SE::Yandex::Position - Kontrollera webbplatsens positioner för sökord i Yandex
Översikt av scrapern
Scraper för att kontrollera webbplatsers positioner för sökord i Yandex. Tack vare scrapern SE::Yandex::Position kan du automatiskt kontrollera positioner i Yandex sökresultat med dina egna domändatabaser. Genom att använda scrapern SE::Yandex::Position kan du enkelt, exakt och snabbt fastställa en webbplats position i Yandex. Kontroll av positioner i Yandex utförs i flertrådat läge, och det finns möjlighet att använda tjänster för att lösa captcha (AntiCaptcha eller någon annan som stöder deras API). Yandex positionsscraper är alltid aktuell eftersom den uppdateras regelbundet av våra specialister.
Funktionaliteten i A-Parser gör det möjligt att spara inställningar för scrapern SE::Yandex::Position för framtida bruk (förinställningar), schemalägga dataskrapning och mycket mer. Du kan använda automatisk ersättning av underfrågor från filer.
Resultaten kan sparas i det format och den struktur du behöver, tack vare den inbyggda kraftfulla mallmotorn Template Toolkit som gör det möjligt att tillämpa ytterligare logik på resultaten och exportera data i olika format, inklusive JSON, SQL och CSV.
Användningsfall för scrapern
🔗 Översikt över visningsalternativ
Artikeln går igenom 4 olika alternativ för att presentera resultat: text, CSV, JSON, HTML
🔗 ⏩Positioner för flera regioner
Hämta webbplatsens positioner för flera regioner samtidigt
Insamlade data
- Webbplatsens position och länk till webbsidan
- Lista över alla webbplatsens positioner och länkar till sidor
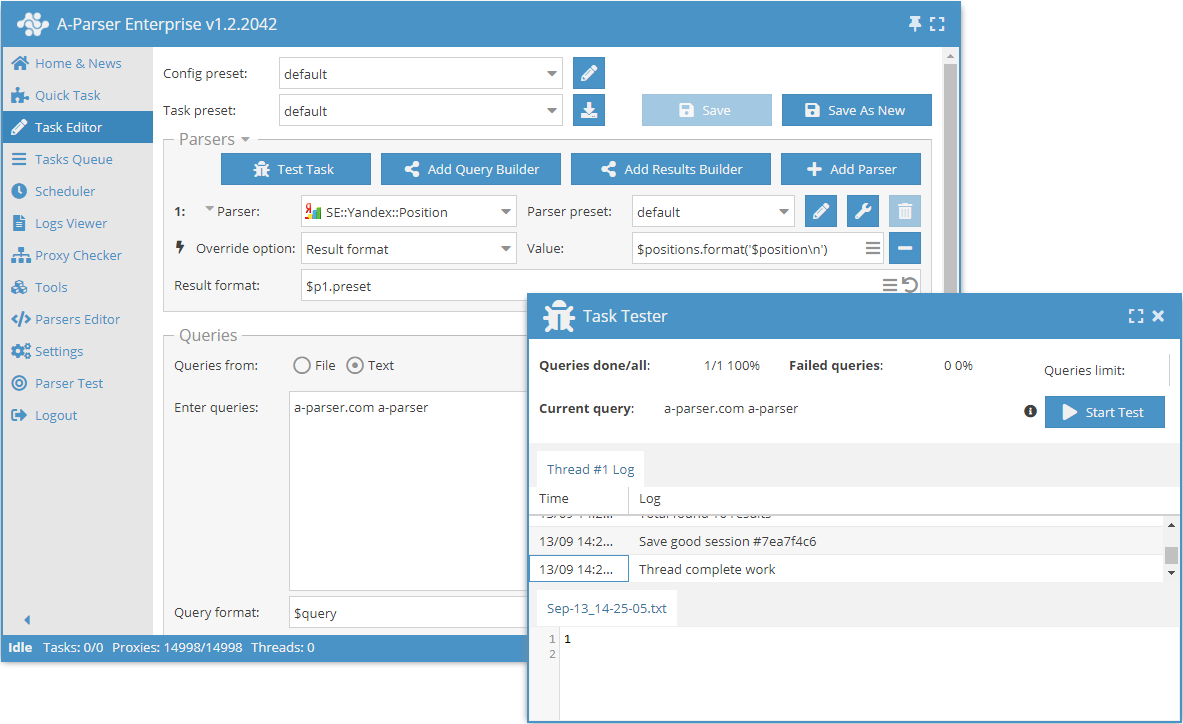
Funktioner
- Alla funktioner i scrapern
 SE::Yandex
SE::Yandex - Stoppar automatiskt dataskrapning när webbplatsen hittas
- Stöder sökning efter underdomäner
- Möjlighet att jämföra den sökta positionen per domän, per huvuddomän och per fullständig länk
- Insamling av positioner för flera domäner samtidigt
Användningsfall
- Kontroll av positioner för egna webbplatser och konkurrenters webbplatser
- Sökning efter sidor med mycket trafik på en webbplats
Frågor
Som frågor måste du ange domänen för den sökta webbplatsen och sökfrågan separerade med ett mellanslag, till exempel:
lenta.ru nyheter
lenta.ru nyheter online
Om du behöver kontrollera en webbplats mot en lista med frågor kan du ange domänen i frågeformatet (Query format):
lenta.ru $query
Eller använd helt enkelt en lista med sökord. För att använda flera domäner samtidigt i en fråga, ange listan med domäner separerade med kommatecken följt av ett mellanslag och sökordet, till exempel:
lenta.ru,ria.ru,notfound.com nyheter flöde
Resultaten kommer att skrivas till arrayen $bulkcheck.
Alternativet Stop when found stöds också; dataskrapningen avslutas om positioner hittas för alla domäner.
Frågeersättningar
Du kan använda inbyggda makron för automatisk ersättning av underfrågor från filer. Om vi till exempel vill kontrollera webbplatser mot en databas med nycklar, anger vi några huvudfrågor:
ria.ru
lenta.ru
rbc.ru
yandex.ru
I frågeformatet anger vi makrot för att infoga ytterligare ord från filen Keywords.txt. Denna metod gör det möjligt att kontrollera en lista med webbplatser mot en lista med nycklar och få positionerna som resultat:
$query {subs:Keywords}
Detta makro kommer att skapa lika många extra frågor som det finns i filen för varje ursprunglig sökfråga, vilket totalt ger [antal ursprungliga frågor (domäner)] x [antal frågor i filen Keywords] = [totalt antal frågor] som ett resultat av makrot.
Exempel på resultatutdata
A-Parser stöder flexibel formatering av resultat tack vare den inbyggda mallmotorn Template Toolkit, vilket gör det möjligt att exportera resultat i valfri form, såväl som i strukturerad form som CSV eller JSON.
Export av positionslista
Hämta resultat i formatet:
sökt domän - nyckel: positionsnummer i sökresultatet
Resultatformat:
$domain - $key: $position\n
Exempel på resultat:
lenta.ru - nyheter: 3
lenta.ru - nyheter online: 13
...
Samtidig kontroll av flera domäner (paketkontroll)
Information om alla domäner vid samtidig kontroll av flera domäner finns i arrayen $bulkcheck.
Resultatformat:
$bulkcheck.format('$domain - $position\n')
Exempel på fråga:
lenta.ru,ria.ru,notfound.com nyheter flöde
Exempel på resultat:
lenta.ru - 1
ria.ru - 4
notfound.com - 0
Länkar + ankare + snippets med positionsutdata
Utdata av länkar, ankare och snippets i en CSV-tabell
Spara relaterade sökord
Sökordskonkurrens
Kontroll av länkindexering
Spara i SQL-format
Dumpa resultat till JSON
Bearbetning av resultat
A-Parser gör det möjligt att bearbeta resultat direkt under dataskrapningen. I det här avsnittet har vi listat de mest populära fallen för scrapern SE::Yandex::Position.
Spara domäner utan nollpositioner
Som bas användes exemplet med samtidig kontroll av flera domäner (se ovan under resultatutdata) och ett filter lades till.
Lägg till ett filter och välj utdatavariabeln för position i rullgardinslistan. Välj typ: >. Skriv sedan in 0 i fältet Number (Nummer). Med ett sådant filter kan du ta bort alla resultat med nollposition.
Ladda ner exempel
Hur man importerar ett exempel till A-Parser
eJx1VE1v2zAM/SuGEKAr4AXJ1gKDDwPSYAE2dE3Xj8OQ5KBGdKtFFj1JTpsF/u+j
ZNlOuu4im9Qj+fhEac8ctxt7bcCCsyxb7FkZ/lnGbr9k2U+uBbxk2TVa6STq5H1y
y7eQCCy41DZ5lu4JK5fw5A8YTMoIYykrubFgfMrFm5kIIiDnlXIs3TO3K4FK4haM
kQJoUwqyczQFd0QowNiWq8rDBg+V2qyfYL0ZNoh3J4OGEfEbtCSWS31yyur/Z68s
lAZfdn3mnCsLBxG5VA4M7UcK2YJ1pX2PbS+rNELvmrjPB2RH9I9lgGXMgrasXq3a
jHYW+PueyvEwSt9teqnvsOEBvXtG1hUvghKCO/C7rRCnQ/fiM3AhAjWumgr+IPqq
91r+DuQ0EpZ+jQQ7M1iQy0FI4J27lt2CDYLtG61C7I8mJkqWMktUZ5yIiNc7kmTh
Ds08aED+PUM9UeoStqB6WMh/UUklaGomOQV9jYFvQ+b/5Ki79g5L0Zk/G+LQZQnW
xfx7HyXwEh+pc/FAfStZSEe2nWKlXTy/DUDZaXblNSvQQFcmZo7V6TKVoP2A9Uc2
KXvXURtHx3LsXKPO5eM8Dm2LrPQd3di5nmJRKvB96Uqp1A/zTT8eExuPwRs9wdfB
01DCt95eReYQlf1221AtjaTxO/cEC1LysGpMueZK3d9cHu6wfqTIUKAdH5oqNTJ8
NLqclBXDNRbJshqdfRRhhbB+6P/PxmFtPJ8a6ENYz/uwuD1a+vdkTXfhEWlKSal6
1T1B3eO2f/shyvY1DcEve93AvWIeTD6S3gbEuP4LmbnKEA==
Se även: Resultatfilter
Dubblettkontroll av länkar
Dubblettkontroll av länkar per domän
Extrahera domäner
Ta bort taggar från ankare och snippets
Filtrera länkar efter förekomst
Möjliga inställningar
Stöder alla inställningar för scrapern SE::Yandex, samt dessutom:
| Parameternamn | Standardvärde | Beskrivning |
|---|---|---|
| Pages count | 1 | Antal sidor att skrapa i sökresultatet (från 1 till 25) |
| Links per page | 20 | Antal länkar i sökresultatet per sida (10 / 20 / 30 / 50) |
| Result format | $domain - $key: $position\n | Standardformat för resultatutdata |
| Stop when found | ☑ | Stoppa dataskrapning om domänen hittas, går inte vidare till nästa sidor |
| Match type | Exact domain | Möjlighet att jämföra den sökta positionen per domän, per huvuddomän och per fullständig länk (Exact domain / Top level domain / Exact url) |