HTML::EmailExtractor - Extracción de datos de direcciones de correo electrónico de páginas web
Descripción general del extractor
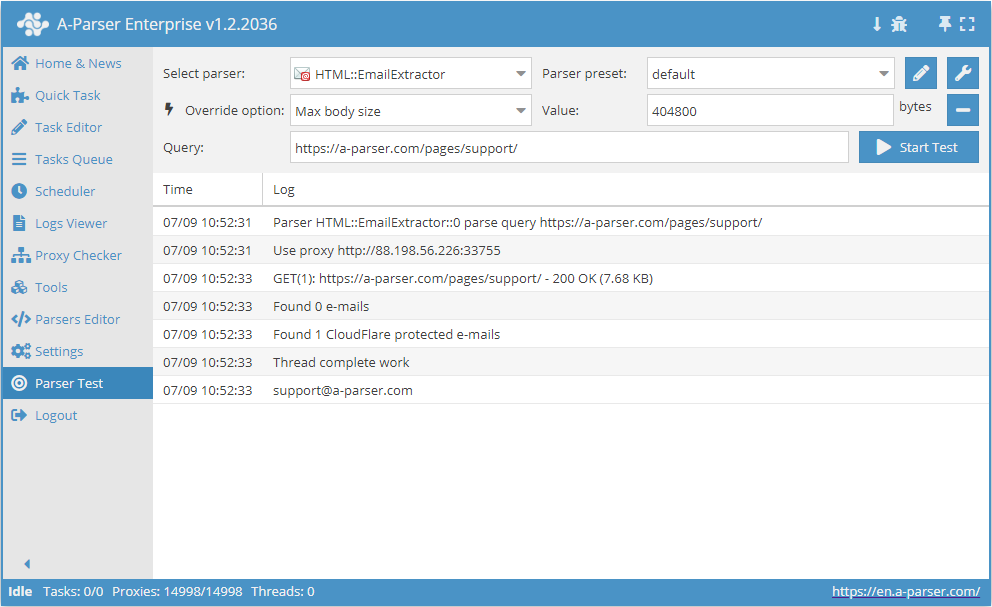
 HTML::EmailExtractor recopila direcciones de correo electrónico de las páginas especificadas. Admite la navegación por páginas internas del sitio hasta la profundidad especificada, lo que permite recorrer todas las páginas del sitio recopilando enlaces internos y externos. El extractor de correos tiene medios integrados para omitir la protección de CloudFlare y también la posibilidad de elegir Chrome como motor para la extracción de correos de páginas cuyos datos se cargan mediante scripts. Es capaz de alcanzar una velocidad de hasta 250 consultas por minuto, lo que equivale a 15 000 enlaces por hora.
HTML::EmailExtractor recopila direcciones de correo electrónico de las páginas especificadas. Admite la navegación por páginas internas del sitio hasta la profundidad especificada, lo que permite recorrer todas las páginas del sitio recopilando enlaces internos y externos. El extractor de correos tiene medios integrados para omitir la protección de CloudFlare y también la posibilidad de elegir Chrome como motor para la extracción de correos de páginas cuyos datos se cargan mediante scripts. Es capaz de alcanzar una velocidad de hasta 250 consultas por minuto, lo que equivale a 15 000 enlaces por hora.Casos de uso del extractor
Extracción de correos de un sitio navegando en profundidad hasta el límite especificado
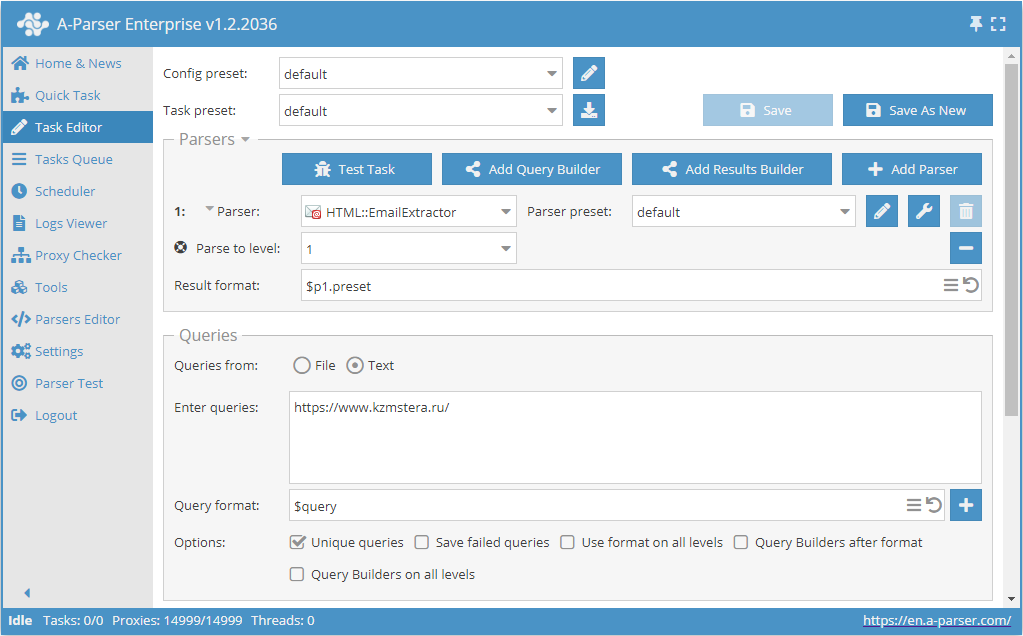
- Añadir la opción Parse to level, en la lista seleccionar el valor necesario (límite).
- En la sección Queries (Consultas), marcar la opción
Unique queries. - En la sección Results (Resultados), marcar la opción
Unique string. - Como consulta, indicar el enlace al sitio del cual se requiere extraer los correos.
Descargar ejemplo
Cómo importar un ejemplo a A-Parser
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
sugerencia
Extracción de correos por base de sitios navegando en cada sitio hasta el límite especificado
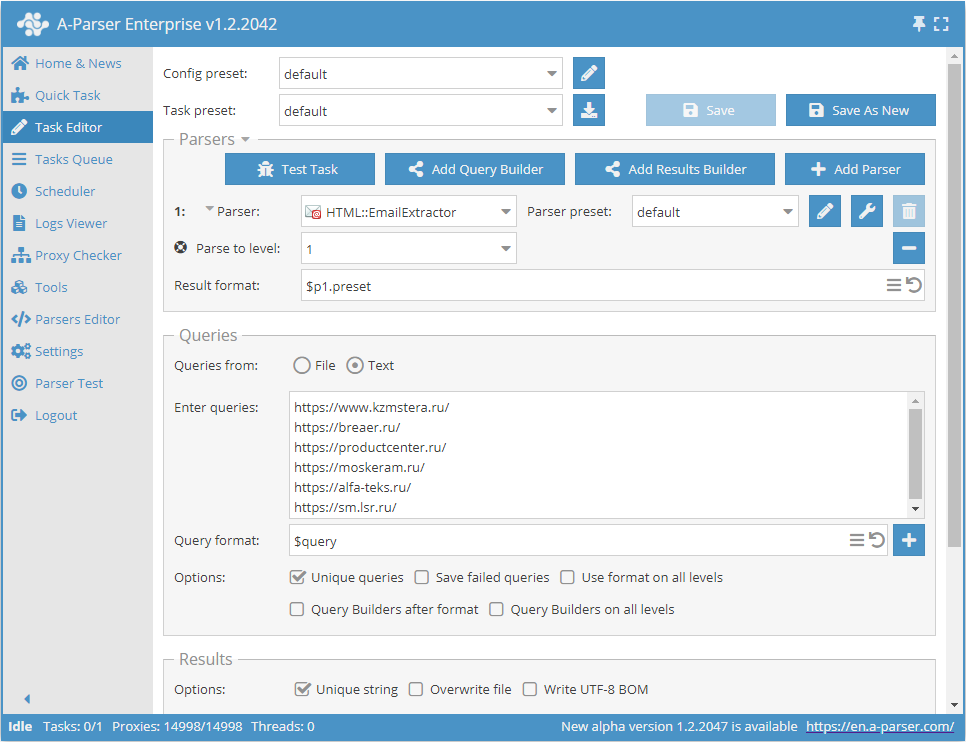
- Añadir la opción Parse to level, en la lista seleccionar el valor necesario (límite).
- En la sección Queries (Consultas), marcar la opción
Unique queries. - En la sección Results (Resultados), marcar la opción
Unique string. - Como consulta, indicar los enlaces a los sitios de los cuales se requiere extraer los correos, o en Queries from indicar
Filey cargar el archivo de consultas con la base de sitios.
Descargar ejemplo
Cómo importar un ejemplo a A-Parser
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
sugerencia
Extracción de correos por base de enlaces
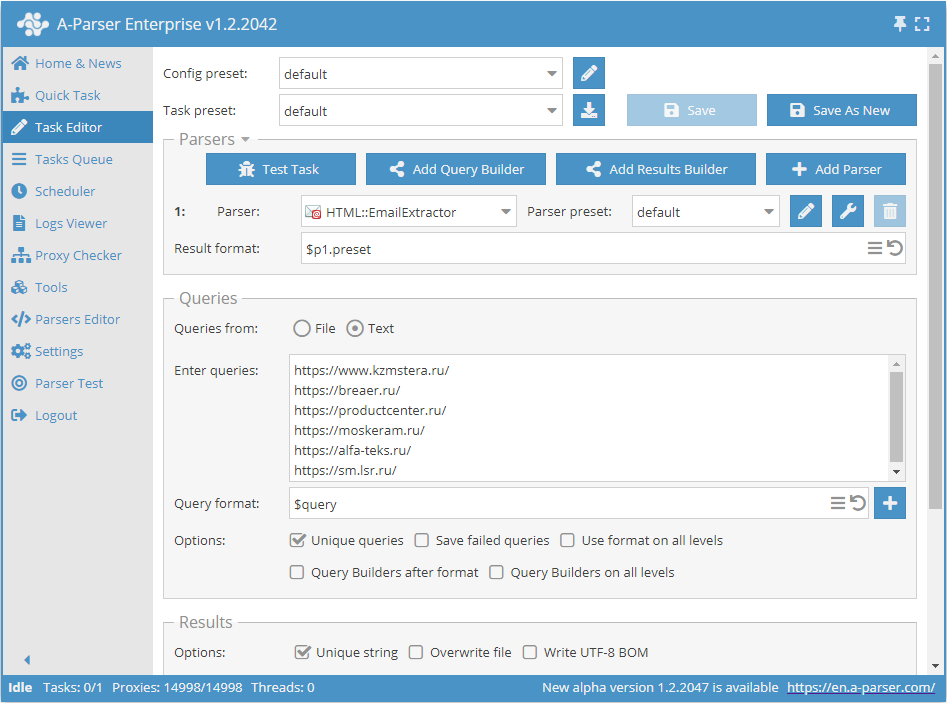
- En la sección Queries (Consultas), marcar la opción
Unique queries. - En la sección Results (Resultados), marcar la opción
Unique string. - Como consulta, indicar los enlaces de los cuales se requiere extraer los correos, o en Queries from indicar
Filey cargar el archivo de consultas con la base de enlaces.
Descargar ejemplo
Cómo importar un ejemplo a A-Parser
eJxtU01z0zAQ/S+aHmAmOPTAxbc00wwwaV3a9BRyEPE6COuLXSkpePLfWTmOHZfe
tG/fvv1UI4Kkmh4QCAKJfN0I375FLkqoZNRBTISXSIDJvRafV3fLPL81Uunbl4By
Gxwy5UzebCaCBfhJC4dGJqErf511qr3zSe5h5dhZKQ0DvGDrXhpIUaUMkLxZ1Qq9
e5+Fl6Qgy1IF5azUpwypriHrs1W/Y4qngMrumM8mKqAFOsNwgFYkgX/OFa7FVWsL
lolt/LdTjMgDRpgI4moX3DGUvaOSmtijAqDkERQ+lcR4I5ydab2EPeiB1srfRKVL
nuOs4qAvXeDblOI/jWPf4WWqPeABuYZepbVuirshqnRLt+PGreO2tTIqsE1zF23a
zUcGawDfj+0+0YxD6NN0yl12PhUPtmTmsLWZH6BRG6PNjMGts5XaFdwAqhLOzGhX
fI+FnTvjNaS+bNSat0LwOFzIjLo1JGMo8HXwvE0xuuTgnKavT6dSPSq+wE+pQMOT
vMzaSW6l1s+Py0uPGC6KjZ8heMqn08PhkNV/DaWlZhin3+3Z8wMl4Bjy6Mq4DVuw
4bXLOKpZwoxRqSv5IUBNY5hMpqkVEKnUADvHN8yDPG76P9v/7Obtn5s3R76RX/Rw
oqeBJjJjvBniAxD59fEfH7B6cg==
sugerencia
Datos recopilados
- Direcciones de correo electrónico
- Cantidad total de direcciones en la página
- Matriz con todas las páginas recopiladas (se utiliza con la opción Use Pages)
Capacidades
- Extracción de datos multipágina (navegación por páginas)
- Navegación por páginas internas del sitio hasta la profundidad especificada (opción Parse to level): permite recorrer todas las páginas del sitio recopilando enlaces internos y externos
- Determinación de follow links para los enlaces
- Límite de navegación por páginas (opción Follow links limit)
- Posibilidad de indicar que los subdominios se consideren como páginas internas del sitio
- Soporta compresión gzip/deflate/brotli
- Detección y conversión de codificaciones de sitios a UTF-8
- Omisión de la protección de CloudFlare
- Elección del motor (HTTP o Chrome)
- Soporte para toda la funcionalidad de
 HTML::LinkExtractor
HTML::LinkExtractor
Variantes de uso
- Extracción de direcciones de correo electrónico
- Obtención de la cantidad de direcciones de correo electrónico
Consultas
Como consultas, es necesario indicar enlaces a las páginas, por ejemplo:
https://a-parser.com/pages/support/
Variantes de salida de resultados
A-Parser admite un formateo flexible de resultados gracias al motor de plantillas integrado Template Toolkit, lo que le permite mostrar los resultados en forma libre, así como estructurada, por ejemplo, CSV o JSON.
Salida de la cantidad de direcciones de correo electrónico
Formato del resultado:
$mailcount
Ejemplo de resultado:
4
Configuraciones posibles
nota
| Nombre del parámetro | Valor por defecto | Descripción |
|---|---|---|
| Good status | All | Selección de qué respuesta del servidor se considerará exitosa. Si durante la extracción hay otra respuesta del servidor, la consulta se repetirá con otro proxy |
| Good code RegEx | Posibilidad de indicar una expresión regular para verificar el código de respuesta | |
| Ban Proxy Code RegEx | Posibilidad de banear el proxy temporalmente (Proxy ban time) basándose en el código de respuesta del servidor | |
| Method | GET | Método de consulta |
| POST body | Contenido para enviar al servidor al usar el método POST. Admite variables $query – URL de la consulta, $query.orig – consulta original y $pagenum - número de página al usar la opción Use Pages. | |
| Cookies | Posibilidad de indicar cookies para la consulta. | |
| User agent | _Se inserta automáticamente el user-agent de la versión actual de Chrome_ | Encabezado User-Agent al solicitar páginas |
| Additional headers | Posibilidad de indicar encabezados de consulta personalizados con soporte para las capacidades del motor de plantillas y el uso de variables del constructor de consultas | |
| Read only headers | ☐ | Leer solo encabezados. En algunos casos permite ahorrar tráfico si no es necesario procesar el contenido |
| Detect charset on content | ☐ | Reconocer la codificación basándose en el contenido de la página |
| Emulate browser headers | ☐ | Emular encabezados de navegador |
| Max redirects count | 0 | Cantidad máxima de redirecciones que seguirá el extractor |
| Follow common redirects | ☑ | Permite realizar redirecciones http <-> https y www.domain <-> domain dentro de un mismo dominio omitiendo el límite Max redirects count |
| Max cookies count | 16 | Número máximo de cookies a guardar |
| Engine | HTTP (Fast, JavaScript Disabled) | Permite elegir el motor HTTP (más rápido, sin JavaScript) o Chrome (más lento, JavaScript habilitado) |
| Chrome Headless | ☐ | Si la opción está activada, el navegador no se mostrará |
| Chrome DevTools | ☑ | Permite utilizar herramientas de depuración de Chromium |
| Chrome Log Proxy connections | ☑ | Si la opción está activada, se mostrará información sobre las conexiones de chrome en el registro |
| Chrome Wait Until | networkidle2 | Define cuándo se considera que la página ha cargado. Más información sobre los valores. |
| Use HTTP/2 transport | ☐ | Define si se debe usar HTTP/2 en lugar de HTTP/1.1. Por ejemplo, Google y Majestic banean de inmediato si se usa HTTP/1.1. |
| Don't verify TLS certs | ☐ | Desactivación de la validación de certificados TLS |
| Randomize TLS Fingerprint | ☐ | Esta opción permite omitir el baneo de sitios por huella TLS |
| Bypass CloudFlare | ☑ | Omisión automática de la verificación de CloudFlare |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Omisión de CF a través de Chrome |
| Bypass CloudFlare with Chrome Max Pages | 20 | Cantidad máx. de páginas al omitir CF a través de Chrome |
| Subdomains are internal | ☐ | Considerar subdominios como enlaces internos |
| Follow links | Internal only | Qué enlaces seguir |
| Follow links limit | 0 | Límite de Follow links, se aplica a cada dominio único |
| Skip comment blocks | ☐ | Omitir bloques de comentarios |
| Search Cloudflare protected e-mails | ☑ | Extraer correos protegidos por Cloudflare. |
| Skip non-HTML blocks | ☑ | No recopilar direcciones de correo en etiquetas (script, style, comment, etc.). |
| Skip meta tags | ☐ | No recopilar direcciones de correo en etiquetas meta |
| Search URL encoded e-mails | ☐ | Recopilación de correos codificados en URL |