FreeAI::Perplexity - Parser für den KI-Dienst Perplexity
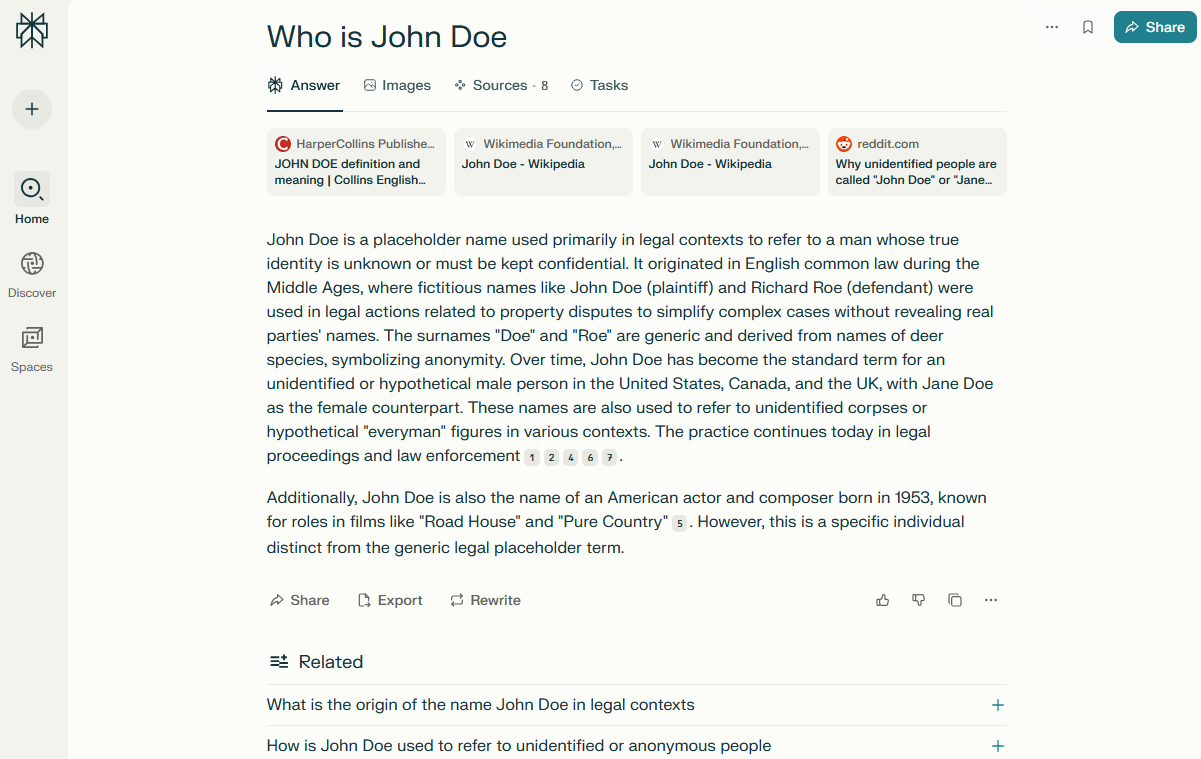
Übersicht des Parsers
Der Perplexity-Parser ist ein modernes Tool zum Sammeln strukturierter Informationen aus einer der am schnellsten wachsenden KI-Suchmaschinen. Dank der Integration mit Perplexity erhalten Sie nicht nur Listen mit Links, sondern aktuelle, prägnante und relevante Antworten, die auf einer Vielzahl von Quellen basieren, darunter wissenschaftliche Artikel, Blogs, Foren und Nachrichtenportale.
Der Perplexity-Parser unterstützt Anfragen in natürlicher Sprache, einschließlich Präzisierungen, kontextbezogener Fragen und verschachtelter Konstruktionen. Der Parser bietet die Möglichkeit, relevante Fragen zu erfassen und diese automatisch in die Aufgabenwarteschlange einzufügen, wodurch die Menge der gesammelten Informationen erheblich erweitert wird.
Die Verarbeitungsgeschwindigkeit erreicht dank des Multithreading-Modus 500–800 Anfragen pro Minute. Je nach Konfiguration und verwendeten Presets können Sie innerhalb weniger Minuten Tausende von einzigartigen Textfragmenten und Links erhalten.
Die Ergebnisse der Ausgabe können dank der leistungsstarken Template-Engine Template Toolkit in jedem gewünschten Format gespeichert werden, was die Strukturierung der Daten in JSON, CSV, SQL und anderen Formaten sowie die Filterung, Sortierung und Aggregation der Daten im laufenden Betrieb ermöglicht.
Der Perplexity-Parser eignet sich ideal für Aufgaben der Wettbewerbsbeobachtung, das Sammeln von Fakten und Zitaten, die Erstellung von Wissensdatenbanken, das Monitoring von Nachrichten und die Themenanalyse, dank der hohen Qualität und Kontextbezogenheit der gelieferten Ergebnisse.
Gesammelte Daten
- Antworttext (in Markdown-Formatierung)
- Links, Anker und Snippets der Datenquellen
- Liste ähnlicher Fragen
Funktionen
- Auswahl des Informationsquellentyps (Mehrfachauswahl unterstützt)
- Einfügen ähnlicher Fragen in die Aufgabenwarteschlange bis zur angegebenen Tiefe
- Umgehung von Schutzmechanismen und Unterstützung von Sitzungen für stabileres und schnelleres Arbeiten
Anwendungsfälle
- Sammeln strukturierter Antworten auf Themenanfragen zur Erstellung von Wissensdatenbanken, Content-Plänen, Referenzsystemen und zur FAQ-Generierung
- Extraktion von Quelllinks mit Ankern und Snippets – ideal für den Aufbau von Listen autoritärer Ressourcen, Zitierungen und das Sammeln von Backlinks
- Sammeln von ähnlichen/präzisierenden Fragen aus der Perplexity-Ausgabe – nützlich für die Analyse des Nutzerinteresses, die Bildung des semantischen Kerns und die Generierung von Artikelideen
- Monitoring von Erwähnungen von Marken, Produkten oder Personen – mit Bezug zum Kontext und den Quellen
- Suche und Analyse von Expertenmeinungen, Trends und Insights aus autoritären Quellen
- Schnelle Überprüfung der Aktualität und Vollständigkeit von Informationen zu Schlüsselthemen
- Automatisierung der Wettbewerbsanalyse: Welche Ressourcen werden zitiert, welche Themen werden wie oft behandelt
- Unterstützung von Forschungs- und Analyseprojekten, die die Aggregation präziser Informationen aus verschiedenen Quellen erfordern
- Alle anderen Aufgaben, bei denen schnell kurze, präzise Antworten mit Bestätigung durch reale Quellen und logischem Kontext benötigt werden
Anfragen
Als Anfragen müssen Suchbegriffe angegeben werden, genau so, als ob sie direkt in das Suchformular von Perplexity eingegeben würden, zum Beispiel:
Wie lernt man schnell zu lernen?
Wie verbessert man Gedächtnis und Konzentration?
Was ist ein Parser?
TOP 10 Websites im russischen Internet
Ergebnisse
Hier und im Folgenden sind die Ergebnisbeispiele zur besseren Übersichtlichkeit gekürzt
Standardmäßig werden die Anfrage und die dazugehörige Antwort ausgegeben, zum Beispiel:
Was ist ein Parser?
Ein Parser ist ein Programm oder Skript, das automatisch Informationen aus verschiedenen Quellen, meist von Websites, sammelt, analysiert und systematisiert[1][2][5][7]. Die Hauptaufgabe eines Parsers besteht darin, die benötigten Daten (z. B. Texte, Preise, Kontakte, Bilder) aus strukturierten oder semistrukturierten Informationsmengen wie HTML-Seiten, Datenbanken, Textdateien und anderen Formaten zu extrahieren[1][5][6].
**Wie ein Parser funktioniert:**
- Scannt die angegebenen Datenquellen (z. B. Webseiten).
...
TOP 10 Websites im russischen Internet
## TOP-10 Websites des Runet im Juni 2025
Basierend auf aktuellen Daten von Similarweb und anderen Analyseressourcen gehören die folgenden Ressourcen zu den meistbesuchten Websites des russischen Internetsegments (Runet):
1. **Yandex.ru** — die größte russische Suchmaschine und Internetportal[2][6].
2. **Google.com** — globale Suchmaschine, die auch in Russland aktiv genutzt wird[2][6].
...
### Tabelle zur Veranschaulichung
| Platz | Website | Hauptfunktion |
|-------|----------------|------------------------------|
| 1 | yandex.ru | Suche, Dienste, Portal |
| 2 | google.com | Suche |
...
Varianten der Ergebnisausgabe
A-Parser unterstützt eine flexible Formatierung der Ergebnisse dank der integrierten Template-Engine Template Toolkit, was die Ausgabe der Ergebnisse in beliebiger Form sowie in strukturierter Form, wie z. B. CSV oder JSON, ermöglicht.
Export einer Linkliste
Ergebnisformat:
$sources.format('$link\n')
Beispielergebnis:
https://ru.wikipedia.org/wiki/%D0%91%D0%B8%D1%82%D0%BA%D0%BE%D0%B9%D0%BD
https://www.kaspersky.ru/resource-center/definitions/what-is-bitcoin
https://dzengi.com/ru/chto-takoe-bitcoin-prostim-yazikom
https://www.sberbank.ru/ru/person/kibrary/vocabulary/bitkoin
https://help.cryptopay.me/ru/articles/3414939-%D1%87%D1%82%D0%BE-%D1%82%D0%B0%D0%BA%D0%BE%D0%B5-%D0%B1%D0%B8%D1%82%D0%BA%D0%BE%D0%B8%D0%BD
...
Ausgabe von Links, Ankern und Snippets mit ihren Positionen in CSV
Ergebnisformat:
[% FOREACH item IN sources;
tools.CSVline(loop.count, item.link, item.anchor, item.snippet);
END %]
Beispielergebnis:
...
6,https://www.kraken.com/ru/learn/what-is-bitcoin-btc,"Was ist Bitcoin (BTC)? Vollständiger Leitfaden - Kraken","Erfahren Sie mehr über die dezentrale Natur von Bitcoin, das begrenzte Angebot und seine Rolle als digitale Währung. Finden Sie heraus, was BTC zugrunde liegt, was seine Grundprinzipien und Anwendungsfälle sind."
7,https://www.vedomosti.ru/finance/articles/2024/09/23/1064026-bitkoin,"Was ist Bitcoin und wofür wird er benötigt - Vedomosti","Dies ist eine digitale Währung, die als Zahlungsmittel und Finanzwert verwendet wird"
8,https://forklog.com/cryptorium/chto-takoe-bitkoin,"Was ist Bitcoin und wie funktioniert er in einfachen Worten? - ForkLog","Bitcoin — ist ein dezentrales System, das auf dem Prinzip des direkten Austauschs zwischen Nutzern basiert. Für Transaktionen wird die gleichnamige Kryptowährung BTC verwendet."
Im Allgemeinen Ergebnisformat wird die Template-Engine Template Toolkit verwendet, um das Array $sources in einer FOREACH-Schleife auszugeben.
Im Namen der Ergebnisdatei muss lediglich die Dateiendung in .csv geändert werden.
Ausgabe von Frage, Antwort und einer Liste ähnlicher Fragen in JSON
Allgemeines Ausgabeformat:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.query = query;
obj.answer = p1.answer;
obj.related = [];
FOREACH item IN p1.related;
obj.related.push(item.text);
END;
obj.json %]
Anfangstext:
[
Endtext:
]
Beispielergebnis:
[{"related":["Warum gilt Bitcoin als die erste Kryptowährung und wie unterscheidet er sich von traditionellem Geld","Wie funktioniert die Blockchain-Technologie, die Bitcoin zugrunde liegt","Welche kryptografischen Methoden schützen Transaktionen im Bitcoin-System","Warum macht die Begrenzung auf 21 Millionen Münzen Bitcoin zu einem einzigartigen Vermögenswert","Welche Vorteile bietet die Dezentralisierung und das Fehlen von Vermittlern bei der Nutzung von Bitcoin"],"answer":"**Bitcoin** (Bitcoin, BTC) — ist die erste und bekannteste Kryptowährung, ein dezentrales digitales Zahlungssystem, das auf der Blockchain-Technologie basiert. In diesem System werden alle Transaktionen in einem öffentlichen Register (Blockchain) aufgezeichnet, das durch kryptografische Methoden geschützt und für jeden Netzwerkteilnehmer überprüfbar ist[1][3][4].\n...","query":"Was ist Bitcoin?"},{"related":["Welche Grundregeln und Tipps helfen beim richtigen Googeln","Warum ist es wichtig, Fragen und komplexe Sätze bei der Suche zu vermeiden","Wie man Englisch für eine effizientere Suche in Google nutzt","Welche Operatoren und Symbole helfen, die Suche zu erweitern oder zu präzisieren","Was ist der Unterschied zwischen der Verwendung von Anführungszeichen und der Tilde bei der Informationssuche"],"answer":"## Richtig googeln: Die wichtigsten Tipps\n\n**Formulieren Sie Anfragen kurz und prägnant**\n- Verwenden Sie 2–6 Schlüsselwörter, vermeiden Sie lange Fragen und komplexe Sätze. Zum Beispiel, statt \"was tun wenn das internet auf meinem windows computer nicht funktioniert?\" verwenden Sie \"internet funktioniert nicht windows wie beheben\"[1].\n\n**Suchen Sie nach exakten Phrasen**\n...","query":"Wie googelt man richtig?"}]
Mögliche Einstellungen
| Parametername | Standardwert | Beschreibung |
|---|---|---|
| Sources | Web | Typ der Informationsquelle (Mehrfachauswahl unterstützt) |
| Use sessions | ☑ | Speichert gute Sitzungen, was eine noch schnellere Datenerfassung bei weniger Fehlern ermöglicht |
| Bypass CloudFlare | ☑ | Automatische Umgehung des CloudFlare-Schutzes |
| Bypass CloudFlare Browser Max Pages | 10 | Max. Anzahl der Seiten bei der CF-Umgehung |
| Bypass CloudFlare Browser Headless | ☑ | Wenn diese Option aktiviert ist, wird der Browser während der CF-Umgehung nicht angezeigt |