SE::Yandex::Position - Sprawdzanie pozycji strony internetowej według słów kluczowych w Yandex
Przegląd scrapera
Scraper do sprawdzania pozycji strony internetowej według słów kluczowych w Yandex. Dzięki scraperowi SE::Yandex::Position będziesz mógł automatycznie sprawdzać pozycje w wynikach wyszukiwania Yandex, korzystając z własnych baz domen. Używając scrapera SE::Yandex::Position, można łatwo, dokładnie i szybko określić pozycję strony w Yandex. Sprawdzanie pozycji w Yandex odbywa się w trybie wielowątkowym, istnieje możliwość korzystania z serwisów do rozwiązywania captchy (AntiCaptcha lub dowolnego innego obsługującego ich API). Scraper pozycji Yandex jest zawsze aktualny, ponieważ jest regularnie aktualizowany przez naszych specjalistów.
Funkcjonalność A-Parser pozwala na zapisywanie ustawień scrapowania scrapera SE::Yandex::Position do dalszego wykorzystania (presety), ustawianie harmonogramu scrapowania i wiele więcej. Możesz korzystać z automatycznego podstawiania podzapytań z plików.
Zapisywanie wyników jest możliwe w dowolnej formie i strukturze, której potrzebujesz, dzięki wbudowanemu potężnemu silnikowi szablonów Template Toolkit, który pozwala na stosowanie dodatkowej logiki do wyników i wyprowadzanie danych w różnych formatach, w tym JSON, SQL i CSV.
Przypadki użycia scrapera
🔗 Przegląd opcji prezentacji
W artykule omówiono 4 różne opcje prezentacji wyników: tekst, CSV, JSON, HTML
🔗 ⏩Pozycje dla wielu regionów
Pobieranie pozycji witryny jednocześnie dla wielu regionów
Zbierane dane
- Pozycja strony i link do strony witryny
- Lista wszystkich pozycji strony i linków do stron
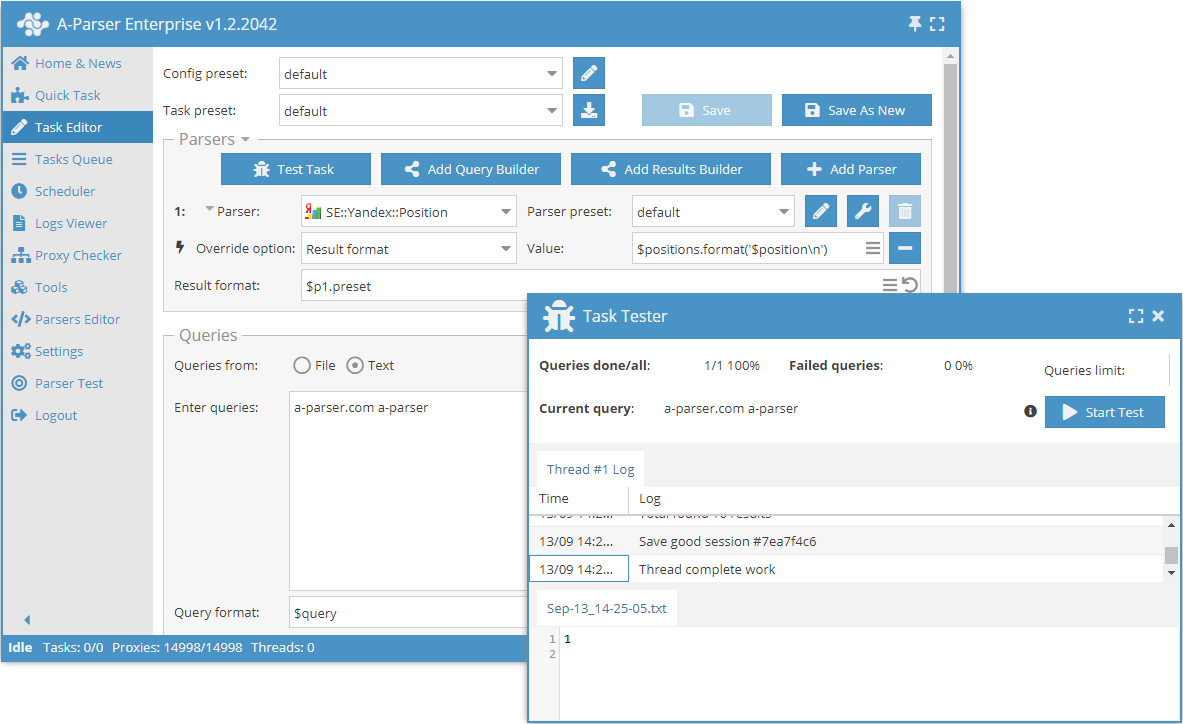
Możliwości
- Wszystkie możliwości scrapera
 SE::Yandex
SE::Yandex - Automatycznie zatrzymuje scrapowanie po znalezieniu strony
- Obsługuje wyszukiwanie subdomen
- Możliwość porównywania szukanej pozycji według domeny, domeny głównej oraz pełnego linku
- Zbieranie pozycji jednocześnie dla kilku domen
Warianty użycia
- Sprawdzanie pozycji własnych stron oraz stron konkurencji
- Wyszukiwanie stron generujących ruch
Zapytania
Jako zapytania należy podawać domenę szukanej strony oraz słowo kluczowe po spacji, na przykład:
lenta.ru wiadomości
lenta.ru wiadomości online
Jeśli trzeba sprawdzić jedną stronę dla listy zapytań, można podać domenę w formacie zapytania (Query format):
lenta.ru $query
Lub użyć po prostu listy słów kluczowych. Aby użyć kilku domen w zapytaniu jednocześnie, należy podać listę domen po przecinku i po spacji słowo kluczowe, na przykład:
lenta.ru,ria.ru,notfound.com wiadomości lenta
Wyniki zostaną zapisane w tablicy $bulkcheck.
Opcja Stop when found jest również obsługiwana, scrapowanie zakończy się, jeśli dla wszystkich domen zostaną znalezione pozycje.
Podstawianie zapytań
Możesz używać wbudowanych makr do automatycznego podstawiania podzapytań z plików, na przykład chcemy sprawdzić strony/stronę według bazy kluczy, podajmy kilka głównych zapytań:
ria.ru
lenta.ru
rbc.ru
yandex.ru
W formacie zapytań podajmy makro podstawiania dodatkowych słów z pliku Keywords.txt, ta metoda pozwala sprawdzać bazę stron według bazy kluczy i otrzymać w rezultacie pozycje:
$query {subs:Keywords}
To makro utworzy tyle samo dodatkowych zapytań, ile znajduje się w pliku dla każdego wyjściowego zapytania, co w sumie da [liczba zapytań wyjściowych(domeny)] x [liczba zapytań w pliku Keywords] = [całkowita liczba zapytań] w wyniku działania makra.
Warianty wyprowadzania wyników
A-Parser obsługuje elastyczne formatowanie wyników dzięki wbudowanemu silnikowi szablonów Template Toolkit, co pozwala mu wyprowadzać wyniki w dowolnej formie, a także w formie strukturalnej, np. CSV lub JSON
Eksport listy pozycji
Otrzymywanie wyniku w postaci:
szukana domena - klucz: numer pozycji w wynikach
Format wyniku:
$domain - $key: $position\n
Przykład wyniku:
lenta.ru - wiadomości: 3
lenta.ru - wiadomości online: 13
...
Jednoczesne sprawdzanie kilku domen (sprawdzanie pakietowe)
Informacje o wszystkich domenach przy jednoczesnym sprawdzaniu kilku domen znajdują się w tablicy $bulkcheck.
Format wyniku:
$bulkcheck.format('$domain - $position\n')
Przykład zapytania:
lenta.ru,ria.ru,notfound.com wiadomości lenta
Przykład wyniku:
lenta.ru - 1
ria.ru - 4
notfound.com - 0
Linki + anchory + snippety z wyprowadzeniem pozycji
Analogicznie jak w SE::Yandex.
Wyprowadzanie linków, anchorów i snippetów do tabeli CSV
Analogicznie jak w SE::Yandex.
Zapisywanie powiązanych słów kluczowych
Analogicznie jak w SE::Yandex.
Konkurencja słów kluczowych
Analogicznie jak w SE::Yandex.
Sprawdzanie indeksacji linków
Analogicznie jak w SE::Yandex.
Zapisywanie w formacie SQL
Analogicznie jak w SE::Yandex.
Zrzut wyników do JSON
Analogicznie jak w SE::Yandex.
Przetwarzanie wyników
A-Parser pozwala przetwarzać wyniki bezpośrednio podczas scrapowania, w tej sekcji przedstawiliśmy najpopularniejsze przypadki dla scrapera SE::Yandex::Position
Zapisywanie domen bez zerowych pozycji
Za podstawę wzięto przykład jednoczesnego sprawdzania kilku domen (patrz wyżej w wariantach wyprowadzania wyników) i dodano filtr.
Dodaj filtr i z listy rozwijanej wybierz zmienną wyprowadzania pozycji. Wybierz typ: >. Następnie w polu Number (Liczba) wpisz 0. Takim filtrem będziesz mógł usunąć wszystkie wyniki z zerową pozycją.
Pobierz przykład
Jak zaimportować przykład do A-Parser
eJx1VE1v2zAM/SuGEKAr4AXJ1gKDDwPSYAE2dE3Xj8OQ5KBGdKtFFj1JTpsF/u+j
ZNlOuu4im9Qj+fhEac8ctxt7bcCCsyxb7FkZ/lnGbr9k2U+uBbxk2TVa6STq5H1y
y7eQCCy41DZ5lu4JK5fw5A8YTMoIYykrubFgfMrFm5kIIiDnlXIs3TO3K4FK4haM
kQJoUwqyczQFd0QowNiWq8rDBg+V2qyfYL0ZNoh3J4OGEfEbtCSWS31yyur/Z68s
lAZfdn3mnCsLBxG5VA4M7UcK2YJ1pX2PbS+rNELvmrjPB2RH9I9lgGXMgrasXq3a
jHYW+PueyvEwSt9teqnvsOEBvXtG1hUvghKCO/C7rRCnQ/fiM3AhAjWumgr+IPqq
91r+DuQ0EpZ+jQQ7M1iQy0FI4J27lt2CDYLtG61C7I8mJkqWMktUZ5yIiNc7kmTh
Ds08aED+PUM9UeoStqB6WMh/UUklaGomOQV9jYFvQ+b/5Ki79g5L0Zk/G+LQZQnW
xfx7HyXwEh+pc/FAfStZSEe2nWKlXTy/DUDZaXblNSvQQFcmZo7V6TKVoP2A9Uc2
KXvXURtHx3LsXKPO5eM8Dm2LrPQd3di5nmJRKvB96Uqp1A/zTT8eExuPwRs9wdfB
01DCt95eReYQlf1221AtjaTxO/cEC1LysGpMueZK3d9cHu6wfqTIUKAdH5oqNTJ8
NLqclBXDNRbJshqdfRRhhbB+6P/PxmFtPJ8a6ENYz/uwuD1a+vdkTXfhEWlKSal6
1T1B3eO2f/shyvY1DcEve93AvWIeTD6S3gbEuP4LmbnKEA==
Zobacz również: Filtry wyników
Usuwanie duplikatów linków
Analogicznie jak w SE::Yandex.
Usuwanie duplikatów linków według domeny
Analogicznie jak w SE::Yandex.
Wyodrębnianie domen
Analogicznie jak w SE::Yandex.
Usuwanie tagów z anchorów i snippetów
Analogicznie jak w SE::Yandex.
Filtrowanie linków według występowania
Analogicznie jak w SE::Yandex.
Możliwe ustawienia
Obsługuje wszystkie ustawienia scrapera SE::Yandex, a dodatkowo:
| Nazwa parametru | Wartość domyślna | Opis |
|---|---|---|
| Pages count | 1 | Liczba stron scrapowania wyników (od 1 do 25) |
| Links per page | 20 | Liczba linków w wynikach na stronę (10 / 20 / 30 / 50) |
| Result format | $domain - $key: $position\n | Domyślny format wyprowadzania wyniku |
| Stop when found | ☑ | Zatrzymaj scrapowanie, jeśli domena zostanie znaleziona, nie będzie przechodzić na kolejne strony |
| Match type | Exact domain | Możliwość porównywania szukanej pozycji według domeny, domeny głównej oraz pełnego linku (Exact domain / Top level domain / Exact url) |