HTML::EmailExtractor - Scraping di indirizzi email dalle pagine web
Panoramica dello scraper
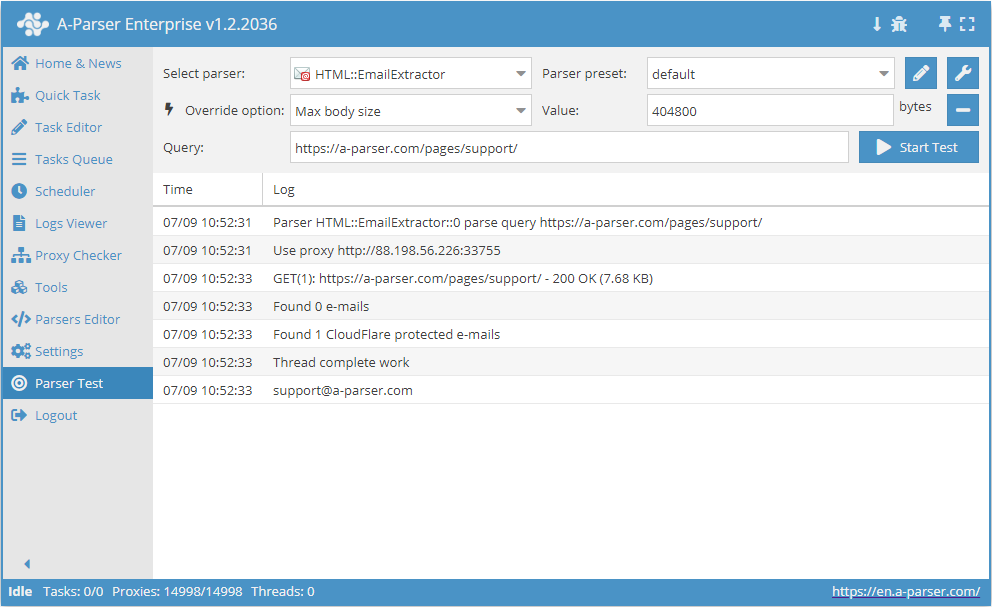
 HTML::EmailExtractor raccoglie indirizzi email dalle pagine specificate. Supporta la navigazione tra le pagine interne del sito fino alla profondità specificata, consentendo di scansionare tutte le pagine del sito raccogliendo link interni ed esterni. Lo scraper di email dispone di strumenti integrati per il bypass della protezione CloudFlare e anche la possibilità di scegliere Chrome come motore per lo scraping di email da pagine i cui dati vengono caricati tramite script. È in grado di raggiungere una velocità fino a 250 richieste al minuto – ovvero 15 000 link all'ora.
HTML::EmailExtractor raccoglie indirizzi email dalle pagine specificate. Supporta la navigazione tra le pagine interne del sito fino alla profondità specificata, consentendo di scansionare tutte le pagine del sito raccogliendo link interni ed esterni. Lo scraper di email dispone di strumenti integrati per il bypass della protezione CloudFlare e anche la possibilità di scegliere Chrome come motore per lo scraping di email da pagine i cui dati vengono caricati tramite script. È in grado di raggiungere una velocità fino a 250 richieste al minuto – ovvero 15 000 link all'ora.Casi d'uso dello scraper
Scraping di email da un sito con navigazione in profondità fino al limite specificato
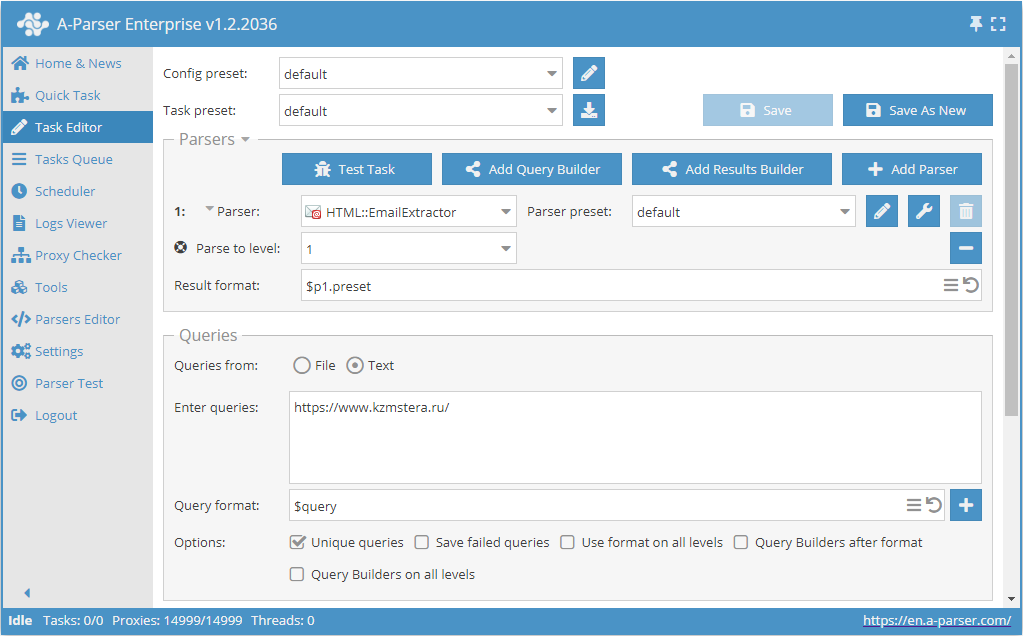
- Aggiungere l'opzione Parse to level, selezionare il valore desiderato (limite) dall'elenco.
- Nella sezione Queries (Query), spuntare l'opzione
Unique queries. - Nella sezione Results (Risultati), spuntare l'opzione
Unique string. - Come query, indicare il link al sito da cui si desidera estrarre le email.
Scarica esempio
Come importare un esempio in A-Parser
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
suggerimento
Scraping di email da un database di siti con navigazione di ogni sito in profondità fino al limite specificato
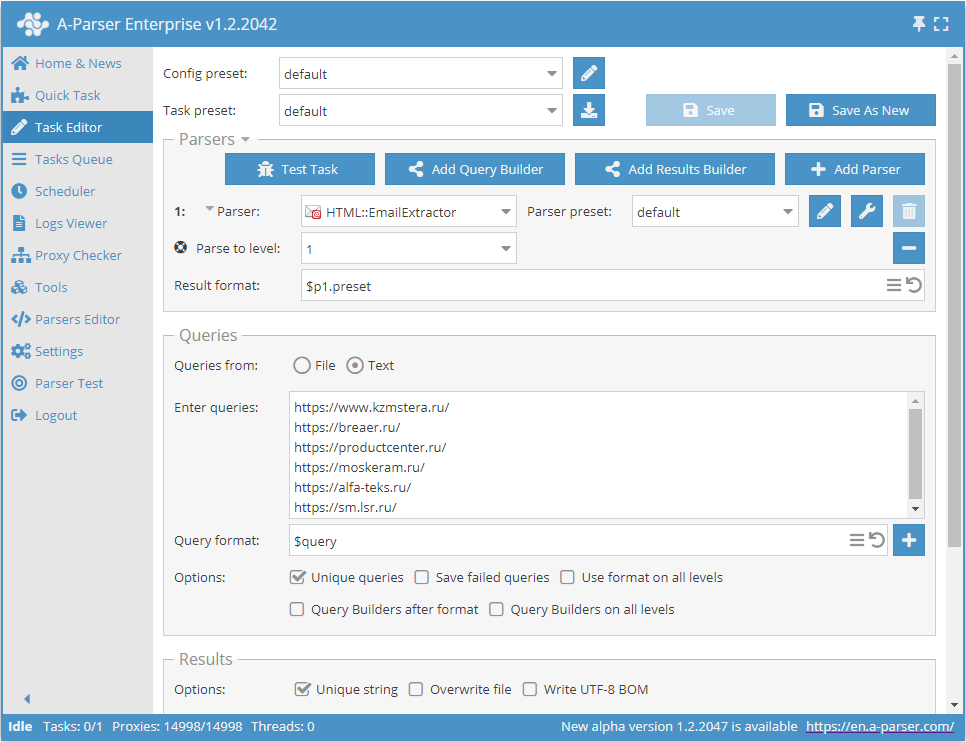
- Aggiungere l'opzione Parse to level, selezionare il valore desiderato (limite) dall'elenco.
- Nella sezione Queries (Query), spuntare l'opzione
Unique queries. - Nella sezione Results (Risultati), spuntare l'opzione
Unique string. - Come query, indicare i link ai siti da cui si desidera estrarre le email, oppure in Queries from (Query da) selezionare
Filee caricare il file delle query con il database dei siti.
Scarica esempio
Come importare un esempio in A-Parser
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
suggerimento
Scraping di email da un database di link
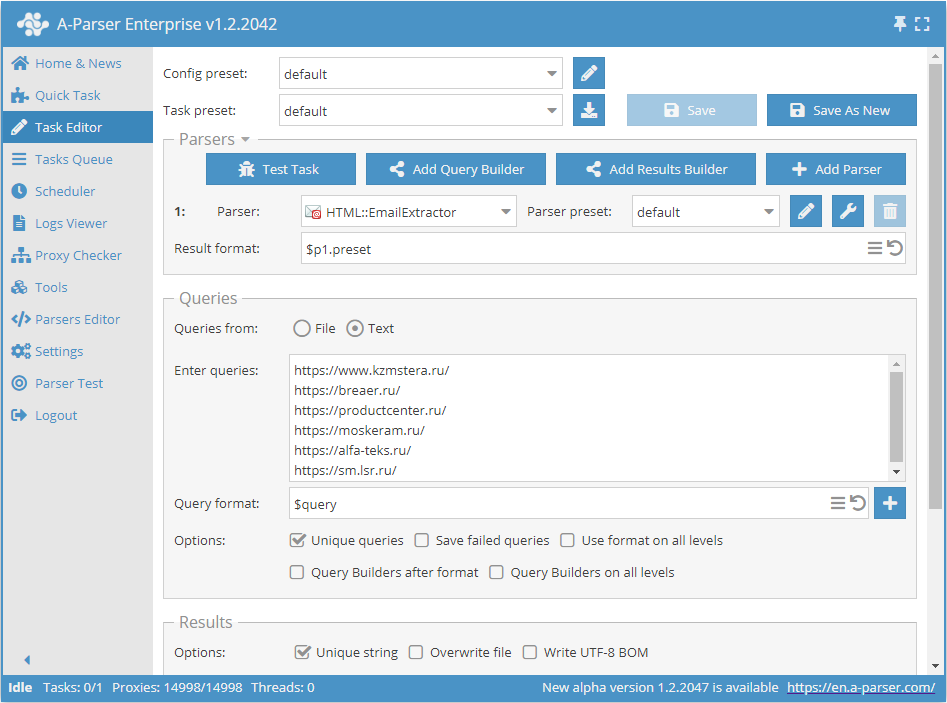
- Nella sezione Queries (Query), spuntare l'opzione
Unique queries. - Nella sezione Results (Risultati), spuntare l'opzione
Unique string. - Come query, indicare i link da cui si desidera estrarre le email, oppure in Queries from (Query da) selezionare
Filee caricare il file delle query con il database dei link.
Scarica esempio
Come importare un esempio in A-Parser
eJxtU01z0zAQ/S+aHmAmOPTAxbc00wwwaV3a9BRyEPE6COuLXSkpePLfWTmOHZfe
tG/fvv1UI4Kkmh4QCAKJfN0I375FLkqoZNRBTISXSIDJvRafV3fLPL81Uunbl4By
Gxwy5UzebCaCBfhJC4dGJqErf511qr3zSe5h5dhZKQ0DvGDrXhpIUaUMkLxZ1Qq9
e5+Fl6Qgy1IF5azUpwypriHrs1W/Y4qngMrumM8mKqAFOsNwgFYkgX/OFa7FVWsL
lolt/LdTjMgDRpgI4moX3DGUvaOSmtijAqDkERQ+lcR4I5ydab2EPeiB1srfRKVL
nuOs4qAvXeDblOI/jWPf4WWqPeABuYZepbVuirshqnRLt+PGreO2tTIqsE1zF23a
zUcGawDfj+0+0YxD6NN0yl12PhUPtmTmsLWZH6BRG6PNjMGts5XaFdwAqhLOzGhX
fI+FnTvjNaS+bNSat0LwOFzIjLo1JGMo8HXwvE0xuuTgnKavT6dSPSq+wE+pQMOT
vMzaSW6l1s+Py0uPGC6KjZ8heMqn08PhkNV/DaWlZhin3+3Z8wMl4Bjy6Mq4DVuw
4bXLOKpZwoxRqSv5IUBNY5hMpqkVEKnUADvHN8yDPG76P9v/7Obtn5s3R76RX/Rw
oqeBJjJjvBniAxD59fEfH7B6cg==
suggerimento
Dati raccolti
- Indirizzi email
- Numero totale di indirizzi sulla pagina
- Array con tutte le pagine raccolte (utilizzato quando l'opzione Use Pages è attiva)
Funzionalità
- Scraping multipagina (navigazione tra le pagine)
- Navigazione tra le pagine interne del sito fino alla profondità specificata (opzione Parse to level) – consente di scansionare tutte le pagine del sito, raccogliendo link interni ed esterni
- Identificazione dei follow links per i collegamenti
- Limite di navigazione tra le pagine (opzione Follow links limit)
- Possibilità di considerare i sottodomini come pagine interne del sito
- Supporta la compressione gzip/deflate/brotli
- Identificazione e conversione della codifica dei siti in UTF-8
- Bypass della protezione CloudFlare
- Scelta del motore (HTTP o Chrome)
- Supporto di tutte le funzionalità di
 HTML::LinkExtractor
HTML::LinkExtractor
Varianti di utilizzo
- Scraping di indirizzi email
- Estrazione del numero di indirizzi email
Query
Come query è necessario indicare i link alle pagine, ad esempio:
https://a-parser.com/pages/support/
Esempi di output dei risultati
A-Parser supporta una formattazione flessibile dei risultati grazie al motore di modelli integrato Template Toolkit, che gli consente di produrre risultati in forma libera o strutturata, come CSV o JSON
Output del numero di indirizzi email
Formato del risultato:
$mailcount
Esempio di risultato:
4
Impostazioni possibili
nota
| Nome parametro | Valore predefinito | Descrizione |
|---|---|---|
| Good status | All | Scelta di quale risposta dal server sarà considerata corretta. Se durante lo scraping si riceve una risposta diversa, la query verrà ripetuta con un altro proxy |
| Good code RegEx | Possibilità di specificare un'espressione regolare per verificare il codice di risposta | |
| Ban Proxy Code RegEx | Possibilità di bannare i proxy temporaneamente (Proxy ban time) in base al codice di risposta del server | |
| Method | GET | Metodo della richiesta |
| POST body | Contenuto da inviare al server quando si utilizza il metodo POST. Supporta le variabili $query – URL della query, $query.orig – query originale e $pagenum - numero della pagina quando si utilizza l'opzione Use Pages. | |
| Cookies | Possibilità di specificare i cookie per la richiesta. | |
| User agent | _Viene inserito automaticamente lo user-agent dell'ultima versione di Chrome_ | Intestazione User-Agent durante la richiesta delle pagine |
| Additional headers | Possibilità di specificare intestazioni di richiesta personalizzate con supporto per le funzionalità del motore di modelli e l'uso di variabili dal costruttore di query | |
| Read only headers | ☐ | Leggi solo le intestazioni. In alcuni casi permette di risparmiare traffico se non è necessario elaborare il contenuto |
| Detect charset on content | ☐ | Riconoscimento della codifica basato sul contenuto della pagina |
| Emulate browser headers | ☐ | Emula le intestazioni del browser |
| Max redirects count | 0 | Numero massimo di reindirizzamenti che lo scraper seguirà |
| Follow common redirects | ☑ | Consente di effettuare reindirizzamenti http <-> https e www.domain <-> domain all'interno dello stesso dominio ignorando il limite Max redirects count |
| Max cookies count | 16 | Numero massimo di cookie da salvare |
| Engine | HTTP (Fast, JavaScript Disabled) | Consente di scegliere il motore HTTP (più veloce, senza JavaScript) o Chrome (più lento, JavaScript abilitato) |
| Chrome Headless | ☐ | Se l'opzione è attiva, il browser non verrà visualizzato |
| Chrome DevTools | ☑ | Consente di utilizzare gli strumenti di debug di Chromium |
| Chrome Log Proxy connections | ☑ | Se l'opzione è attiva, nel log verranno visualizzate le informazioni sulle connessioni chrome |
| Chrome Wait Until | networkidle2 | Definisce quando la pagina è considerata caricata. Maggiori dettagli sui valori. |
| Use HTTP/2 transport | ☐ | Definisce se utilizzare HTTP/2 invece di HTTP/1.1. Ad esempio, Google e Majestic bannano immediatamente se si utilizza HTTP/1.1. |
| Don't verify TLS certs | ☐ | Disabilitazione della validazione dei certificati TLS |
| Randomize TLS Fingerprint | ☐ | Questa opzione consente di bypassare il ban dei siti tramite l'impronta TLS |
| Bypass CloudFlare | ☑ | Bypass automatico della verifica CloudFlare |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Bypass di CF tramite Chrome |
| Bypass CloudFlare with Chrome Max Pages | 20 | Numero massimo di pagine durante il bypass di CF tramite Chrome |
| Subdomains are internal | ☐ | Considerare i sottodomini come link interni |
| Follow links | Internal only | Quali link seguire |
| Follow links limit | 0 | Limite Follow links, applicato a ogni dominio unico |
| Skip comment blocks | ☐ | Saltare i blocchi di commenti |
| Search Cloudflare protected e-mails | ☑ | Eseguire lo scraping delle email protette da Cloudflare. |
| Skip non-HTML blocks | ☑ | Non raccogliere indirizzi email nei tag (script, style, comment, ecc.). |
| Skip meta tags | ☐ | Non raccogliere indirizzi email nei meta tag |
| Search URL encoded e-mails | ☐ | Raccolta di email codificate in URL |