HTML::EmailExtractor - Scrapowanie adresów email ze stron internetowych
Przegląd scrapera
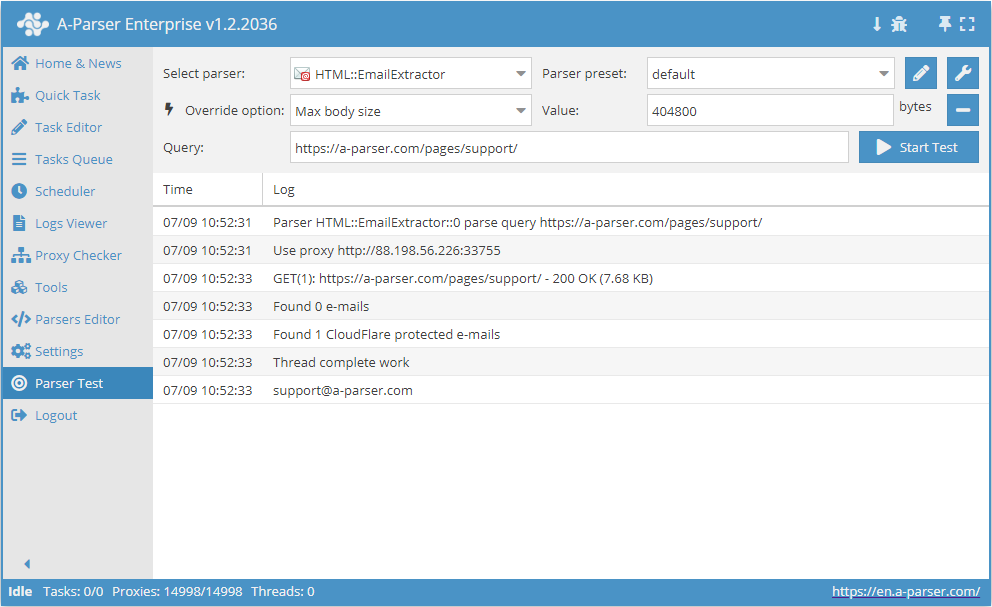
 HTML::EmailExtractor zbiera adresy e-mail z określonych stron. Obsługuje przechodzenie po wewnętrznych stronach witryny do określonej głębokości, co pozwala przejść przez wszystkie strony witryny, zbierając linki wewnętrzne i zewnętrzne. Scraper e-maili posiada wbudowane narzędzia do omijania ochrony CloudFlare a także możliwość wyboru Chrome jako silnika do scrapowania e-maili ze stron, na których dane są ładowane przez skrypty. Jest w stanie osiągnąć prędkość do 250 zapytań na minutę – co daje 15 000 linków na godzinę.
HTML::EmailExtractor zbiera adresy e-mail z określonych stron. Obsługuje przechodzenie po wewnętrznych stronach witryny do określonej głębokości, co pozwala przejść przez wszystkie strony witryny, zbierając linki wewnętrzne i zewnętrzne. Scraper e-maili posiada wbudowane narzędzia do omijania ochrony CloudFlare a także możliwość wyboru Chrome jako silnika do scrapowania e-maili ze stron, na których dane są ładowane przez skrypty. Jest w stanie osiągnąć prędkość do 250 zapytań na minutę – co daje 15 000 linków na godzinę.Przypadki użycia scrapera
Scrapowanie e-maili z witryny z przechodzeniem w głąb stron do określonego limitu
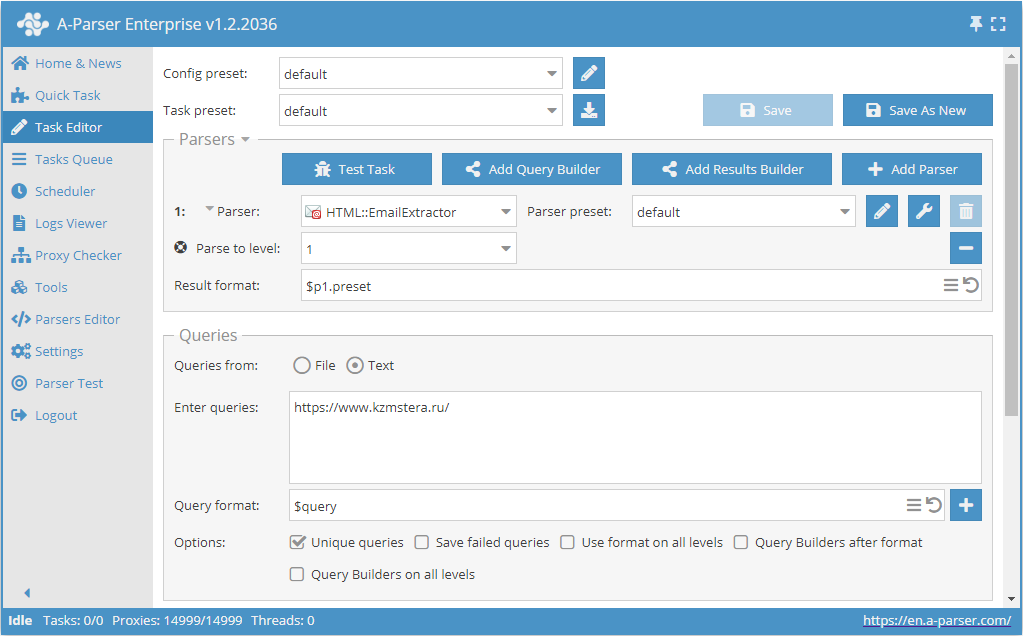
- Dodaj opcję Parse to level, z listy wybierz wymaganą wartość (limit).
- W sekcji Queries (Zapytania) zaznacz opcję
Unique queries. - W sekcji Results (Wyniki) zaznacz opcję
Unique string. - Jako zapytanie podaj link do strony, z której chcesz scrapować e-maile.
Pobierz przykład
Jak zaimportować przykład do A-Parser
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
wskazówka
Scrapowanie e-maili z bazy witryn z przechodzeniem każdej witryny w głąb do określonego limitu
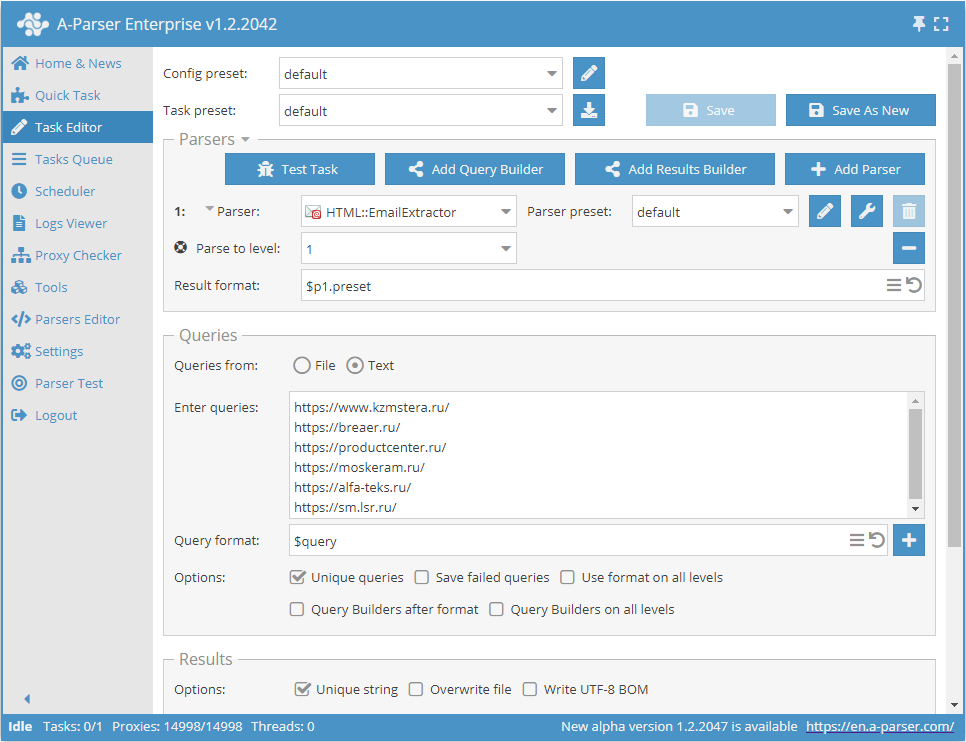
- Dodaj opcję Parse to level, z listy wybierz wymaganą wartość (limit).
- W sekcji Queries (Zapytania) zaznacz opcję
Unique queries. - W sekcji Results (Wyniki) zaznacz opcję
Unique string. - Jako zapytanie podaj linki do stron, z których chcesz scrapować e-maile, lub w Queries from (Zapytania z) wybierz
Filei wgraj plik zapytań z bazą witryn.
Pobierz przykład
Jak zaimportować przykład do A-Parser
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
wskazówka
Scrapowanie e-maili z bazy linków
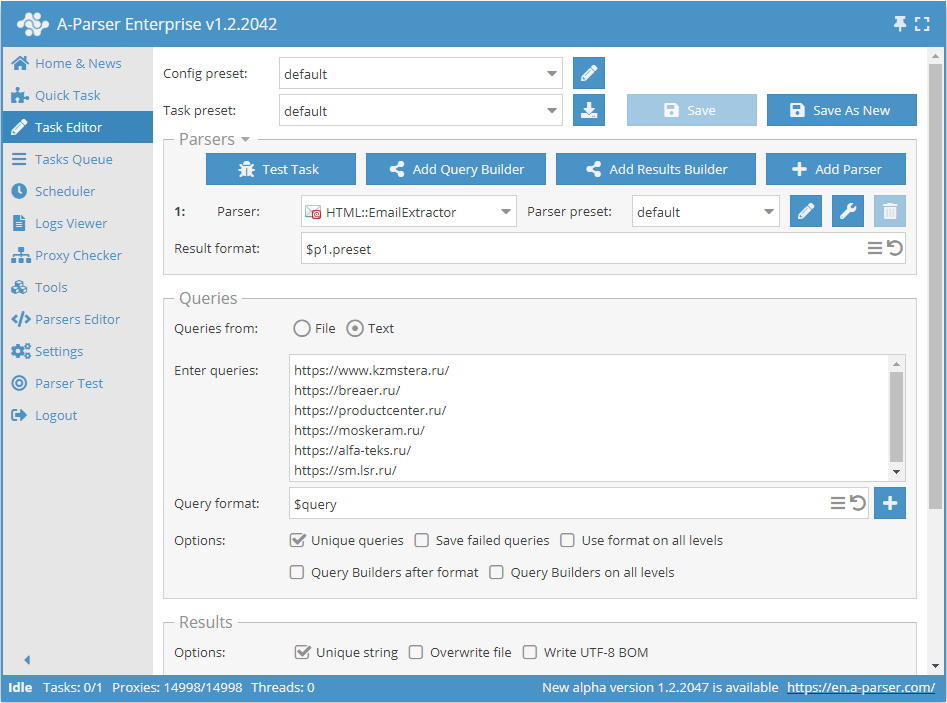
- W sekcji Queries (Zapytania) zaznacz opcję
Unique queries. - W sekcji Results (Wyniki) zaznacz opcję
Unique string. - Jako zapytanie podaj linki, z których chcesz scrapować e-maile, lub w Queries from (Zapytania z) wybierz
Filei wgraj plik zapytań z bazą linków.
Pobierz przykład
Jak zaimportować przykład do A-Parser
eJxtU01z0zAQ/S+aHmAmOPTAxbc00wwwaV3a9BRyEPE6COuLXSkpePLfWTmOHZfe
tG/fvv1UI4Kkmh4QCAKJfN0I375FLkqoZNRBTISXSIDJvRafV3fLPL81Uunbl4By
Gxwy5UzebCaCBfhJC4dGJqErf511qr3zSe5h5dhZKQ0DvGDrXhpIUaUMkLxZ1Qq9
e5+Fl6Qgy1IF5azUpwypriHrs1W/Y4qngMrumM8mKqAFOsNwgFYkgX/OFa7FVWsL
lolt/LdTjMgDRpgI4moX3DGUvaOSmtijAqDkERQ+lcR4I5ydab2EPeiB1srfRKVL
nuOs4qAvXeDblOI/jWPf4WWqPeABuYZepbVuirshqnRLt+PGreO2tTIqsE1zF23a
zUcGawDfj+0+0YxD6NN0yl12PhUPtmTmsLWZH6BRG6PNjMGts5XaFdwAqhLOzGhX
fI+FnTvjNaS+bNSat0LwOFzIjLo1JGMo8HXwvE0xuuTgnKavT6dSPSq+wE+pQMOT
vMzaSW6l1s+Py0uPGC6KjZ8heMqn08PhkNV/DaWlZhin3+3Z8wMl4Bjy6Mq4DVuw
4bXLOKpZwoxRqSv5IUBNY5hMpqkVEKnUADvHN8yDPG76P9v/7Obtn5s3R76RX/Rw
oqeBJjJjvBniAxD59fEfH7B6cg==
wskazówka
Gromadzone dane
- Adresy e-mail
- Całkowita liczba adresów na stronie
- Tablica ze wszystkimi zebranymi stronami (używana przy włączonej opcji Use Pages)
Funkcje
- Wielostronicowe scrapowanie (przechodzenie po stronach)
- Przechodzenie po wewnętrznych stronach witryny do określonej głębokości (opcja Parse to level) – pozwala przejść przez wszystkie strony witryny, zbierając linki wewnętrzne i zewnętrzne
- Wykrywanie linków follow dla odnośników
- Limit przechodzenia po stronach (opcja Follow links limit)
- Możliwość traktowania subdomen jako wewnętrznych stron witryny
- Obsługa kompresji gzip/deflate/brotli
- Wykrywanie i konwersja kodowania stron na UTF-8
- Omijanie zabezpieczeń CloudFlare
- Wybór silnika (HTTP lub Chrome)
- Obsługa pełnej funkcjonalności
 HTML::LinkExtractor
HTML::LinkExtractor
Warianty użycia
- Scrapowanie adresów e-mail
- Wyświetlanie liczby adresów e-mail
Zapytania
Jako zapytania należy podawać linki do stron, na przykład:
https://a-parser.com/pages/support/
Warianty wyświetlania wyników
A-Parser obsługuje elastyczne formatowanie wyników dzięki wbudowanemu silnikowi szablonów Template Toolkit, co pozwala na wyprowadzanie wyników w dowolnej formie, a także w formacie strukturalnym, takim jak CSV lub JSON
Wyświetlanie liczby adresów e-mail
Format wyniku:
$mailcount
Przykład wyniku:
4
Możliwe ustawienia
notatka
| Nazwa parametru | Wartość domyślna | Opis |
|---|---|---|
| Good status | All | Wybór, która odpowiedź z serwera zostanie uznana za sukces. Jeśli podczas scrapowania wystąpi inna odpowiedź, zapytanie zostanie powtórzone z innym proxy |
| Good code RegEx | Możliwość podania wyrażenia regularnego do sprawdzenia kodu odpowiedzi | |
| Ban Proxy Code RegEx | Możliwość czasowego blokowania proxy (Proxy ban time) na podstawie kodu odpowiedzi serwera | |
| Method | GET | Metoda zapytania |
| POST body | Treść do przesłania na serwer przy użyciu metody POST. Obsługuje zmienne $query – URL zapytania, $query.orig – oryginalne zapytanie oraz $pagenum - numer strony przy użyciu opcji Use Pages. | |
| Cookies | Możliwość określenia plików cookie dla zapytania. | |
| User agent | _Automatycznie podstawiany jest user-agent aktualnej wersji Chrome_ | Nagłówek User-Agent podczas zapytania o strony |
| Additional headers | Możliwość określenia dowolnych nagłówków zapytania z obsługą silnika szablonów i zmiennych z konstruktora zapytań | |
| Read only headers | ☐ | Czytaj tylko nagłówki. W niektórych przypadkach pozwala oszczędzać transfer, jeśli nie ma potrzeby przetwarzania treści |
| Detect charset on content | ☐ | Rozpoznawanie kodowania na podstawie zawartości strony |
| Emulate browser headers | ☐ | Emulacja nagłówków przeglądarki |
| Max redirects count | 0 | Maksymalna liczba przekierowań, przez które przejdzie scraper |
| Follow common redirects | ☑ | Pozwala na przekierowania http <-> https oraz www.domain <-> domain w obrębie jednej domeny z pominięciem limitu Max redirects count |
| Max cookies count | 16 | Maksymalna liczba plików cookie do zapisania |
| Engine | HTTP (Fast, JavaScript Disabled) | Pozwala wybrać silnik HTTP (szybszy, bez JavaScript) lub Chrome (wolniejszy, JavaScript włączony) |
| Chrome Headless | ☐ | Jeśli opcja jest włączona, przeglądarka nie będzie wyświetlana |
| Chrome DevTools | ☑ | Pozwala na korzystanie z narzędzi programistycznych Chromium |
| Chrome Log Proxy connections | ☑ | Jeśli opcja jest włączona, w logu będą wyświetlane informacje o połączeniach chrome |
| Chrome Wait Until | networkidle2 | Określa, kiedy strona jest uznawana za załadowaną. Więcej o wartościach. |
| Use HTTP/2 transport | ☐ | Określa, czy używać HTTP/2 zamiast HTTP/1.1. Na przykład Google i Majestic natychmiast blokują przy użyciu HTTP/1.1. |
| Don't verify TLS certs | ☐ | Wyłączenie walidacji certyfikatów TLS |
| Randomize TLS Fingerprint | ☐ | Ta opcja pozwala omijać blokady stron na podstawie odcisku TLS |
| Bypass CloudFlare | ☑ | Automatyczne omijanie weryfikacji CloudFlare |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Omijanie CF przez Chrome |
| Bypass CloudFlare with Chrome Max Pages | 20 | Maks. liczba stron przy omijaniu CF przez Chrome |
| Subdomains are internal | ☐ | Czy traktować subdomeny jako linki wewnętrzne |
| Follow links | Internal only | Po jakich linkach przechodzić |
| Follow links limit | 0 | Limit Follow links, stosowany do każdej unikalnej domeny |
| Skip comment blocks | ☐ | Czy pomijać bloki komentarzy |
| Search Cloudflare protected e-mails | ☑ | Czy scrapować e-maile chronione przez Cloudflare. |
| Skip non-HTML blocks | ☑ | Nie zbieraj adresów e-mail w tagach (script, style, comment itp.). |
| Skip meta tags | ☐ | Nie zbieraj adresów e-mail w meta tagach |
| Search URL encoded e-mails | ☐ | Zbieranie e-maili zakodowanych w URL |