HTML::LinkExtractor - 提取指定网站的内外部链接爬虫工具
爬虫工具概览
 HTML::LinkExtractor – 采集指定网站外部和内部链接的爬虫工具。支持多页面数据抓取,并可跳转至指定深度的内部页面,从而遍历网站所有页面并采集内外链。内置 CloudFlare 防护绕过工具,并可选择 Chrome 作为引擎,用于抓取由脚本加载数据的页面。其速度最高可达每分钟 2000 次请求 – 即每小时采集 120 000 个链接。
HTML::LinkExtractor – 采集指定网站外部和内部链接的爬虫工具。支持多页面数据抓取,并可跳转至指定深度的内部页面,从而遍历网站所有页面并采集内外链。内置 CloudFlare 防护绕过工具,并可选择 Chrome 作为引擎,用于抓取由脚本加载数据的页面。其速度最高可达每分钟 2000 次请求 – 即每小时采集 120 000 个链接。爬虫工具应用案例
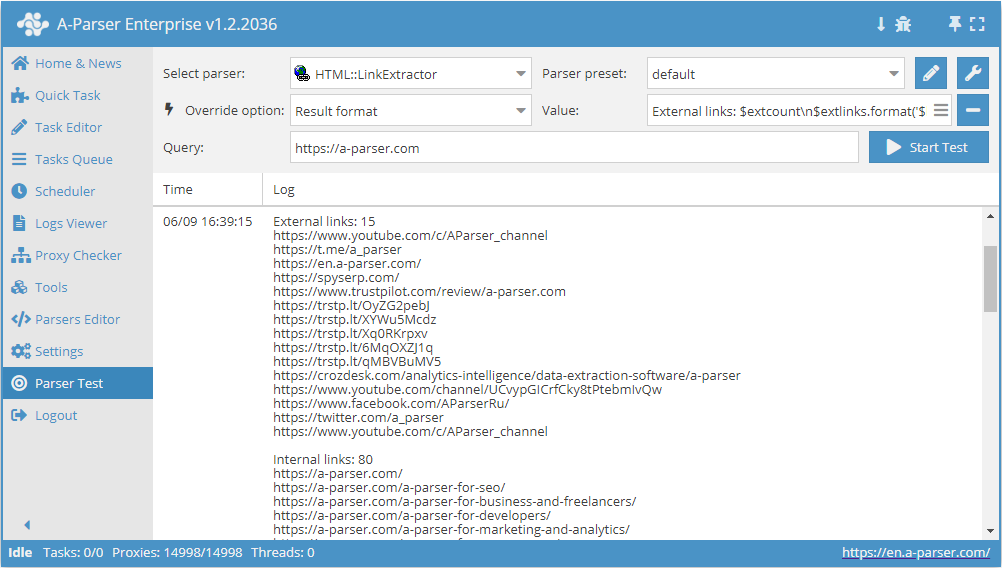
采集网站的所有外部链接
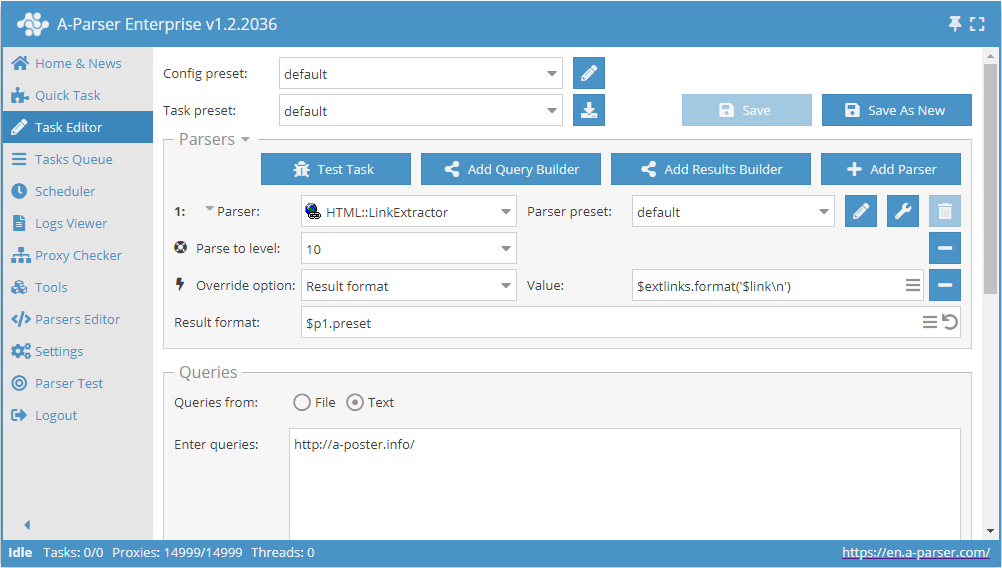
- 添加 Parse to level 选项,在列表中选择值
10(跳转相邻页面直至第 10 层)。 - 添加 Result format 选项,将值设为
$extlinks.format('$link\n')(输出外部链接)。 - 在 Queries (查询) 部分,勾选
Unique queries选项。 - 在 Results (结果) 部分,勾选
Unique string选项。 - 在查询中输入需要抓取外部链接的网站链接。
下载示例
eJxtU01v2zAM/S9CgK5AlrSHXnxLgwZb4dZdm57SHISYztTIoirRWQrD/32U7NjJ
1ptIvsfHL9WCpN/5JwceyItkVQsb3yIRORSy0iTGwkrnwYXwSvxYPqRJkiqzuzuQ
kxtCx4geWwv6tMBstKTQeI6pnM2YIoU9aPbspa4Yc33VnOD34JzK4Ugo0JWSuJa2
hI4iRnAgzeJ+0gK+XYyC+fZmLi5Fs16PRUvxixgODHs96Xrqgy9yD0sMKkrD4F6w
9SjLqJNLghA96lxO6BAyyDxXoTOpW4UwlUH11aiPWKcnp8yW8Ww6BX7hsGQ3QUwS
nJ/HCldiFG3BaarI/9VyREKugrHwXO1Cci15Hyik9hxRBE7yBrJu2Ekt0My0joMe
YDH9baV0zlucFUz62RG/hmT/5Wj6Dk+leGV/HNfQZ4nWbfYwsHJMccuNG+S2tSoV
se3nWJmwmyt27gBsP7bHACvRQS/TZe7U+VAtmHAfw9ZmdnCdtXG2mXPnBk2htll3
c0dkZZb8GzIzx9JqCH2ZSmveiofn4UJmvltDMIYC/yXPo8TZPyJE7e9f2lKtU3yB
N6HAkid5qtql3EitX5/T04gYLoqN30Q2mU7ld4ueFzpRpsCpCESCLfJFcVvNuv+/
/S+vv/zFSd3wwt79U4sO3QUs+3hMnrfBP7b5C6wbebo=
采集网站的所有内部链接
与第一个案例类似,但在第 2 步中需要将值设为 $intlinks.format('$link\n')(输出内部链接)。
下载示例
eJxtU8tu2zAQ/BfCQBrAtZNDL7o5Roy2cOI0j5PjA2GtXNYUyZIrN4Ggf++QkiW7
zY27O7OzL9aCZdiHB0+BOIhsXQuX3iITORWy0izGwkkfyMfwWnx9vltm2VKZ/e0b
e7ll64HosbXgd0dgW8fKmoCYymGmFEs6kIbnIHUFzPVVc4I/kPcqpyOhsL6UjFra
EjqKGCnDGuJh0gI+XYyi+fpqLi5Fs9mMRUsJixSODHc96Xrqg0/yQM82qihNg3sB
616WSSeXTDF61Lmc8FvMIPNcxc6kbhXiVAbVF6N+pzoDe2V2wMP0isLC2xJuppQk
Ot+PFa7FKNkCaarE/9FyRMa+orEIqHYhUUveBwqpAyKKyUtsYNUNO6uFNTOt06AH
WEp/UymdY4uzAqRvHfFjyOq/HE3f4akUVvbHo4Y+S7JuVncDK7dLu0PjxqJtrUrF
sMPcVibu5grOPZHrx3YfYaX11Mt0mTt1HKojE+9j2NrMDa6zNs42c+7cWlOo3aq7
uSOyMs/4DSszt6XTFPsyldbYSqDH4UJmoVtDNIYC/yXPk8TZP2Jrdfj+1JbqvMIF
fokFlpjkqWqXciu1fnlcnkbEcFEwfjK7bDqVn50NWOhEmcJORSQy7SwuCm01m/7/
9r+8/vAXZ3WDhf0KDy06dhex8GFMAdvAj23+ApcrebQ=
仅跳转不包含单词 forum 的链接
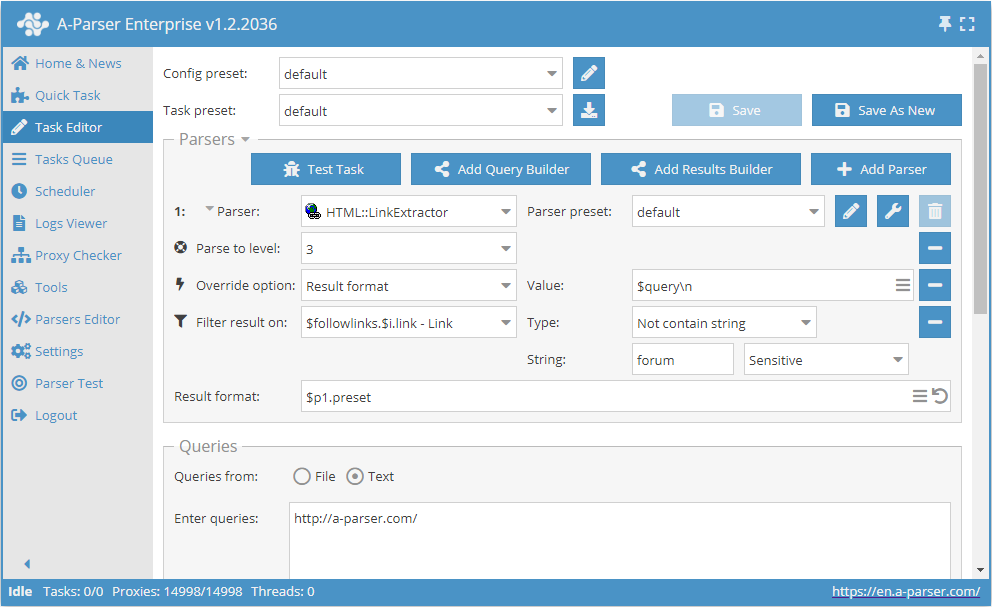
- 添加 Parse to level 选项,在列表中选择值
3(跳转相邻页面直至第 3 层)。 - 添加 Result format 选项,将值设为
$query。 - 添加过滤器。过滤对象选择
$followlinks.$i.link - Link,类型选择Not contain string,字符串内容填写forum。 - 在 Queries (查询) 部分,勾选
Unique queries选项。 - 在 Results (结果) 部分,勾选
Unique string选项。 - 在查询中输入需要抓取链接的网站链接。
下载示例
eJxtVE1v2zAM/S/CDhuQJS2GXXxLgwbd4DZdm57SHISYzrTIkipRaQvD/33UR2xn
6ykh+R75+CG3DLk7uHsLDtCxYtMyE/+zglVQcy+RTZjh1oEN4Q27Wd+WRVEKdbh+
Q8t3qC0hemzL8N0AsbVBoZWjmKjIjClKOIIkz5FLT5hv3Qh+BGtFBSd8rW3DkaQk
BZnBPr14sO/Pz4qNuLWQCEFFhhcbokupXyWpDArCL9tOMnCdWErjTivkQo3yU1nf
kJ3Uk8MB9dBtt6fkbhmFBSnmcppn1Qcf+RHWOkmCwb0k6443sYGKI4ToNHX4+csU
30IGXlUi1OQyVQjTHqo+KfESBTq0Qu0JHwYhwC2tbsiNEJPE6ZwUbvK0Quc+8n8l
DivQepgwR2qXnLRUfaDm0lFE0Jg4bXaVl1i0TKu5lHGBAyymv/JCVnQd85pIPzLx
Y8jqvxxd3+G4FN3CqyUNfZZoXa1uB1alS72PW4z7bQSS7Rbaq7CbC3IeAEw/trsA
a7SFvkzOnKvTAzCgwuENW5ubwXXWxtlmzp10UbXYr/Ixn5BeremVrdRCN0ZC6Et5
KWkrDh6GC5m7vIZgDAL/JS9iibP3iVpL9/MxSTVW0AV+DwIbmuS4ak6541I+PZTj
CBsuiozfiKaYzfjX9PCnO93MWOAh7DUdFHXVbfvPQv/xaD/8OBRtR/v64+4TOjQX
sOSjKbn4yi67v8azl7c=
采集的数据
- 外部链接数量
- 内部链接数量
- 外部链接:
- 链接本身
- 锚点文本
- 去除 HTML 标签后的锚点文本
- nofollow 参数
- 完整的
<a>标签
- 内部链接:
- 链接本身
- 锚点文本
- 去除 HTML 标签后的锚点文本
- nofollow 参数
- 完整的
<a>标签
- 包含所有采集页面的数组(在使用 Use Pages 选项时使用)
功能
- 多页面数据抓取(页面跳转)
- 跳转网站内部页面至指定深度(Parse to level 选项)——允许遍历网站所有页面,采集内部和外部链接
- 页面跳转限制(Follow links limit 选项)
- 自动去除锚点文本中的 HTML 标签
- 识别每个链接的 nofollow 属性
- 可选择将子域名视为网站内部页面
- 支持 gzip/deflate/brotli 压缩
- 识别并将网站编码转换为 UTF-8
- 绕过 CloudFlare 防护
- 选择引擎(HTTP 或 Chrome)
使用场景
- 获取完整的网站地图(保存所有内部链接)
- 获取网站的所有外部链接
- 检查指向自己网站的反向链接
查询
在查询中需要指定要从中采集链接的页面链接,或者在使用 Parse to level 选项时指定入口点(例如网站首页):
https://lenta.ru/
https://a-parser.com/wiki/index/
结果输出示例
A-Parser 凭借内置的 Template Toolkit 模板引擎支持灵活的结果格式化,允许以任意形式输出结果,也可以输出为 CSV 或 JSON 等结构化格式。
输出外部和内部链接及其数量
结果格式:
External links: $extcount\n$extlinks.format('$link\n')
Internal links: $intcount\n$intlinks.format('$link\n')
结果示例:
External links: 12
https://www.youtube.com/c/AParser_channel
https://t.me/a_parser
https://en.a-parser.com/
https://spyserp.com/ru/
https://sitechecker.pro/
https://arsenkin.ru/tools/
https://spyserp.com/
http://www.promkaskad.ru/
https://www.youtube.com/channel/UCvypGICrfCky8tPtebmIvQw
https://www.facebook.com/AParserRu
https://twitter.com/a_parser
https://www.youtube.com/c/AParser_channel
Internal links: 129
https://a-parser.com/
https://a-parser.com/
https://a-parser.com/a-parser-for-seo/
https://a-parser.com/a-parser-for-business-and-freelancers/
https://a-parser.com/a-parser-for-developers/
https://a-parser.com/a-parser-for-marketing-and-analytics/
https://a-parser.com/a-parser-for-e-commerce/
https://a-parser.com/a-parser-for-cpa/
https://a-parser.com/wiki/features-and-benefits/
https://a-parser.com/wiki/parsers/
可能的设置
| 参数名称 | 默认值 | 描述 |
|---|---|---|
| Good status | All | 选择哪些服务器响应将被视为成功。如果数据抓取时收到其他响应,将使用另一个代理重试请求 |
| Good code RegEx | 可以指定用于检查响应代码的正则表达式 | |
| Ban Proxy Code RegEx | 可以根据服务器响应代码临时封禁代理(Proxy ban time) | |
| Method | GET | 请求方法 |
| POST body | 使用 POST 方法时发送到服务器的内容。支持变量 $query – 请求 URL,$query.orig – 原始查询,以及在使用 Use Pages 选项时的页码 $pagenum。 | |
| Cookies | 可以为请求指定 cookies。 | |
| User agent | _自动插入当前版本 Chrome 的 user-agent_ | 请求页面时的 User-Agent 请求头 |
| Additional headers | 可以指定自定义请求头,支持模板引擎功能并使用请求构造器中的变量 | |
| Read only headers | ☐ | 仅读取响应头。在不需要处理内容的情况下,可以节省流量 |
| Detect charset on content | ☐ | 根据页面内容识别编码 |
| Emulate browser headers | ☐ | 模拟浏览器请求头 |
| Max redirects count | 0 | 爬虫工具将遵循的最大重定向次数 |
| Follow common redirects | ☑ | 允许在同一域名内进行 http <-> https 和 www.domain <-> domain 的重定向,不受 Max redirects count 限制 |
| Max cookies count | 16 | 保存 cookies 的最大数量 |
| Engine | HTTP (Fast, JavaScript Disabled) | 允许选择 HTTP 引擎(速度更快,无 JavaScript)或 Chrome 引擎(速度较慢,启用 JavaScript) |
| Chrome Headless | ☐ | 如果启用此选项,将不显示浏览器界面 |
| Chrome DevTools | ☑ | 允许使用 Chromium 调试工具 |
| Chrome Log Proxy connections | ☑ | 如果启用此选项,日志中将输出 chrome 连接信息 |
| Chrome Wait Until | networkidle2 | 定义何时认为页面已加载。关于取值的详细信息。 |
| Use HTTP/2 transport | ☐ | 定义是否使用 HTTP/2 代替 HTTP/1.1。例如,Google 和 Majestic 如果使用 HTTP/1.1 会立即封禁。 |
| Don't verify TLS certs | ☐ | 禁用 TLS 证书验证 |
| Randomize TLS Fingerprint | ☐ | 此选项允许通过 TLS 指纹绕过网站封禁 |
| Bypass CloudFlare | ☑ | 自动绕过 CloudFlare 检查 |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | 通过 Chrome 绕过 CF |
| Bypass CloudFlare with Chrome Max Pages | 20 | 通过 Chrome 绕过 CF 时的最大页面数 |
| Subdomains are internal | ☐ | 是否将子域名视为内部链接 |
| Follow links | Internal only | 跳转哪些链接 |
| Follow links limit | 0 | Follow links 限制,应用于每个唯一域名 |
| Skip comment blocks | ☐ | 是否跳过注释块 |