SE::Yandex::WordStat::ByRegion -
Übersicht des Parsers
Wordstat ist ein Dienst von Yandex, der zur Bewertung des Nutzerinteresses an verschiedenen Themen und zur Auswahl von Keywords für die SEO-Optimierung und Kontextwerbung entwickelt wurde. Darüber hinaus kann man mit Wordstat Yandex die Saisonalität und geografische Abhängigkeit von Suchanfragen bewerten.
Der Parser Yandex WordStat by region unterstützt die automatische Multiplikation von Abfragen, sodass Sie sicher sein können, die maximale Anzahl an Ergebnissen aus der Ausgabe zu erhalten. Zudem kann A-Parser automatisch verwandten Abfragen bis zu einer bestimmten Tiefe folgen.
Die Funktionalität von A-Parser ermöglicht es, Datenerfassung-Einstellungen für die spätere Verwendung zu speichern (Presets), Zeitpläne für die Datenerfassung festzulegen und vieles mehr. Sie können die automatische Multiplikation von Abfragen, die Substitution von Unterabfragen aus Dateien, das Durchlaufen von alphanumerischen Kombinationen und Listen nutzen, um die höchstmögliche Anzahl an Ergebnissen zu erzielen.
Das Speichern der Ergebnisse ist in der von Ihnen benötigten Form und Struktur möglich, dank der integrierten leistungsstarken Template-Engine Template Toolkit, die es erlaubt, zusätzliche Logik auf die Ergebnisse anzuwenden und Daten in verschiedenen Formaten auszugeben, einschließlich JSON, SQL und CSV.
Accounts
Für den Betrieb des Parsers  SE::Yandex::WordStat::ByRegion sind Yandex-Accounts erforderlich. Accounts können mit dem Parser
SE::Yandex::WordStat::ByRegion sind Yandex-Accounts erforderlich. Accounts können mit dem Parser  SE::Yandex::Register registriert oder einfach vorhandene Accounts zur Datei
SE::Yandex::Register registriert oder einfach vorhandene Accounts zur Datei files/SE-Yandex/accounts.txt im unterstützten Format hinzugefügt werden.
Alternativ kann die Registrierung von Accounts "on-the-fly" aktiviert werden.
Gesammelte Daten
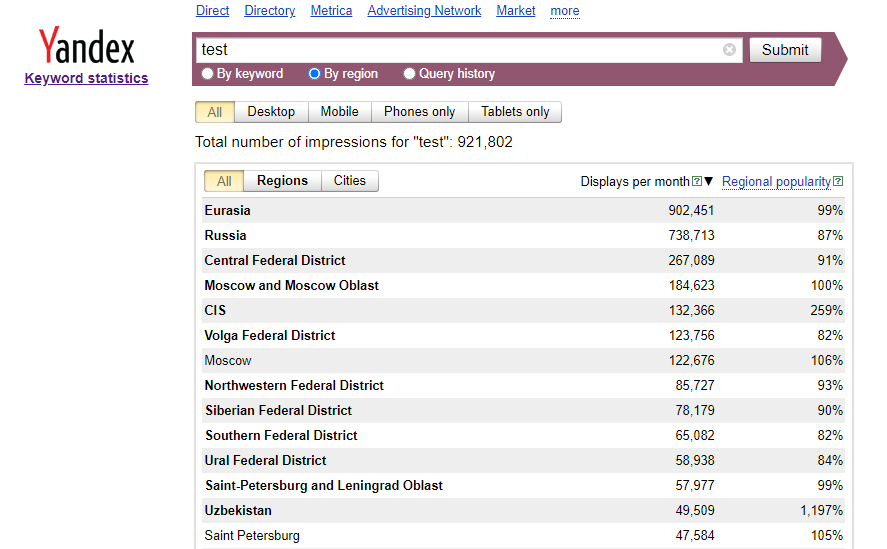
- Gesamtanzahl der Impressionen pro Abfrage
- Keyword-Statistiken nach Regionen und Städten:
- Region/Stadt
- Anzahl der Aufrufe pro Monat
- Regionale Popularität in %
Funktionen
- Unterstützung für die automatische Umgehung von Smart Captcha und die Möglichkeit, grafische Captchas mit dem Dienst AntiCaptcha oder einer anderen API, die diese unterstützt, zu umgehen
- Auswahl des Gerätetyps
- Möglichkeit, die Autorisierungsmethode zu wählen
- Möglichkeit, Accounts "on-the-fly" zu registrieren
- Unterstützt die Arbeit mit dem erweiterten Account-Format und kann die Sicherheitsfrage beantworten (wenn die Antwort in
infovorhanden ist). Zudem wird der gespeicherte Proxy für die Autorisierung verwendet (falls dieser ininfovorhanden ist).
Anwendungsfälle
- Bewertung des Traffic-Volumens für ein Keyword aufgeschlüsselt nach Regionen
Abfragen
Als Abfragen müssen Keywords angegeben werden, genau so, als ob sie direkt in das Wordstat-Suchformular eingegeben würden, zum Beispiel:
test
Ausgabebeispiele
A-Parser unterstützt eine flexible Formatierung der Ergebnisse dank der integrierten Template-Engine Template Toolkit, was es ermöglicht, Ergebnisse in beliebiger Form sowie strukturiert, zum Beispiel als CSV oder JSON, auszugeben.
Standardausgabe
Ergebnisformat:
$query - Total views: $totalcount\nViews by regions:\n$regions.format('$region $count, $popularity%\n')\nViews by cities:\n$cities.format('$city $count, $popularity%\n')
Das Ergebnis zeigt die Anzahl der Impressionen pro Abfrage, Keyword-Statistiken nach Regionen und Städten, die Anzahl der Aufrufe pro Monat und die regionale Popularität:
test - Total views: 872855
Views by regions:
Moskau und Moskauer Gebiet 147107, 85%
Zentrum 194716, 77%
Nordwest 55815, 70%
Süd 31759, 67%
Wolga-Region 86006, 66%
...
Views by cities:
Tschita 2937, 113%
Sankt Petersburg 35713, 73%
Belgorod 2737, 58%
Iwanowo 1773, 55%
Kaluga 2196, 64%
Kostroma 1166, 49%
Ausgabe in eine CSV-Tabelle
Ergebnisformat:
[% FOREACH i IN regions;
tools.CSVline(query, i.popularity, i.region, i.count);
END %]
Beispielergebnis:
"test",88,"Moskau und Moskauer Gebiet",1902795
"test",96,"Zentrum",2992864
"test",95,"Nordwest",926138
"test",112,Süd,647140
"test",124,"Wolga-Region",1927873
"test",64,"Westen",60975
"test",86,"Osten",427304
Speichern im SQL-Format
Ergebnisformat:
[% FOREACH i IN regions;
"INSERT INTO regions VALUES('" _ query _ "', '"; i.popularity _ "', '"; i.count _ "', '"; i.region _ "')\n";
END %]
Beispielergebnis:
INSERT INTO regions VALUES('test', '88', '1902795', 'Moskau und Moskauer Gebiet')
INSERT INTO regions VALUES('test', '96', '2992864', 'Zentrum')
INSERT INTO regions VALUES('test', '95', '926138', 'Nordwest')
INSERT INTO regions VALUES('test', '112', '647140', 'Süd')
INSERT INTO regions VALUES('test', '124', '1927873', 'Wolga-Region')
INSERT INTO regions VALUES('test', '64', '60975', 'Westen')
INSERT INTO regions VALUES('test', '86', '427304', 'Osten')
INSERT INTO regions VALUES('test', '80', '89569', 'Süd')
INSERT INTO regions VALUES('test', '75', '356560', 'Zentrum')
INSERT INTO regions VALUES('test', '77', '34894', 'Norden')
Ergebnis-Dump in JSON
Allgemeines Ausgabeformat:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.totalcount = p1.totalcount;
obj.regions = [];
FOREACH item IN p1.regions;
obj.regions.push({
popularity = item.popularity
region = item.region
count = item.count
});
END;
obj.json %]
Anfangstext:
[
Endtext:
]
Beispielergebnis:
[
{
"regions": [
{
"count": "1902795",
"popularity": 88,
"region": "Moskau und Moskauer Gebiet"
},
{
"count": "2992864",
"popularity": 96,
"region": "Zentrum"
},
{
"count": "926138",
"popularity": 95,
"region": "Nordwest"
},
{
"count": "647140",
"popularity": 112,
"region": "Süd"
},
{
"count": "34894",
"popularity": 77,
"region": "Norden"
},
],
"totalcount": "10837937"
}
]
Siehe auch: Ergebnisfilter
Mögliche Einstellungen
| Parameter | Standardwert | Beschreibung |
|---|---|---|
| AntiGate preset | default | Es ist notwendig, vorab den Parser  Util::AntiGate zu konfigurieren – geben Sie Ihren Zugriffsschlüssel und andere Parameter an und wählen Sie dann hier das erstellte Preset aus. Util::AntiGate zu konfigurieren – geben Sie Ihren Zugriffsschlüssel und andere Parameter an und wählen Sie dann hier das erstellte Preset aus. |
| AntiGate preset for Login | default | AntiGate-Preset für den Login. Es ist notwendig, vorab den Parser Util::AntiGate mit Parametern zu konfigurieren und dann hier das erstellte Preset auszuwählen. |
| Type | All | Auswahl des Gerätetyps |
| Accounts | Only from "accounts.txt" | Auswahl der Methode für die Arbeit mit Accounts: Always auto register - Accounts immer automatisch "on-the-fly" registrieren, erfordert die Auswahl eines konfigurierten Presets im Parameter SE::Yandex::Register preset. Auto register if no more in "accounts.txt" - zuerst werden vorhandene Accounts aus accounts.txt verwendet, und wenn diese aufgebraucht sind, wird die automatische Registrierung "on-the-fly" genutzt, wofür entsprechend ein konfiguriertes Preset im Parameter SE::Yandex::Register preset gewählt werden muss. Only from "accounts.txt" - nur vorhandene Accounts aus accounts.txt verwenden, und wenn diese aufgebraucht sind - die festgelegte Zeit warten (Parameter Wait new accounts in "accounts.txt"), bis neue erscheinen |
| Wait new accounts in "accounts.txt" | 0 | Wartezeit auf das Erscheinen neuer Accounts in accounts.txt |
| Remove bad accounts | Always, except wrong login/password | Automatisches Löschen "schlechter" Accounts: Always - immer löschen. Always, except wrong login/password - immer löschen, außer wenn Yandex meldet, dass Login/Passwort falsch sind. Der Grund ist, dass Yandex eine solche Meldung auch bei einer IP-Sperre für einen voll funktionsfähigen Account ausgeben kann, daher können solche Accounts optional für die Wiederverwendung behalten werden. Never - niemals löschen. Unabhängig von der gewählten Option werden Accounts bei Proxy-/Browserfehlern nicht gelöscht |
| SE::Yandex::Register preset | default | Auswahl des Einstellungs-Presets für SE::Yandex::Register |
| Authorization method | HTTP | Autorisierungsmethode: HTTP - schnell, ressourcenschonend. Chrome - langsam, ressourcenintensiv, kann theoretisch die Lebensdauer von Accounts verlängern |
| Chrome headless | ☑ | Wenn diese Option aktiviert ist, wird der Browser nicht angezeigt |
| Use sessions | ☑ | Verwendung von Sitzungen |
| Do not reset session if authorization passed | ☑ | Sitzung bei Fehlern nicht zurücksetzen, wenn der Parser bereits autorisiert ist |
| Use Wordstat 2 | ☐ | Verwendung von Wordstat 2 |
| Wordstat 2 parse all table data | ☑ | Ermöglicht es, sofort alle 2000 Ergebnisse pro Abfrage ohne Paginierung zu exportieren |