ=
Przechodzenie tylko po linkach, które nie zawierają słowa forum
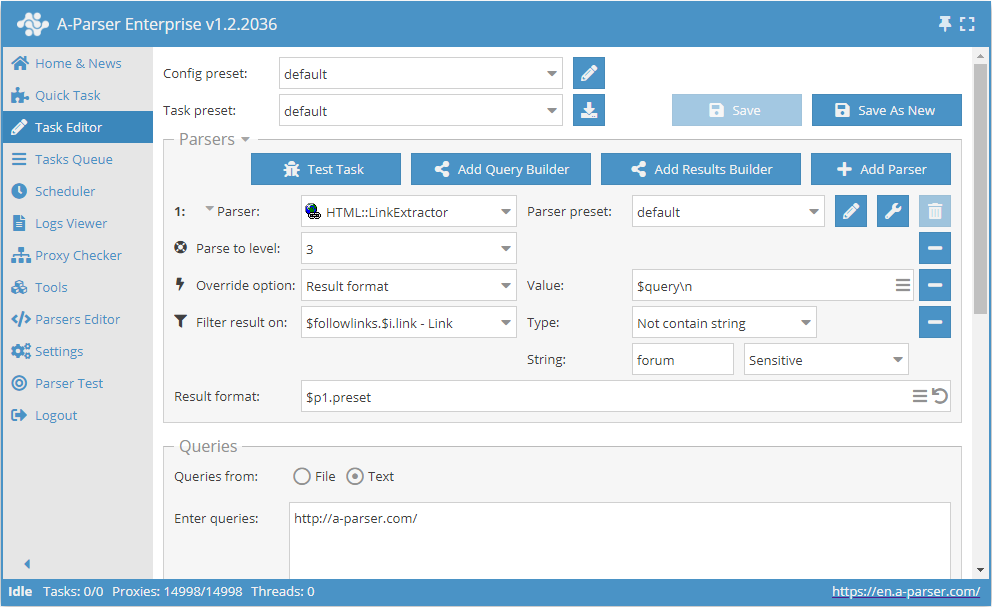
- Dodaj opcję Parse to level, z listy wybierz wartość
3(przechodzenie po sąsiednich stronach do 3 poziomu). - Dodaj opcję Result format, jako wartość podaj
$query. - Dodaj filtr. Filtruj po
$followlinks.$i.link - Link, wybierz typNot contain string, jako sam ciąg podajforum. - W sekcji Queries (Zapytania) zaznacz opcję
Unique queries. - W sekcji Results (Wyniki) zaznacz opcję
Unique string. - Jako zapytanie podaj link do strony, z której chcesz scrapować linki.
Pobierz przykład
Jak importować przykład do A-Parser
eJxtVE1v2zAM/S/CDhuQJS2GXXxLgwbd4DZdm57SHISYzrTIkipRaQvD/33UR2xn
6ykh+R75+CG3DLk7uHsLDtCxYtMyE/+zglVQcy+RTZjh1oEN4Q27Wd+WRVEKdbh+
Q8t3qC0hemzL8N0AsbVBoZWjmKjIjClKOIIkz5FLT5hv3Qh+BGtFBSd8rW3DkaQk
BZnBPr14sO/Pz4qNuLWQCEFFhhcbokupXyWpDArCL9tOMnCdWErjTivkQo3yU1nf
kJ3Uk8MB9dBtt6fkbhmFBSnmcppn1Qcf+RHWOkmCwb0k6443sYGKI4ToNHX4+csU
30IGXlUi1OQyVQjTHqo+KfESBTq0Qu0JHwYhwC2tbsiNEJPE6ZwUbvK0Quc+8n8l
DivQepgwR2qXnLRUfaDm0lFE0Jg4bXaVl1i0TKu5lHGBAyymv/JCVnQd85pIPzLx
Y8jqvxxd3+G4FN3CqyUNfZZoXa1uB1alS72PW4z7bQSS7Rbaq7CbC3IeAEw/trsA
a7SFvkzOnKvTAzCgwuENW5ubwXXWxtlmzp10UbXYr/Ixn5BeremVrdRCN0ZC6Et5
KWkrDh6GC5m7vIZgDAL/JS9iibP3iVpL9/MxSTVW0AV+DwIbmuS4ak6541I+PZTj
CBsuiozfiKaYzfjX9PCnO93MWOAh7DUdFHXVbfvPQv/xaD/8OBRtR/v64+4TOjQX
sOSjKbn4yi67v8azl7c=
wskazówka
Zbierane dane
- Liczba linków zewnętrznych
- Liczba linków wewnętrznych
- Linki zewnętrzne:
- same linki
- anchory
- anchory oczyszczone z tagów HTML
- parametr nofollow
- pełny tag
<a>
- Linki wewnętrzne:
- same linki
- anchory
- anchory oczyszczone z tagów HTML
- parametr nofollow
- pełny tag
<a>
- Tablica ze wszystkimi zebranymi stronami (używana przy opcji Use Pages)
Możliwości
- Scrapowanie wielostronicowe (przechodzenie po stronach)
- Przechodzenie po wewnętrznych stronach witryny do określonej głębokości (opcja Parse to level) – pozwala przejść przez wszystkie strony witryny, zbierając linki wewnętrzne i zewnętrzne
- Limit przejść po stronach (opcja Follow links limit)
- Automatyczne oczyszczanie anchora z tagów HTML
- Wykrywanie nofollow dla każdego linku
- Możliwość traktowania subdomen jako stron wewnętrznych witryny
- Obsługa kompresji gzip/deflate/brotli
- Wykrywanie i konwersja kodowania stron na UTF-8
- Omijanie zabezpieczeń CloudFlare
- Wybór silnika (HTTP lub Chrome)
Warianty użycia
- Uzyskanie pełnej mapy witryny (zapisanie wszystkich linków wewnętrznych)
- Uzyskanie wszystkich linków zewnętrznych z witryny
- Sprawdzanie linku zwrotnego do własnej witryny
Zapytania
Jako zapytania należy podawać linki do stron, z których należy zebrać linki, lub punkt wejścia (np. stronę główną witryny) w przypadkach, gdy używana jest opcja Parse to level:
https://lenta.ru/
https://a-parser.com/wiki/index/
Warianty wyświetlania wyników
A-Parser obsługuje elastyczne formatowanie wyników dzięki wbudowanemu silnikowi szablonów Template Toolkit, co pozwala na wyprowadzanie wyników w dowolnej formie, a także w formie strukturalnej, np. CSV lub JSON
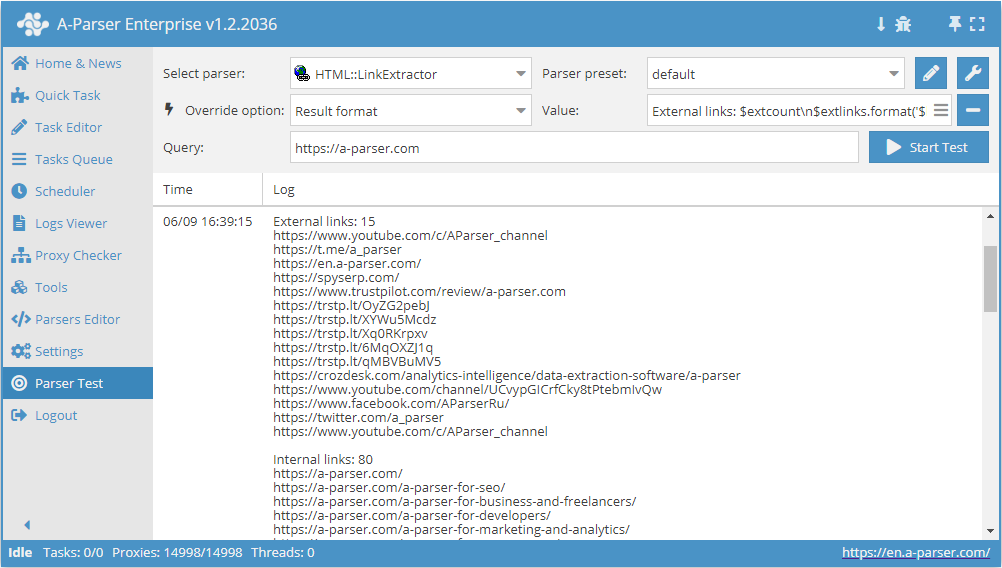
Wyświetlanie linków zewnętrznych i wewnętrznych wraz z ich liczbą
Format wyniku:
External links: $extcount\n$extlinks.format('$link\n')
Internal links: $intcount\n$intlinks.format('$link\n')
Przykład wyniku:
External links: 12
https://www.youtube.com/c/AParser_channel
https://t.me/a_parser
https://en.a-parser.com/
https://spyserp.com/ru/
https://sitechecker.pro/
https://arsenkin.ru/tools/
https://spyserp.com/
http://www.promkaskad.ru/
https://www.youtube.com/channel/UCvypGICrfCky8tPtebmIvQw
https://www.facebook.com/AParserRu
https://twitter.com/a_parser
https://www.youtube.com/c/AParser_channel
Internal links: 129
https://a-parser.com/
https://a-parser.com/
https://a-parser.com/a-parser-for-seo/
https://a-parser.com/a-parser-for-business-and-freelancers/
https://a-parser.com/a-parser-for-developers/
https://a-parser.com/a-parser-for-marketing-and-analytics/
https://a-parser.com/a-parser-for-e-commerce/
https://a-parser.com/a-parser-for-cpa/
https://a-parser.com/wiki/features-and-benefits/
https://a-parser.com/wiki/parsers/
Możliwe ustawienia
notatka
| Nazwa parametru | Wartość domyślna | Opis |
|---|---|---|
| Good status | All | Wybór, która odpowiedź z serwera będzie uznana za sukces. Jeśli podczas scrapowania wystąpi inna odpowiedź, zapytanie zostanie powtórzone z innym proxy |
| Good code RegEx | Możliwość określenia wyrażenia regularnego do sprawdzania kodu odpowiedzi | |
| Ban Proxy Code RegEx | Możliwość blokowania proxy na czas (Proxy ban time) na podstawie kodu odpowiedzi serwera | |
| Method | GET | Metoda zapytania |
| POST body | Treść do przesłania na serwer przy użyciu metody POST. Obsługuje zmienne $query – URL zapytania, $query.orig – oryginalne zapytanie oraz $pagenum - numer strony przy użyciu opcji Use Pages. | |
| Cookies | Możliwość określenia plików cookies dla zapytania. | |
| User agent | _Automatycznie podstawiany user-agent aktualnej wersji Chrome_ | Nagłówek User-Agent przy zapytaniu o strony |
| Additional headers | Możliwość określenia dowolnych nagłówków zapytania z obsługą możliwości silnika szablonów i użyciem zmiennych z konstruktora zapytań | |
| Read only headers | ☐ | Czytaj tylko nagłówki. W niektórych przypadkach pozwala oszczędzać transfer, jeśli nie ma potrzeby przetwarzania treści |
| Detect charset on content | ☐ | Rozpoznawaj kodowanie na podstawie zawartości strony |
| Emulate browser headers | ☐ | Emuluj nagłówki przeglądarki |
| Max redirects count | 0 | Maksymalna liczba przekierowań, po których będzie przechodził scraper |
| Follow common redirects | ☑ | Pozwala na przekierowania http <-> https oraz www.domain <-> domain v obrębie jednej domeny z pominięciem limitu Max redirects count |
| Max cookies count | 16 | Maksymalna liczba cookies do zapisania |
| Engine | HTTP (Fast, JavaScript Disabled) | Pozwala wybrać silnik HTTP (szybszy, bez JavaScript) lub Chrome (wolniejszy, JavaScript włączony) |
| Chrome Headless | ☐ | Jeśli opcja jest włączona, przeglądarka nie będzie wyświetlana |
| Chrome DevTools | ☑ | Pozwala używać narzędzi do debugowania Chromium |
| Chrome Log Proxy connections | ☑ | Jeśli opcja jest włączona, w logu będą wyświetlane informacje o połączeniach chrome |
| Chrome Wait Until | networkidle2 | Określa, kiedy strona jest uznawana za załadowaną. Więcej o wartościach. |
| Use HTTP/2 transport | ☐ | Określa, czy używać HTTP/2 zamiast HTTP/1.1. Na przykład Google i Majestic natychmiast blokują przy użyciu HTTP/1.1. |
| Don't verify TLS certs | ☐ | Wyłączenie walidacji certyfikatów TLS |
| Randomize TLS Fingerprint | ☐ | Ta opcja pozwala omijać blokady stron na podstawie odcisku TLS |
| Bypass CloudFlare | ☑ | Automatyczne omijanie weryfikacji CloudFlare |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Omijanie CF przez Chrome |
| Bypass CloudFlare with Chrome Max Pages | 20 | Maks. liczba stron przy omijaniu CF przez Chrome |
| Subdomains are internal | ☐ | Czy traktować subdomeny jako linki wewnętrzne |
| Follow links | Internal only | Po jakich linkach przechodzić |
| Follow links limit | 0 | Limit Follow links, stosowany do każdej unikalnej domeny |
| Skip comment blocks | ☐ | Czy pomijać bloki komentarzy |