SE::Yandex::Position - 在 Yandex 中按关键词检查网站排名
SE::Yandex::Position 爬虫工具概览
用于在 Yandex 中按关键词检查网站排名的爬虫工具。借助 SE::Yandex::Position 爬虫工具,您可以使用自己的域名库自动检查搜索结果中的排名。使用 SE::Yandex::Position 爬虫工具可以轻松、准确且快速地确定网站在 Yandex 中的排名。Yandex 排名检查以多线程模式执行,并支持使用验证码识别服务(AntiCaptcha 或任何其他支持其 API 的服务)。Yandex 排名爬虫工具始终保持最新状态,因为我们的专家会定期对其进行更新。
A-Parser 的功能允许保存 SE::Yandex::Position 爬虫工具的数据抓取设置以供将来使用(预设),设置数据抓取计划等等。您可以从文件中使用子查询的自动替换。
得益于内置强大的 Template Toolkit 模板引擎,可以将结果保存为您需要的任何形式和结构,该引擎允许对结果应用额外的逻辑,并以各种格式输出数据,包括 JSON、SQL 和 CSV。
爬虫工具应用案例
🔗 显示选项概览
本文介绍了 4 种不同的结果显示选项:文本、CSV、JSON、HTML
🔗 ⏩多个地区的排名
同时获取网站在多个地区的排名
采集的数据
- 网站排名和页面链接
- 网站所有排名和页面链接的列表
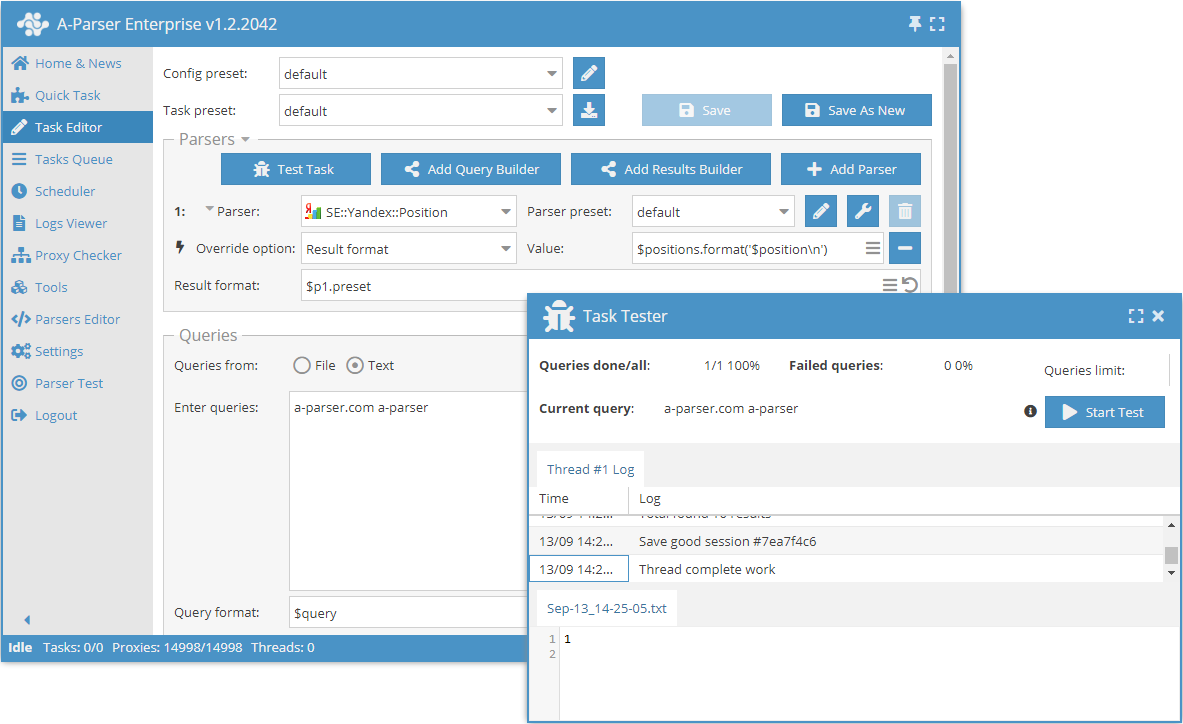
功能
- 爬虫工具
 SE::Yandex 的所有功能
SE::Yandex 的所有功能 - 找到网站时自动停止数据抓取
- 支持搜索子域名
- 可以按域名、主域名和完整链接比较所查找的排名
- 同时采集多个域名的排名
使用场景
- 检查自己网站和竞争对手网站的排名
- 查找网站的流量页面
查询
在查询中,需要指定目标网站的域名和搜索词,中间用空格分隔,例如:
lenta.ru 新闻
lenta.ru 在线新闻
如果需要按查询列表检查一个网站,可以在查询格式(Query format)中指定域名:
lenta.ru $query
或者直接使用关键词列表。要在查询中同时使用多个域名,需要用逗号分隔域名列表,然后加空格和关键词,例如:
lenta.ru,ria.ru,notfound.com 新闻 栏目
结果将写入数组 $bulkcheck。
Stop when found 选项同样受支持,如果所有域名都找到了排名,数据抓取将结束。
查询替换
您可以使用 内置宏 从文件中自动替换子查询,例如我们想按关键词库检查网站,指定几个主要查询:
ria.ru
lenta.ru
rbc.ru
yandex.ru
在查询格式中指定从文件 Keywords.txt 替换额外词汇的宏,此方法允许按关键词库检查网站库并获取排名结果:
$query {subs:Keywords}
该宏将为每个原始搜索查询创建与文件中相同数量的额外查询,结果将产生 [原始查询数量(域名)] x [Keywords 文件中的查询数量] = [总查询数量]。
结果输出选项
得益于内置的 Template Toolkit 模板引擎,A-Parser 支持灵活的结果格式化,这使其能够以任意形式以及结构化形式(如 CSV 或 JSON)输出结果。
导出排名列表
获取如下形式的结果:
目标域名 - 关键词: 搜索结果中的排名编号
结果格式:
$domain - $key: $position\n
结果示例:
lenta.ru - 新闻: 3
lenta.ru - 在线新闻: 13
...
同时检查多个域名(批量检查)
同时检查多个域名时,所有域名的信息都包含在 $bulkcheck 数组中。
结果格式:
$bulkcheck.format('$domain - $position\n')
查询示例:
lenta.ru,ria.ru,notfound.com 新闻 栏目
结果示例:
lenta.ru - 1
ria.ru - 4
notfound.com - 0
带有排名输出的链接 + 锚点 + 描述
将链接、锚点和描述输出到 CSV 表格
保存相关关键词
关键词竞争度
检查链接收录情况
以 SQL 格式保存
将结果转储为 JSON
结果处理
A-Parser 允许在数据抓取过程中直接处理结果,在本节中,我们列出了 SE::Yandex::Position 爬虫工具最常用的案例。
保存非零排名的域名
以同时检查多个域名的示例为基础(见上文结果输出选项),并添加了过滤器。
添加过滤器,并在下拉列表中选择排名输出变量。选择类型:>。接着在Number (数字)中填写 0。通过此过滤器,您可以排除所有排名为零的结果。
下载示例
eJx1VE1v2zAM/SuGEKAr4AXJ1gKDDwPSYAE2dE3Xj8OQ5KBGdKtFFj1JTpsF/u+j
ZNlOuu4im9Qj+fhEac8ctxt7bcCCsyxb7FkZ/lnGbr9k2U+uBbxk2TVa6STq5H1y
y7eQCCy41DZ5lu4JK5fw5A8YTMoIYykrubFgfMrFm5kIIiDnlXIs3TO3K4FK4haM
kQJoUwqyczQFd0QowNiWq8rDBg+V2qyfYL0ZNoh3J4OGEfEbtCSWS31yyur/Z68s
lAZfdn3mnCsLBxG5VA4M7UcK2YJ1pX2PbS+rNELvmrjPB2RH9I9lgGXMgrasXq3a
jHYW+PueyvEwSt9teqnvsOEBvXtG1hUvghKCO/C7rRCnQ/fiM3AhAjWumgr+IPqq
91r+DuQ0EpZ+jQQ7M1iQy0FI4J27lt2CDYLtG61C7I8mJkqWMktUZ5yIiNc7kmTh
Ds08aED+PUM9UeoStqB6WMh/UUklaGomOQV9jYFvQ+b/5Ki79g5L0Zk/G+LQZQnW
xfx7HyXwEh+pc/FAfStZSEe2nWKlXTy/DUDZaXblNSvQQFcmZo7V6TKVoP2A9Uc2
KXvXURtHx3LsXKPO5eM8Dm2LrPQd3di5nmJRKvB96Uqp1A/zTT8eExuPwRs9wdfB
01DCt95eReYQlf1221AtjaTxO/cEC1LysGpMueZK3d9cHu6wfqTIUKAdH5oqNTJ8
NLqclBXDNRbJshqdfRRhhbB+6P/PxmFtPJ8a6ENYz/uwuD1a+vdkTXfhEWlKSal6
1T1B3eO2f/shyvY1DcEve93AvWIeTD6S3gbEuP4LmbnKEA==
另请参阅:结果过滤器
链接去重
按域名进行链接去重
提取域名
从锚点和描述中删除标签
按包含关系过滤链接
可选设置
支持爬虫工具 SE::Yandex 的所有设置,此外还包括:
| 参数名称 | 默认值 | 描述 |
|---|---|---|
| Pages count | 1 | 搜索结果抓取的页数(1 到 25) |
| Links per page | 20 | 每页搜索结果的链接数量 (10 / 20 / 30 / 50) |
| Result format | $domain - $key: $position\n | 默认结果输出格式 |
| Stop when found | ☑ | 如果找到域名则停止数据抓取,不再跳转到后续页面 |
| Match type | Exact domain | 可以按域名、主域名和完整链接比较所查找的排名 (Exact domain / Top level domain / Exact url) |