OpenAI::Completions - OpenAI Completions Parser
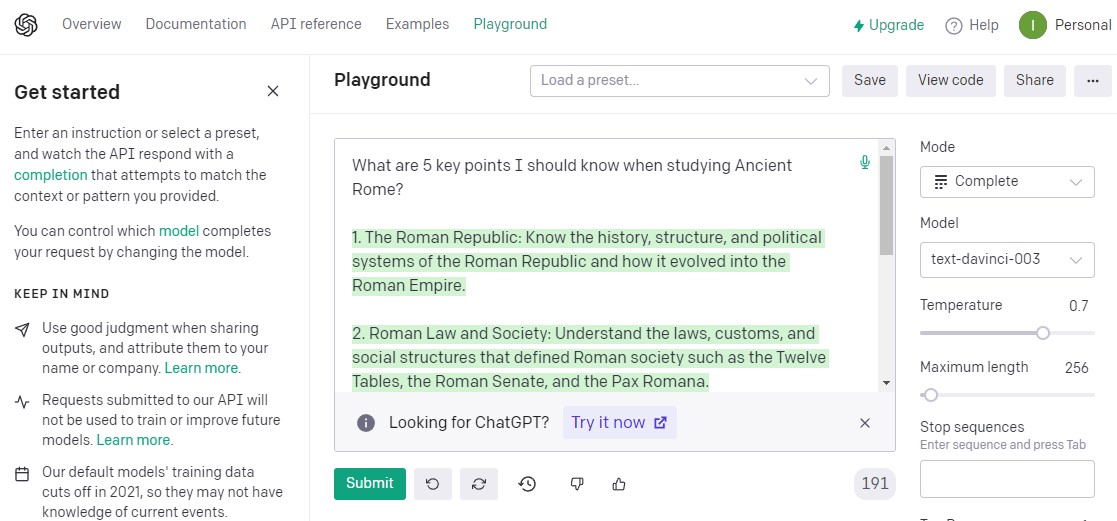
Übersicht über den Parser
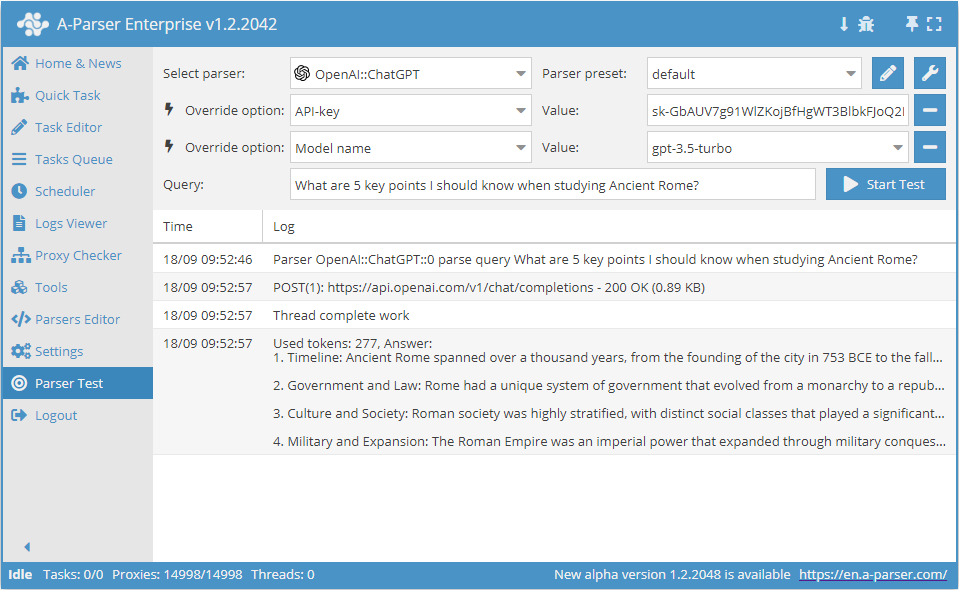
Parser OpenAI Completions. Parser für die Completions-Methode von OpenAI. Erstellt auf Basis der offiziellen API und verwendet einen API-Key. Ähnlich wie der Parser  OpenAI::ChatGPT, der Hauptunterschied liegt im Fehlen der Option System prompt content und anderen Modelltypen für die Generierung.
OpenAI::ChatGPT, der Hauptunterschied liegt im Fehlen der Option System prompt content und anderen Modelltypen für die Generierung.
Die Funktionalität von A-Parser ermöglicht es, die Datenerfassung-Einstellungen dieses Parsers für die spätere Verwendung zu speichern (Presets), einen Zeitplan für die Datenerfassung festzulegen und vieles mehr. Sie können die automatische Abfragevervielfältigung, das Einsetzen von Unterabfragen aus Dateien, das Durchlaufen von alphanumerischen Kombinationen und Listen verwenden, um die maximal mögliche Anzahl an Ergebnissen zu erhalten.
Das Speichern der Ergebnisse ist in der von Ihnen benötigten Form und Struktur möglich, dank der integrierten leistungsstarken Template-Engine Template Toolkit, die es ermöglicht, zusätzliche Logik auf die Ergebnisse anzuwenden und Daten in verschiedenen Formaten auszugeben, einschließlich JSON, SQL und CSV.
Gesammelte Daten
- Antwort von OpenAI
- Anzahl der verwendeten Token
Funktionen
- Antwort von OpenAI extrahieren
Anwendungsfälle
- Generierung von Antworten von OpenAI auf beliebige Fragen
Abfragen
Als Abfragen muss der Text in einer Zeile angegeben werden, zum Beispiel:
What are 5 key points I should know when studying Ancient Rome?
Abfrage-Substitutions
Sie können integrierte Makros zur Vervielfältigung von Abfragen verwenden.
Im Abfrageformat geben wir den Durchlauf von Zeichen von a bis zzzz an; diese Methode ermöglicht es, die Suchergebnisse maximal zu rotieren und viele neue einzigartige Ergebnisse zu erhalten:
$query {az:a:zzzz}
Dieses Makro erstellt 475254 zusätzliche Abfragen für jede ursprüngliche Suchanfrage, was insgesamt 4 x 475254 = 1901016 Suchanfragen ergibt. Die Zahl ist beeindruckend, aber für A-Parser stellt dies absolut kein Problem dar. Bei einer Geschwindigkeit von 2000 Abfragen pro Minute wird eine solche Aufgabe in nur 16 Stunden verarbeitet.
Beispiele für die Ergebnisausgabe
A-Parser unterstützt eine flexible Formatierung der Ergebnisse dank der integrierten Template-Engine Template Toolkit, die es ermöglicht, Ergebnisse in beliebiger Form sowie strukturiert, zum Beispiel als CSV oder JSON, auszugeben.
Standardausgabe
Ergebnisformat:
Used tokens: $total_tokens, Answer:\n$answer\n
Beispielergebnis:
Used tokens: 290, Answer:
1. Founding and Early History: Ancient Rome was founded in 753 BCE by twin brothers Romulus and Remus. The city grew to become one of the most powerful and influential empires in world history.
2. Roman Republic: The Roman Republic was established in 509 BCE and lasted until 27 BCE. During this time, Rome developed a complex system of government, with two consuls elected annually, a senate, and assemblies of citizens.
3. Roman Empire: The Roman Empire began in 27 BCE when Augustus became the first Roman emperor. The empire grew to include much of Europe, the Middle East, and North Africa and lasted until the fall of the Western Roman Empire in 476 CE.
4. Achievements and Contributions: Ancient Rome made significant contributions to architecture, engineering, law, philosophy, art, literature, and language. Roman innovations include the arch, concrete, aqueducts, roads, and the Latin alphabet.
5. Decline and Fall: The Roman Empire faced numerous challenges, including economic instability, political corruption, military defeats, and invasions by barbarian tribes. The Western Roman Empire fell in 476 CE, while the Eastern Roman Empire (Byzantine Empire) survived until 1453 CE.
Mögliche Einstellungen
| Parameter | Standardwert | Beschreibung |
|---|---|---|
| API domain | api.openai.com | Möglichkeit, die Domain für API-Anfragen zu ändern |
| API key | API-Key. Es können mehrere angegeben werden (einer pro Zeile); für jeden Versuch wird der Key zufällig aus den verfügbaren und im Rahmen der aktuellen Abfrage nicht verwendeten ausgewählt. | |
| Model name | text-davinci-003 | Modelltyp (gpt-3.5-turbo-instruct / babbage-002 / davinci-002 / text-davinci-003) |
| Temperature | 0.7 | Temperature |
| Top P | 1 | Top P |
| Maximum length | 256 | Maximale Anzahl der verwendeten Token |
| Presence penalty | 0 | Presence penalty |
| Frequency penalty | 0 | Frequency penalty |