HTML::EmailExtractor - 从网站页面抓取电子邮件地址
爬虫工具概览
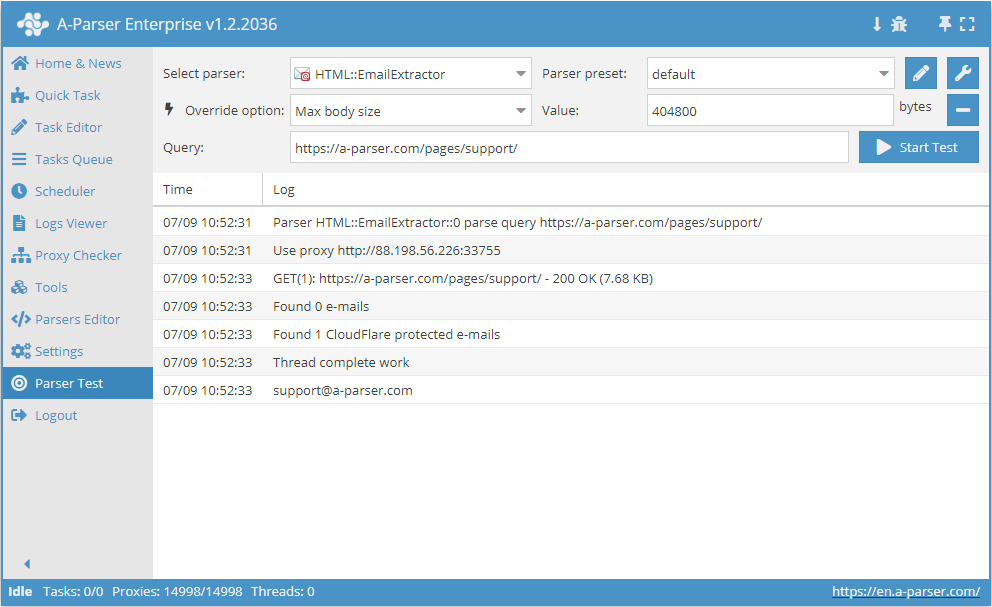
 HTML::EmailExtractor 从指定页面采集电子邮箱地址。支持深入跳转至网站内部页面至指定深度,从而遍历网站所有页面并采集内部和外部链接。Email 爬虫工具内置了绕过 CloudFlare 防护的手段,并可选择 Chrome 作为引擎,用于抓取由脚本加载数据的页面。其速度最高可达每分钟 250 次请求 —— 即每小时 15 000 个链接。
HTML::EmailExtractor 从指定页面采集电子邮箱地址。支持深入跳转至网站内部页面至指定深度,从而遍历网站所有页面并采集内部和外部链接。Email 爬虫工具内置了绕过 CloudFlare 防护的手段,并可选择 Chrome 作为引擎,用于抓取由脚本加载数据的页面。其速度最高可达每分钟 250 次请求 —— 即每小时 15 000 个链接。爬虫工具应用案例
从网站抓取邮箱并深入页面至指定限制
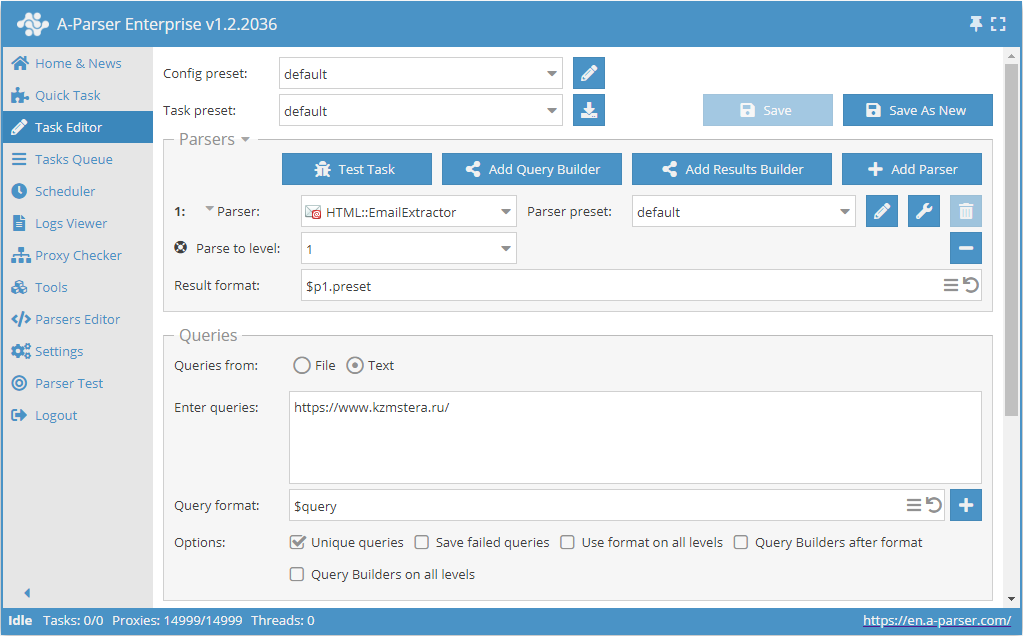
- 添加选项 Parse to level (爬取至层级),在列表中选择所需数值(限制)。
- 在 Queries (查询) 环节勾选
Unique queries选项。 - 在 Results (结果) 环节勾选
Unique string选项。 - 在查询框中输入需要抓取邮箱的网站链接。
下载示例
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
根据网站列表抓取邮箱并深入每个网站至指定限制
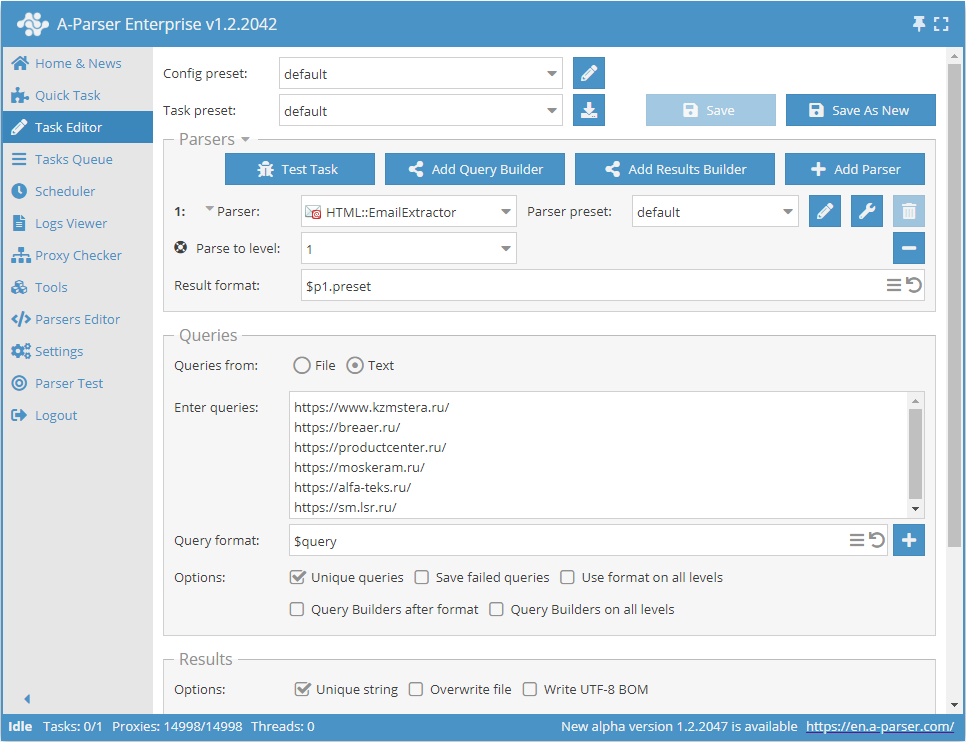
- 添加选项 Parse to level (爬取至层级),在列表中选择所需数值(限制)。
- 在 Queries (查询) 环节勾选
Unique queries选项。 - 在 Results (结果) 环节勾选
Unique string选项。 - 在查询框中输入需要抓取邮箱的网站链接,或在 Queries from (查询来源) 中选择
File并上传包含网站列表的查询文件。
下载示例
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
根据链接列表抓取邮箱
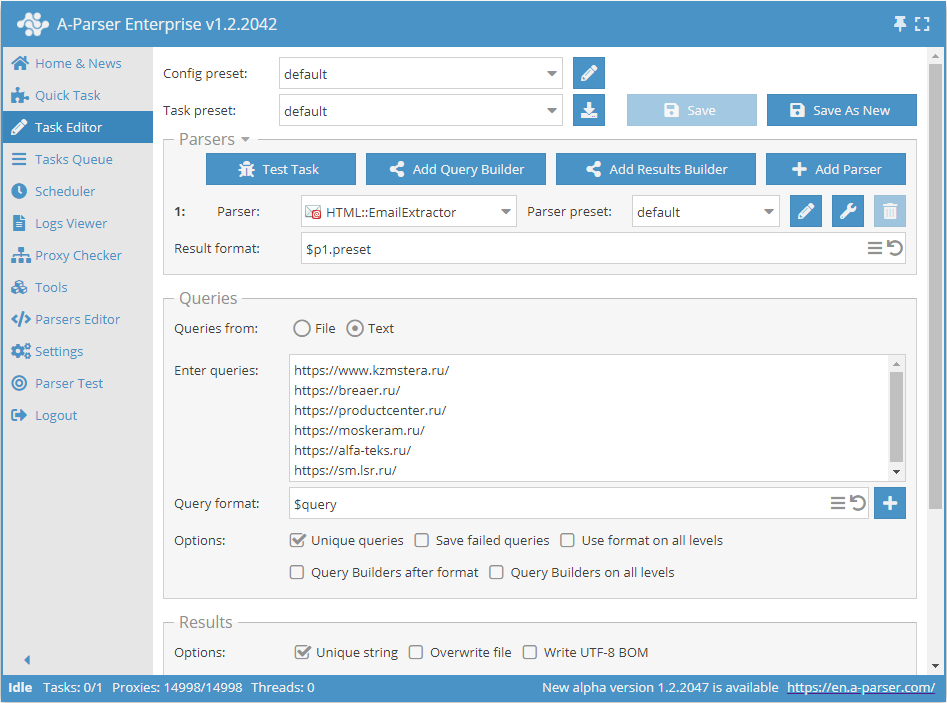
- 在 Queries (查询) 环节勾选
Unique queries选项。 - 在 Results (结果) 环节勾选
Unique string选项。 - 在查询框中输入需要抓取邮箱的链接,或在 Queries from (查询来源) 中选择
File并上传包含链接列表的查询文件。
下载示例
eJxtU01z0zAQ/S+aHmAmOPTAxbc00wwwaV3a9BRyEPE6COuLXSkpePLfWTmOHZfe
tG/fvv1UI4Kkmh4QCAKJfN0I375FLkqoZNRBTISXSIDJvRafV3fLPL81Uunbl4By
Gxwy5UzebCaCBfhJC4dGJqErf511qr3zSe5h5dhZKQ0DvGDrXhpIUaUMkLxZ1Qq9
e5+Fl6Qgy1IF5azUpwypriHrs1W/Y4qngMrumM8mKqAFOsNwgFYkgX/OFa7FVWsL
lolt/LdTjMgDRpgI4moX3DGUvaOSmtijAqDkERQ+lcR4I5ydab2EPeiB1srfRKVL
nuOs4qAvXeDblOI/jWPf4WWqPeABuYZepbVuirshqnRLt+PGreO2tTIqsE1zF23a
zUcGawDfj+0+0YxD6NN0yl12PhUPtmTmsLWZH6BRG6PNjMGts5XaFdwAqhLOzGhX
fI+FnTvjNaS+bNSat0LwOFzIjLo1JGMo8HXwvE0xuuTgnKavT6dSPSq+wE+pQMOT
vMzaSW6l1s+Py0uPGC6KjZ8heMqn08PhkNV/DaWlZhin3+3Z8wMl4Bjy6Mq4DVuw
4bXLOKpZwoxRqSv5IUBNY5hMpqkVEKnUADvHN8yDPG76P9v/7Obtn5s3R76RX/Rw
oqeBJjJjvBniAxD59fEfH7B6cg==
采集的数据
- 电子邮箱地址
- 页面上的邮箱总数
- 包含所有已采集页面的数组(在使用 Use Pages 选项时使用)
功能
- 多页数据抓取(翻页跳转)
- 深入跳转至网站内部页面至指定深度(Parse to level 选项)——允许遍历网站所有页面,采集内部和外部链接
- 识别链接的 follow 属性
- 页面跳转限制(Follow links limit 选项)
- 可选择将子域名视为网站内部页面
- 支持 gzip/deflate/brotli 压缩
- 自动识别并将网站编码转换为 UTF-8
- 绕过 CloudFlare 防护
- 可选引擎(HTTP 或 Chrome)
- 支持
 HTML::LinkExtractor 的所有功能
HTML::LinkExtractor 的所有功能
应用场景
- 抓取 email 地址
- 统计 email 地址数量
查询
查询中需要指定页面链接,例如:
https://a-parser.com/pages/support/
结果输出示例
得益于内置的 Template Toolkit 模板引擎,A-Parser 支持灵活的结果格式化,允许以任意形式输出结果,包括 CSV 或 JSON 等结构化格式
输出 email 地址数量
结果格式:
$mailcount
结果示例:
4
可选设置
| 参数名称 | 默认值 | 描述 |
|---|---|---|
| Good status | All | 选择哪些服务器响应被视为成功。如果抓取时收到其他响应,将使用另一个代理重试请求 |
| Good code RegEx | 可指定用于检查响应代码的正则表达式 | |
| Ban Proxy Code RegEx | 可根据服务器响应代码临时封禁代理 (Proxy ban time) | |
| Method | GET | 请求方法 |
| POST body | 使用 POST 方法时发送到服务器的内容。支持变量:$query —— 请求 URL,$query.orig —— 原始查询,以及在使用 Use Pages 选项时的 $pagenum —— 页码。 | |
| Cookies | 可为请求指定 cookies。 | |
| User agent | _自动填入当前版本 Chrome 的 User-Agent_ | 请求页面时的 User-Agent 请求头 |
| Additional headers | 可指定自定义请求头,支持模板引擎功能并可使用查询构造器中的变量 | |
| Read only headers | ☐ | 仅读取响应头。在无需处理内容的情况下可节省流量 |
| Detect charset on content | ☐ | 根据页面内容识别编码 |
| Emulate browser headers | ☐ | 模拟浏览器请求头 |
| Max redirects count | 0 | 爬虫工具执行重定向的最大次数 |
| Follow common redirects | ☑ | 允许在同一域名内进行 http <-> https 和 www.domain <-> domain 的重定向,不受 Max redirects count 限制 |
| Max cookies count | 16 | 保存 cookies 的最大数量 |
| Engine | HTTP (Fast, JavaScript Disabled) | 可选择 HTTP 引擎(速度快,无 JavaScript)或 Chrome 引擎(速度慢,启用 JavaScript) |
| Chrome Headless | ☐ | 如果启用此选项,将不显示浏览器界面 |
| Chrome DevTools | ☑ | 允许使用 Chromium 调试工具 |
| Chrome Log Proxy connections | ☑ | 如果启用此选项,日志中将输出 chrome 连接信息 |
| Chrome Wait Until | networkidle2 | 定义页面何时被视为加载完成。了解更多关于取值的信息。 |
| Use HTTP/2 transport | ☐ | 定义是否使用 HTTP/2 代替 HTTP/1.1。例如,Google 和 Majestic 如果检测到使用 HTTP/1.1 会立即封禁。 |
| Don't verify TLS certs | ☐ | 禁用 TLS 证书验证 |
| Randomize TLS Fingerprint | ☐ | 此选项允许通过 TLS 指纹绕过网站封禁 |
| Bypass CloudFlare | ☑ | 自动绕过 CloudFlare 检查 |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | 通过 Chrome 绕过 CF |
| Bypass CloudFlare with Chrome Max Pages | 20 | 通过 Chrome 绕过 CF 时的最大页面数 |
| Subdomains are internal | ☐ | 是否将子域名视为内部链接 |
| Follow links | Internal only | 追踪哪些链接 |
| Follow links limit | 0 | Follow links 限制,应用于每个唯一域名 |
| Skip comment blocks | ☐ | 是否跳过注释块 |
| Search Cloudflare protected e-mails | ☑ | 是否抓取 Cloudflare 保护的邮箱。 |
| Skip non-HTML blocks | ☑ | 不采集特定标签(script, style, comment 等)中的邮箱地址。 |
| Skip meta tags | ☐ | 不采集 meta 标签中的邮箱地址 |
| Search URL encoded e-mails | ☐ | 采集 URL 编码的邮箱 |