HTML::EmailExtractor - ウェブサイトからのメールアドレススクレイピング
スクレイパーの概要
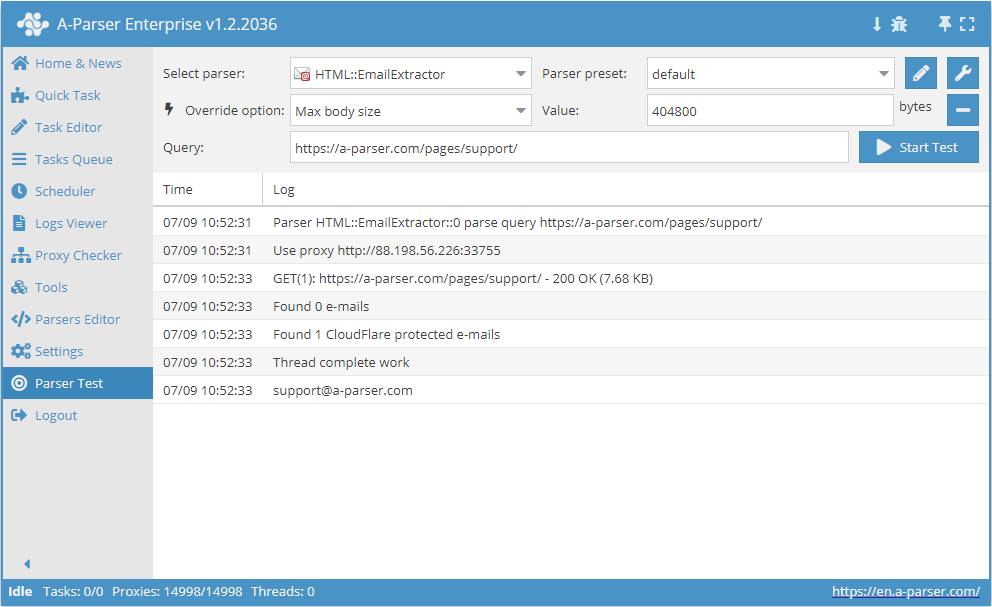
 HTML::EmailExtractor は指定されたページからメールアドレスを収集します。サイトの内部ページを指定した深度まで辿ることをサポートしており、サイトの全ページを巡回して内部および外部リンクを収集できます。このメールスクレイパーには、CloudFlare の保護を回避する機能が組み込まれており、スクリプトでデータが読み込まれるページのスクレイピング用にエンジンとして Chrome を選択することも可能です。最大で毎分 250 リクエストの速度に達することができ、これは 15,000 リンクに相当します。
HTML::EmailExtractor は指定されたページからメールアドレスを収集します。サイトの内部ページを指定した深度まで辿ることをサポートしており、サイトの全ページを巡回して内部および外部リンクを収集できます。このメールスクレイパーには、CloudFlare の保護を回避する機能が組み込まれており、スクリプトでデータが読み込まれるページのスクレイピング用にエンジンとして Chrome を選択することも可能です。最大で毎分 250 リクエストの速度に達することができ、これは 15,000 リンクに相当します。スクレイパーのユースケース
指定した深度までページを辿り、サイトからメールアドレスをスクレイピングする
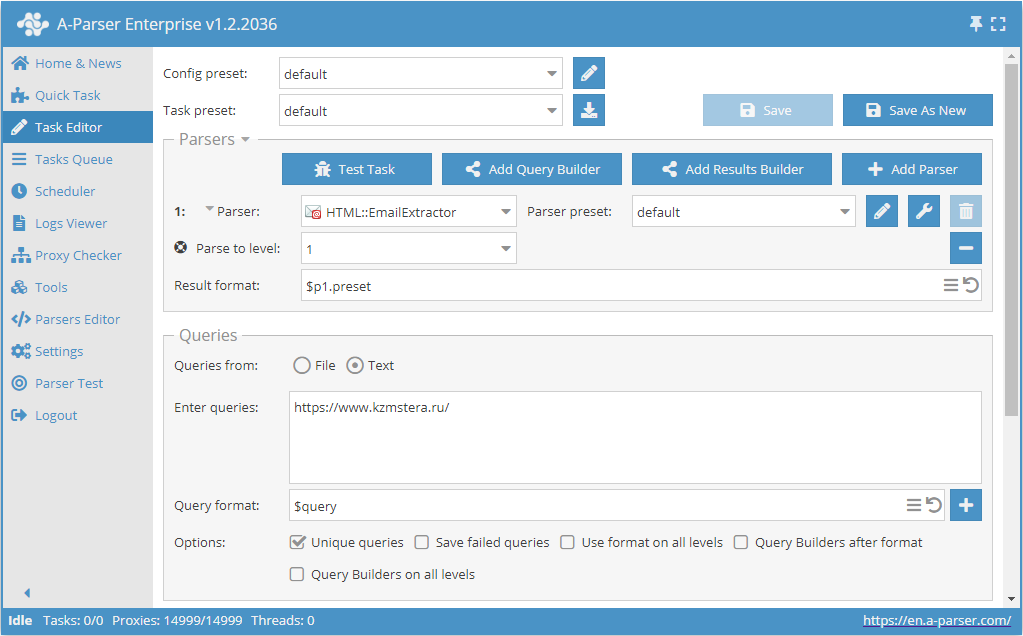
- Parse to level オプションを追加し、リストから必要な値(制限)を選択します。
- Queries (クエリ) セクションで、
Unique queriesオプションにチェックを入れます。 - Results (結果) セクションで、
Unique stringオプションにチェックを入れます。 - クエリとして、メールアドレスをスクレイピングしたいサイトのリンクを指定します。
サンプルをダウンロード
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
ヒント
以下も参照してください:
指定された制限の深さまで各サイトを巡回するサイトデータベースによるメールスクレイピング
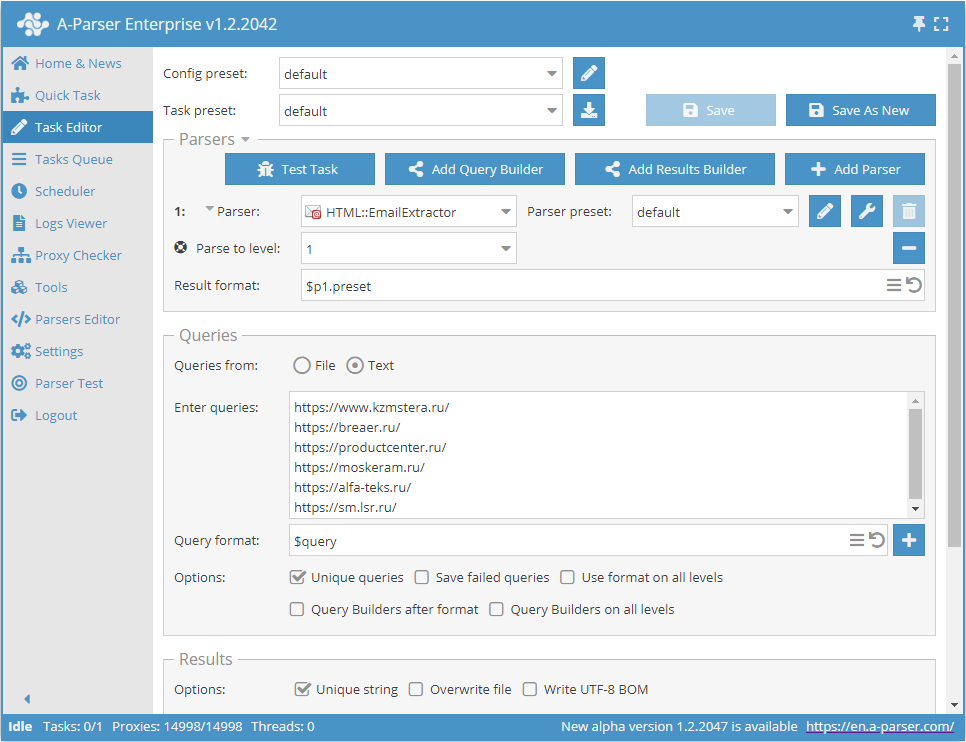
- Parse to level (指定レベルまでスクレイピング)オプションを追加し、リストから必要な値(制限)を選択します。
- Queries (クエリ)セクションで、
Unique queriesオプションにチェックを入れます。 - Results (結果)セクションで、
Unique stringオプションにチェックを入れます。 - クエリとしてメールをスクレイピングしたいサイトのリンクを指定するか、Queries from (クエリのソース)で
Fileを指定してサイトデータベースを含むクエリファイルをアップロードします。
サンプルをダウンロード
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
ヒント
リンクデータベースによるメールスクレイピング
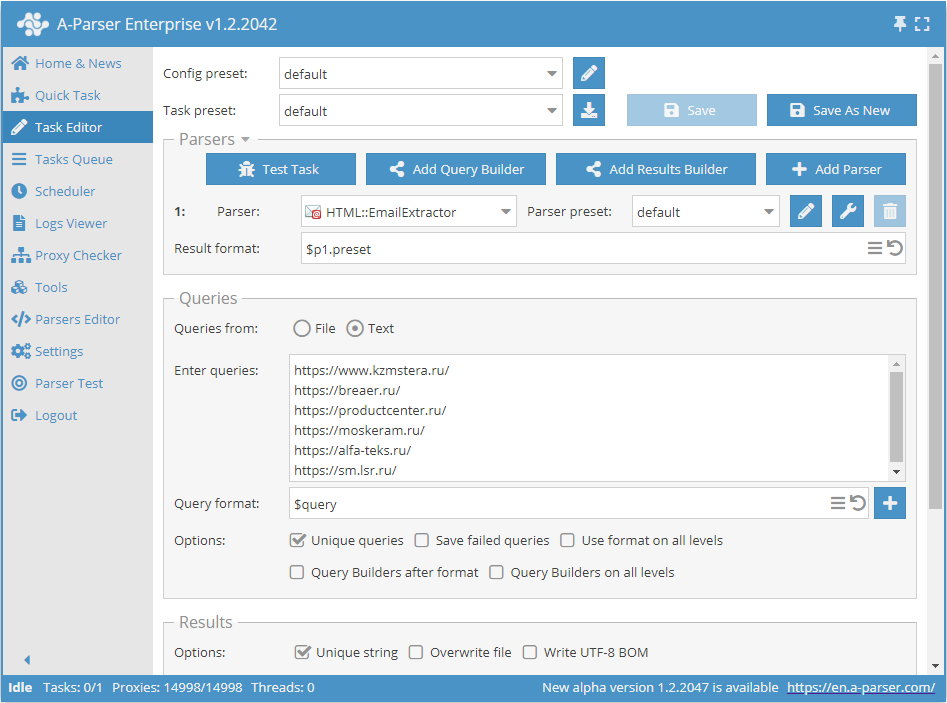
- Queries (クエリ)セクションで、
Unique queriesオプションにチェックを入れます。 - Results (結果)セクションで、
Unique stringオプションにチェックを入れます。 - クエリとしてメールをスクレイピングしたいリンクを指定するか、Queries from (クエリのソース)で
Fileを指定してリンクデータベースを含むクエリファイルをアップロードします。
サンプルをダウンロード
eJxtU01z0zAQ/S+aHmAmOPTAxbc00wwwaV3a9BRyEPE6COuLXSkpePLfWTmOHZfe
tG/fvv1UI4Kkmh4QCAKJfN0I375FLkqoZNRBTISXSIDJvRafV3fLPL81Uunbl4By
Gxwy5UzebCaCBfhJC4dGJqErf511qr3zSe5h5dhZKQ0DvGDrXhpIUaUMkLxZ1Qq9
e5+Fl6Qgy1IF5azUpwypriHrs1W/Y4qngMrumM8mKqAFOsNwgFYkgX/OFa7FVWsL
lolt/LdTjMgDRpgI4moX3DGUvaOSmtijAqDkERQ+lcR4I5ydab2EPeiB1srfRKVL
nuOs4qAvXeDblOI/jWPf4WWqPeABuYZepbVuirshqnRLt+PGreO2tTIqsE1zF23a
zUcGawDfj+0+0YxD6NN0yl12PhUPtmTmsLWZH6BRG6PNjMGts5XaFdwAqhLOzGhX
fI+FnTvjNaS+bNSat0LwOFzIjLo1JGMo8HXwvE0xuuTgnKavT6dSPSq+wE+pQMOT
vMzaSW6l1s+Py0uPGC6KjZ8heMqn08PhkNV/DaWlZhin3+3Z8wMl4Bjy6Mq4DVuw
4bXLOKpZwoxRqSv5IUBNY5hMpqkVEKnUADvHN8yDPG76P9v/7Obtn5s3R76RX/Rw
oqeBJjJjvBniAxD59fEfH7B6cg==
ヒント
以下も参照してください:
収集データ
- メールアドレス
- ページ上の総アドレス数
- 収集されたすべてのページの配列(Use Pagesオプション使用時に利用)
機能
- マルチページスクレイピング(ページ遷移)
- 指定された深さまでのサイト内ページ遷移(Parse to levelオプション) – サイトの全ページを巡回し、内部および外部リンクを収集可能
- リンクのfollow属性の判定
- ページ遷移制限(Follow links limitオプション)
- サブドメインをサイトの内部ページとして扱う設定が可能
- gzip/deflate/brotli 圧縮をサポート
- サイトの文字コードを判定し UTF-8 へ変換
- CloudFlareの保護を回避
- エンジンの選択(HTTPまたはChrome)
 HTML::LinkExtractor の全機能をサポート
HTML::LinkExtractor の全機能をサポート
ユースケース
- メールアドレスのスクレイピング
- メールアドレス数の出力
クエリ
クエリとして、以下のようなページへのリンクを指定する必要があります:
https://a-parser.com/pages/support/
結果の出力例
A-Parserは内蔵のテンプレートエンジン Template Toolkit により柔軟な結果フォーマットをサポートしており、任意の形式や、CSVやJSONなどの構造化された形式で結果を出力できます。
メールアドレス数の出力
結果フォーマット:
$mailcount
結果の例:
4
設定可能な項目
| パラメータ名 | デフォルト値 | 説明 |
|---|---|---|
| Good status | All | サーバーからのどのレスポンスを成功とみなすかを選択します。スクレイピング中に異なるレスポンスがあった場合、別のプロキシでリクエストが再試行されます |
| Good code RegEx | レスポンスコードをチェックするための正規表現を指定できます | |
| Ban Proxy Code RegEx | サーバーのレスポンスコードに基づいて、プロキシを一定時間禁止(Proxy ban time)できます | |
| Method | GET | リクエストメソッド |
| POST body | POSTメソッド使用時にサーバーへ送信するコンテンツ。変数 $query(リクエストURL)、$query.orig(元のクエリ)、および Use Pages オプション使用時の $pagenum(ページ番号)をサポートします。 | |
| Cookies | リクエスト用のCookieを指定できます。 | |
| User agent | _最新バージョンのChromeのUser-Agentが自動的に挿入されます_ | ページリクエスト時の User-Agent ヘッダー |
| Additional headers | テンプレートエンジンの機能やクエリコンストラクタの変数を使用して、任意の型のリクエストヘッダーを指定できます | |
| Read only headers | ☐ | ヘッダーのみを読み込みます。コンテンツを処理する必要がない場合、トラフィックを節約できます |
| Detect charset on content | ☐ | ページの内容に基づいて文字コードを認識します |
| Emulate browser headers | ☐ | ブラウザのヘッダーをエミュレートします |
| Max redirects count | 0 | スクレイパーが辿る最大リダイレクト数 |
| Follow common redirects | ☑ | 同一ドメイン内での http <-> https および www.domain <-> domain のリダイレクトを、Max redirects count の制限を無視して許可します |
| Max cookies count | 16 | 保存する最大Cookie数 |
| Engine | HTTP (Fast, JavaScript Disabled) | HTTPエンジン(高速、JavaScriptなし)または Chromeエンジン(低速、JavaScript有効)を選択できます |
| Chrome Headless | ☐ | 有効にすると、ブラウザは表示されません |
| Chrome DevTools | ☑ | Chromiumのデバッグツールを使用できるようにします |
| Chrome Log Proxy connections | ☑ | 有効にすると、Chromeの接続に関する情報がログに出力されます |
| Chrome Wait Until | networkidle2 | ページが読み込まれたとみなすタイミングを定義します。値の詳細はこちら。 |
| Use HTTP/2 transport | ☐ | HTTP/1.1の代わりにHTTP/2を使用するかどうかを決定します。例えば、GoogleやMajesticはHTTP/1.1を使用すると即座に禁止します。 |
| Don't verify TLS certs | ☐ | TLS証明書の検証を無効にします |
| Randomize TLS Fingerprint | ☐ | TLSフィンガープリントによるサイトの禁止を回避できます |
| Bypass CloudFlare | ☑ | CloudFlareのチェックを自動的に回避します |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Chrome経由でCFを回避します |
| Bypass CloudFlare with Chrome Max Pages | 20 | Chrome経由でCFを回避する際の最大ページ数 |
| Subdomains are internal | ☐ | サブドメインを内部リンクとして扱うかどうか |
| Follow links | Internal only | どのリンクを辿るか |
| Follow links limit | 0 | Follow links の制限(各ユニークドメインに適用) |
| Skip comment blocks | ☐ | コメントブロックをスキップするかどうか |
| Search Cloudflare protected e-mails | ☑ | Cloudflareで保護されたメールアドレスをスクレイピングするかどうか |
| Skip non-HTML blocks | ☑ | 特定のタグ(script, style, commentなど)内のメールアドレスを収集しない |
| Skip meta tags | ☐ | metaタグ内のメールアドレスを収集しない |
| Search URL encoded e-mails | ☐ | URLエンコードされたメールアドレスの収集 |