HTML::EmailExtractor - Extração de dados de endereços de e-mail de páginas de sites
Visão geral do scraper
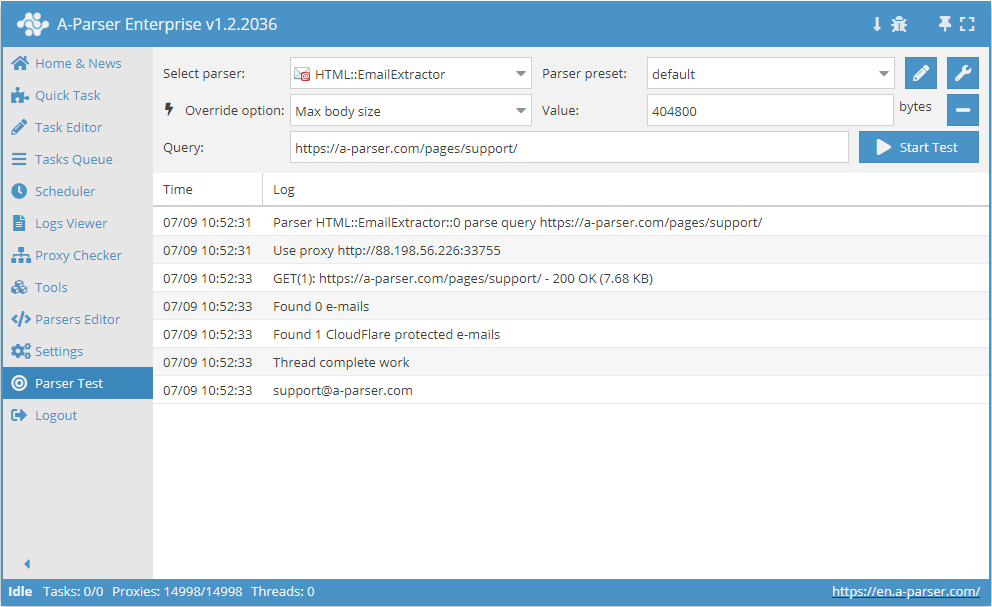
 HTML::EmailExtractor coleta endereços de e-mail das páginas especificadas. Suporta navegação por páginas internas do site até a profundidade especificada, o que permite percorrer todas as páginas do site, coletando links internos e externos. O scraper de e-mail possui meios integrados para contornar a proteção CloudFlare e também a possibilidade de escolher Chrome como motor para extração de e-mails de páginas cujos dados são carregados por scripts. Capaz de atingir velocidades de até 250 consultas por minuto – isso representa 15 000 links por hora.
HTML::EmailExtractor coleta endereços de e-mail das páginas especificadas. Suporta navegação por páginas internas do site até a profundidade especificada, o que permite percorrer todas as páginas do site, coletando links internos e externos. O scraper de e-mail possui meios integrados para contornar a proteção CloudFlare e também a possibilidade de escolher Chrome como motor para extração de e-mails de páginas cujos dados são carregados por scripts. Capaz de atingir velocidades de até 250 consultas por minuto – isso representa 15 000 links por hora.Casos de uso do scraper
Extração de e-mails de um site com navegação profunda até o limite especificado
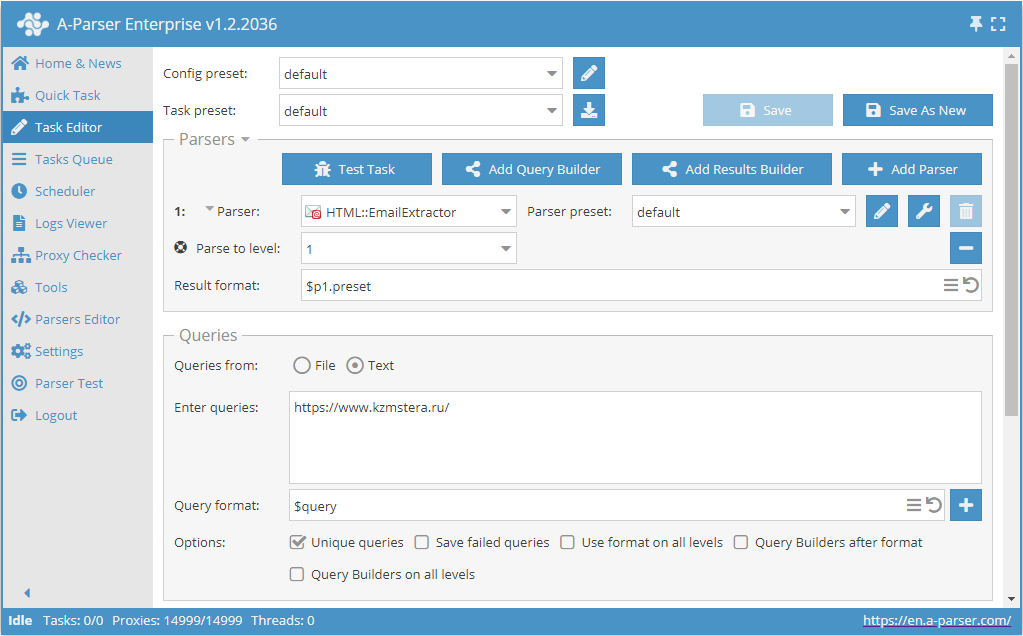
- Adicionar a opção Parse to level, selecionar o valor necessário na lista (limite).
- Na seção Queries (Consultas), marcar a opção
Unique queries. - Na seção Results (Resultados), marcar a opção
Unique string. - Como consulta, indicar o link do site do qual deseja extrair os e-mails.
Baixar exemplo
Como importar um exemplo para o A-Parser
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
Extração de e-mails por base de sites com navegação em cada site até a profundidade do limite especificado
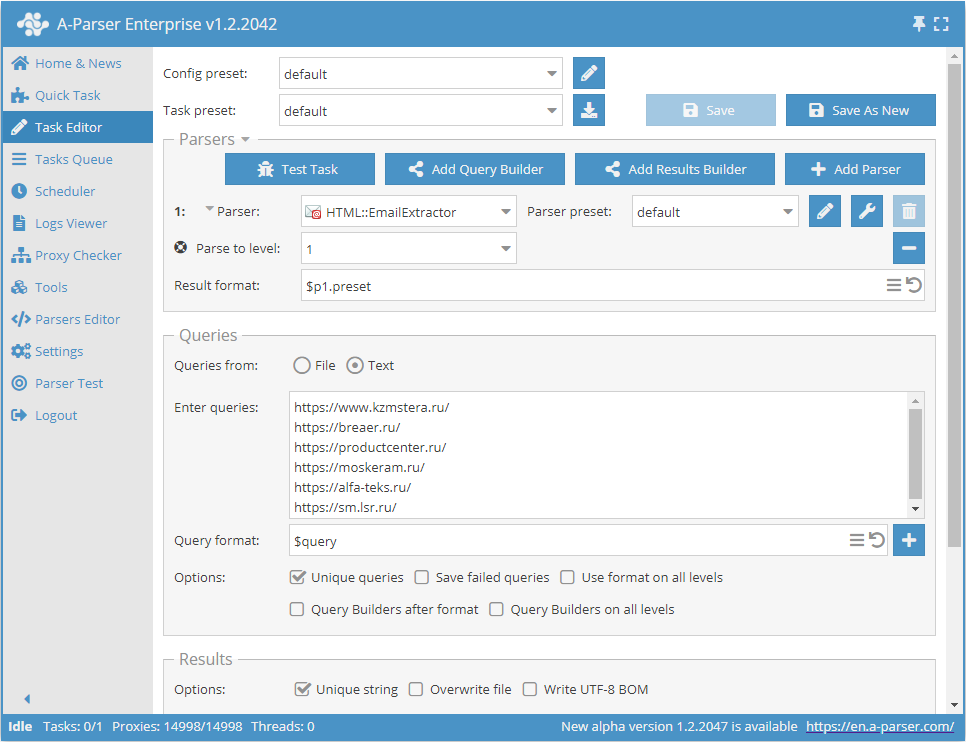
- Adicionar a opção Parse to level, selecionar o valor necessário (limite) na lista.
- Na seção Queries (Consultas), marcar a opção
Unique queries. - Na seção Results (Resultados), marcar a opção
Unique string. - Como consulta, indicar os links dos sites dos quais é necessário extrair os e-mails, ou em Queries from (Consultas de) indicar
Filee carregar o arquivo de consultas com a base de sites.
Baixar exemplo
Como importar um exemplo para o A-Parser
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
dica
Extração de e-mails por base de links
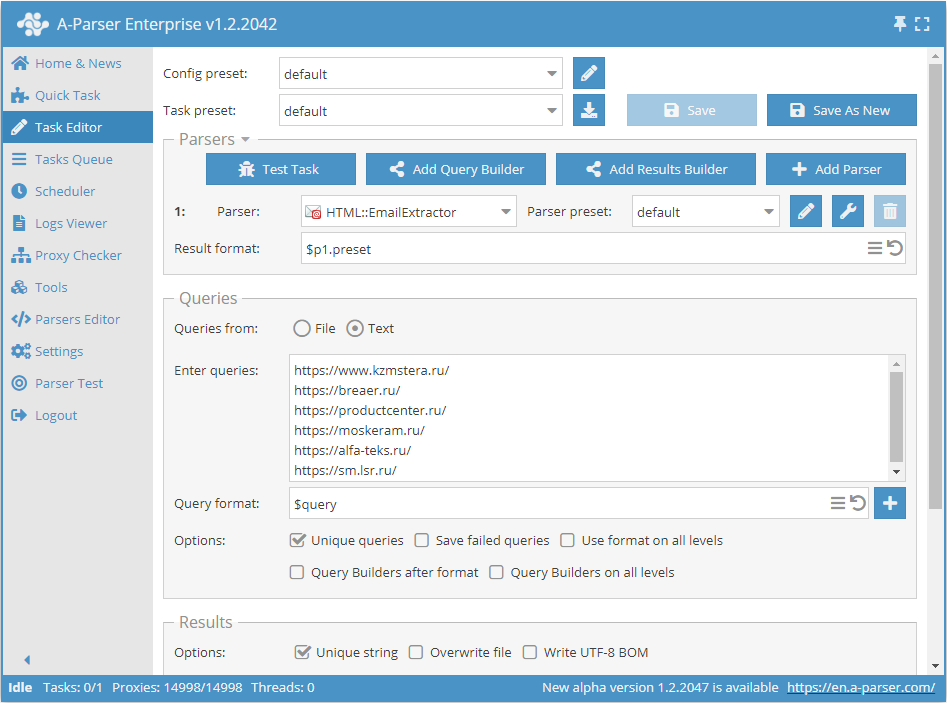
- Na seção Queries (Consultas), marcar a opção
Unique queries. - Na seção Results (Resultados), marcar a opção
Unique string. - Como consulta, indicar os links dos quais é necessário extrair os e-mails, ou em Queries from (Consultas de) indicar
Filee carregar o arquivo de consultas com a base de links.
Baixar exemplo
Como importar um exemplo para o A-Parser
eJxtU01z0zAQ/S+aHmAmOPTAxbc00wwwaV3a9BRyEPE6COuLXSkpePLfWTmOHZfe
tG/fvv1UI4Kkmh4QCAKJfN0I375FLkqoZNRBTISXSIDJvRafV3fLPL81Uunbl4By
Gxwy5UzebCaCBfhJC4dGJqErf511qr3zSe5h5dhZKQ0DvGDrXhpIUaUMkLxZ1Qq9
e5+Fl6Qgy1IF5azUpwypriHrs1W/Y4qngMrumM8mKqAFOsNwgFYkgX/OFa7FVWsL
lolt/LdTjMgDRpgI4moX3DGUvaOSmtijAqDkERQ+lcR4I5ydab2EPeiB1srfRKVL
nuOs4qAvXeDblOI/jWPf4WWqPeABuYZepbVuirshqnRLt+PGreO2tTIqsE1zF23a
zUcGawDfj+0+0YxD6NN0yl12PhUPtmTmsLWZH6BRG6PNjMGts5XaFdwAqhLOzGhX
fI+FnTvjNaS+bNSat0LwOFzIjLo1JGMo8HXwvE0xuuTgnKavT6dSPSq+wE+pQMOT
vMzaSW6l1s+Py0uPGC6KjZ8heMqn08PhkNV/DaWlZhin3+3Z8wMl4Bjy6Mq4DVuw
4bXLOKpZwoxRqSv5IUBNY5hMpqkVEKnUADvHN8yDPG76P9v/7Obtn5s3R76RX/Rw
oqeBJjJjvBniAxD59fEfH7B6cg==
Dados coletados
- Endereços de e-mail
- Número total de endereços na página
- Array com todas as páginas coletadas (usado quando a opção Use Pages está ativa)
Recursos
- Extração de dados multipáginas (navegação por páginas)
- Navegação pelas páginas internas do site até a profundidade especificada (opção Parse to level) – permite percorrer todas as páginas do site, coletando links internos e externos
- Identificação de links follow para os links
- Limite de navegação por páginas (opção Follow links limit)
- Possibilidade de especificar para considerar subdomínios como páginas internas do site
- Suporta compressão gzip/deflate/brotli
- Identificação e conversão de codificações de sites para UTF-8
- Contorno de proteção CloudFlare
- Escolha do motor (HTTP ou Chrome)
- Suporte a todas as funcionalidades do
 HTML::LinkExtractor
HTML::LinkExtractor
Casos de uso
- Extração de endereços de e-mail
- Exibição da quantidade de endereços de e-mail
Consultas
Como consultas, é necessário indicar links para as páginas, por exemplo:
https://a-parser.com/pages/support/
Exemplos de saída de resultados
O A-Parser suporta formatação flexível de resultados graças ao motor de modelos integrado Template Toolkit, o que permite exibir resultados em formato livre, bem como em formato estruturado, como CSV ou JSON
Exibição da quantidade de endereços de e-mail
Formato do resultado:
$mailcount
Exemplo de resultado:
4
Configurações possíveis
nota
| Nome do parâmetro | Valor padrão | Descrição |
|---|---|---|
| Good status | All | Escolha de qual resposta do servidor será considerada bem-sucedida. Se houver outra resposta do servidor durante a extração, a consulta será repetida com outro proxy |
| Good code RegEx | Possibilidade de especificar uma expressão regular para verificar o código de resposta | |
| Ban Proxy Code RegEx | Possibilidade de banir o proxy temporariamente (Proxy ban time) com base no código de resposta do servidor | |
| Method | GET | Método de consulta |
| POST body | Conteúdo para enviar ao servidor ao usar o método POST. Suporta as variáveis $query – URL da consulta, $query.orig – consulta original e $pagenum - número da página ao usar a opção Use Pages. | |
| Cookies | Possibilidade de especificar cookies para a consulta. | |
| User agent | _O user-agent da versão atual do Chrome é inserido automaticamente_ | Cabeçalho User-Agent ao solicitar páginas |
| Additional headers | Possibilidade de especificar cabeçalhos de consulta arbitrários com suporte aos recursos do motor de modelos e uso de variáveis do construtor de consultas | |
| Read only headers | ☐ | Ler apenas cabeçalhos. Em alguns casos, permite economizar tráfego se não houver necessidade de processar o conteúdo |
| Detect charset on content | ☐ | Reconhecer a codificação com base no conteúdo da página |
| Emulate browser headers | ☐ | Emular cabeçalhos de navegador |
| Max redirects count | 0 | Número máximo de redirecionamentos que o scraper seguirá |
| Follow common redirects | ☑ | Permite fazer redirecionamentos http <-> https e www.domain <-> domain dentro do mesmo domínio, ignorando o limite Max redirects count |
| Max cookies count | 16 | Número máximo de cookies para salvar |
| Engine | HTTP (Fast, JavaScript Disabled) | Permite escolher o motor HTTP (mais rápido, sem JavaScript) ou Chrome (mais lento, JavaScript ativado) |
| Chrome Headless | ☐ | Se a opção estiver ativada, o navegador não será exibido |
| Chrome DevTools | ☑ | Permite usar ferramentas de depuração do Chromium |
| Chrome Log Proxy connections | ☑ | Se a opção estiver ativada, informações sobre as conexões do chrome serão exibidas no log |
| Chrome Wait Until | networkidle2 | Define quando a página é considerada carregada. Saiba mais sobre os valores. |
| Use HTTP/2 transport | ☐ | Define se deve usar HTTP/2 em vez de HTTP/1.1. Por exemplo, Google e Majestic banem imediatamente se usar HTTP/1.1. |
| Don't verify TLS certs | ☐ | Desativar a validação de certificados TLS |
| Randomize TLS Fingerprint | ☐ | Esta opção permite contornar o banimento de sites por impressão digital TLS |
| Bypass CloudFlare | ☑ | Contorno automático da verificação do CloudFlare |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Contorno do CF via Chrome |
| Bypass CloudFlare with Chrome Max Pages | 20 | Número máx. de páginas ao contornar o CF via Chrome |
| Subdomains are internal | ☐ | Considerar subdomínios como links internos |
| Follow links | Internal only | Quais links seguir |
| Follow links limit | 0 | Limite de Follow links, aplicado a cada domínio único |
| Skip comment blocks | ☐ | Pular blocos de comentários |
| Search Cloudflare protected e-mails | ☑ | Extrair e-mails protegidos pelo Cloudflare. |
| Skip non-HTML blocks | ☑ | Não coletar endereços de e-mail em tags (script, style, comment, etc.). |
| Skip meta tags | ☐ | Não coletar endereços de e-mail em meta tags |
| Search URL encoded e-mails | ☐ | Coleta de e-mails codificados em URL |