HTML::LinkExtractor - Scraper de links externos e internos de um site específico
Visão geral do scraper
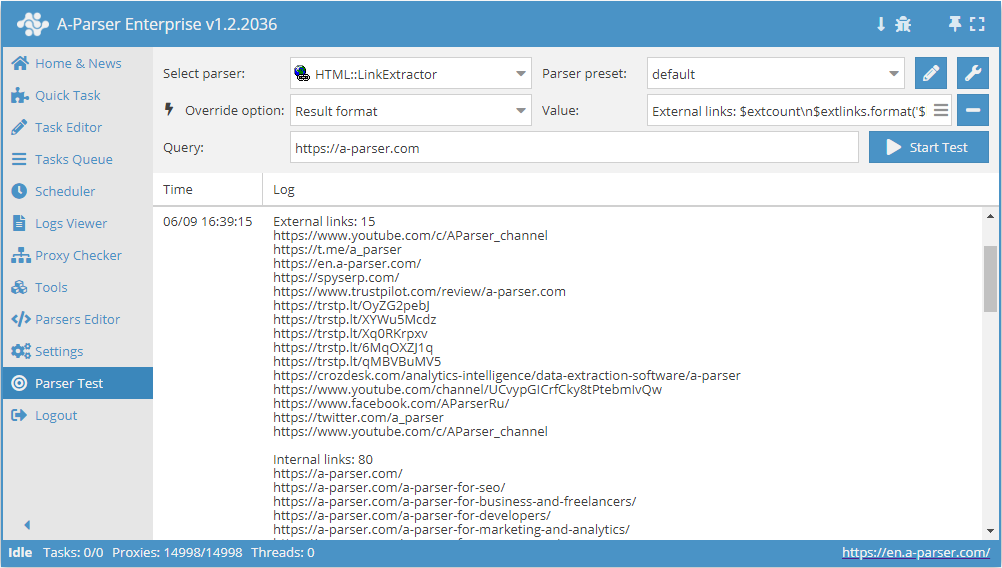
 HTML::LinkExtractor – scraper de links externos e internos de um site especificado. Suporta extração multipáginas e navegação por páginas internas do site até a profundidade especificada, o que permite percorrer todas as páginas do site, coletando links internos e externos. Possui ferramentas integradas para contornar a proteção CloudFlare e também a possibilidade de escolher Chrome como motor para extração de e-mails de páginas cujos dados são carregados por scripts. Capaz de atingir velocidades de até 2000 requisições por minuto – isso representa 120 000 links por hora.
HTML::LinkExtractor – scraper de links externos e internos de um site especificado. Suporta extração multipáginas e navegação por páginas internas do site até a profundidade especificada, o que permite percorrer todas as páginas do site, coletando links internos e externos. Possui ferramentas integradas para contornar a proteção CloudFlare e também a possibilidade de escolher Chrome como motor para extração de e-mails de páginas cujos dados são carregados por scripts. Capaz de atingir velocidades de até 2000 requisições por minuto – isso representa 120 000 links por hora.Casos de uso do scraper
Coleta de todos os links externos de um site
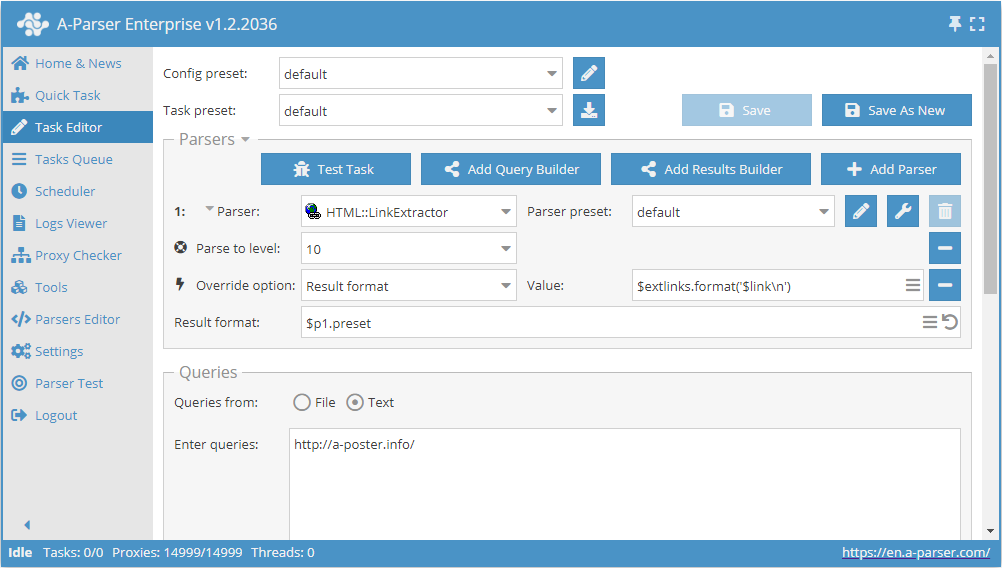
- Adicionar a opção Parse to level, na lista selecionar o valor
10(navegação por páginas adjacentes até o 10º nível). - Adicionar a opção Result format, como valor indicar
$extlinks.format('$link\n')(saída de links externos). - Na seção Queries (Consultas), marcar a opção
Unique queries. - Na seção Results (Resultados), marcar a opção
Unique string. - Como consulta, indicar o link do site do qual se deseja extrair os links externos.
Baixar exemplo
Como importar o exemplo para o A-Parser
eJxtU01v2zAM/S9CgK5AlrSHXnxLgwZb4dZdm57SHISYztTIoirRWQrD/32U7NjJ
1ptIvsfHL9WCpN/5JwceyItkVQsb3yIRORSy0iTGwkrnwYXwSvxYPqRJkiqzuzuQ
kxtCx4geWwv6tMBstKTQeI6pnM2YIoU9aPbspa4Yc33VnOD34JzK4Ugo0JWSuJa2
hI4iRnAgzeJ+0gK+XYyC+fZmLi5Fs16PRUvxixgODHs96Xrqgy9yD0sMKkrD4F6w
9SjLqJNLghA96lxO6BAyyDxXoTOpW4UwlUH11aiPWKcnp8yW8Ww6BX7hsGQ3QUwS
nJ/HCldiFG3BaarI/9VyREKugrHwXO1Cci15Hyik9hxRBE7yBrJu2Ekt0My0joMe
YDH9baV0zlucFUz62RG/hmT/5Wj6Dk+leGV/HNfQZ4nWbfYwsHJMccuNG+S2tSoV
se3nWJmwmyt27gBsP7bHACvRQS/TZe7U+VAtmHAfw9ZmdnCdtXG2mXPnBk2htll3
c0dkZZb8GzIzx9JqCH2ZSmveiofn4UJmvltDMIYC/yXPo8TZPyJE7e9f2lKtU3yB
N6HAkid5qtql3EitX5/T04gYLoqN30Q2mU7ld4ueFzpRpsCpCESCLfJFcVvNuv+/
/S+vv/zFSd3wwt79U4sO3QUs+3hMnrfBP7b5C6wbebo=
dica
Coleta de todos os links internos de um site
Semelhante ao primeiro caso, mas no passo 2, como valor, deve-se indicar $intlinks.format('$link\n') (saída de links internos).
Baixar exemplo
Como importar o exemplo para o A-Parser
eJxtU8tu2zAQ/BfCQBrAtZNDL7o5Roy2cOI0j5PjA2GtXNYUyZIrN4Ggf++QkiW7
zY27O7OzL9aCZdiHB0+BOIhsXQuX3iITORWy0izGwkkfyMfwWnx9vltm2VKZ/e0b
e7ll64HosbXgd0dgW8fKmoCYymGmFEs6kIbnIHUFzPVVc4I/kPcqpyOhsL6UjFra
EjqKGCnDGuJh0gI+XYyi+fpqLi5Fs9mMRUsJixSODHc96Xrqg0/yQM82qihNg3sB
616WSSeXTDF61Lmc8FvMIPNcxc6kbhXiVAbVF6N+pzoDe2V2wMP0isLC2xJuppQk
Ot+PFa7FKNkCaarE/9FyRMa+orEIqHYhUUveBwqpAyKKyUtsYNUNO6uFNTOt06AH
WEp/UymdY4uzAqRvHfFjyOq/HE3f4akUVvbHo4Y+S7JuVncDK7dLu0PjxqJtrUrF
sMPcVibu5grOPZHrx3YfYaX11Mt0mTt1HKojE+9j2NrMDa6zNs42c+7cWlOo3aq7
uSOyMs/4DSszt6XTFPsyldbYSqDH4UJmoVtDNIYC/yXPk8TZP2Jrdfj+1JbqvMIF
fokFlpjkqWqXciu1fnlcnkbEcFEwfjK7bDqVn50NWOhEmcJORSQy7SwuCm01m/7/
9r+8/vAXZ3WDhf0KDy06dhex8GFMAdvAj23+ApcrebQ=
Navegação apenas por links que não contêm a palavra forum
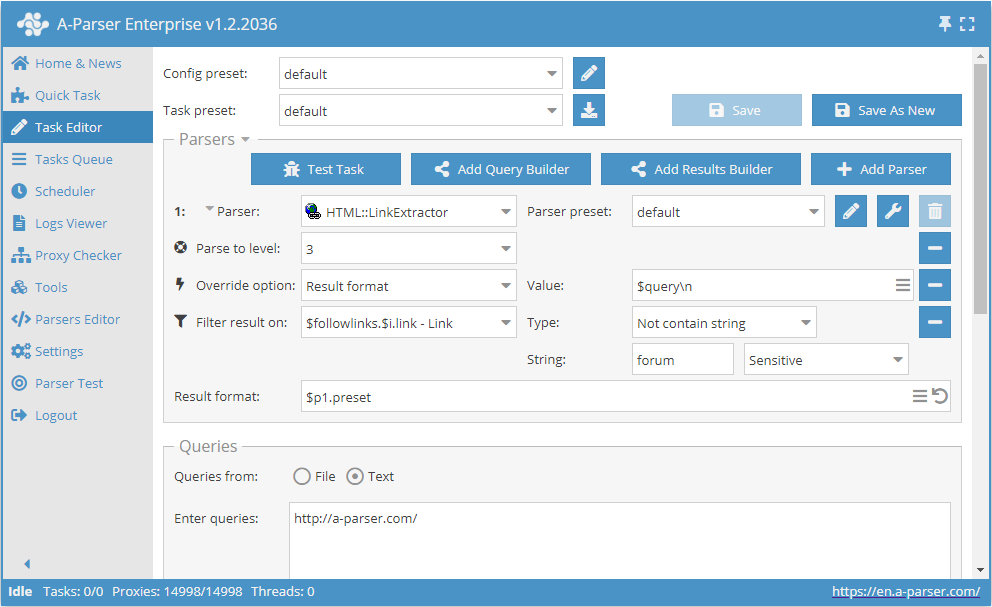
- Adicionar a opção Parse to level, na lista selecionar o valor
3(navegação por páginas adjacentes até o 3º nível). - Adicionar a opção Result format, como valor indicar
$query. - Adicionar um filtro. Filtrar por
$followlinks.$i.link - Link, selecionar o tipoNot contain string, e como a própria string indicarforum. - Na seção Queries (Consultas), marcar a opção
Unique queries. - Na seção Results (Resultados), marcar a opção
Unique string. - Como consulta, indicar o link do site do qual se deseja extrair os links.
Baixar exemplo
Como importar o exemplo para o A-Parser
eJxtVE1v2zAM/S/CDhuQJS2GXXxLgwbd4DZdm57SHISYzrTIkipRaQvD/33UR2xn
6ykh+R75+CG3DLk7uHsLDtCxYtMyE/+zglVQcy+RTZjh1oEN4Q27Wd+WRVEKdbh+
Q8t3qC0hemzL8N0AsbVBoZWjmKjIjClKOIIkz5FLT5hv3Qh+BGtFBSd8rW3DkaQk
BZnBPr14sO/Pz4qNuLWQCEFFhhcbokupXyWpDArCL9tOMnCdWErjTivkQo3yU1nf
kJ3Uk8MB9dBtt6fkbhmFBSnmcppn1Qcf+RHWOkmCwb0k6443sYGKI4ToNHX4+csU
30IGXlUi1OQyVQjTHqo+KfESBTq0Qu0JHwYhwC2tbsiNEJPE6ZwUbvK0Quc+8n8l
DivQepgwR2qXnLRUfaDm0lFE0Jg4bXaVl1i0TKu5lHGBAyymv/JCVnQd85pIPzLx
Y8jqvxxd3+G4FN3CqyUNfZZoXa1uB1alS72PW4z7bQSS7Rbaq7CbC3IeAEw/trsA
a7SFvkzOnKvTAzCgwuENW5ubwXXWxtlmzp10UbXYr/Ixn5BeremVrdRCN0ZC6Et5
KWkrDh6GC5m7vIZgDAL/JS9iibP3iVpL9/MxSTVW0AV+DwIbmuS4ak6541I+PZTj
CBsuiozfiKaYzfjX9PCnO93MWOAh7DUdFHXVbfvPQv/xaD/8OBRtR/v64+4TOjQX
sOSjKbn4yi67v8azl7c=
dica
Dados coletados
- Número de links externos
- Número de links internos
- Links externos:
- os próprios links
- âncoras
- âncoras limpas de tags HTML
- parâmetro nofollow
- tag
<a>completa
- Links internos:
- os próprios links
- âncoras
- âncoras limpas de tags HTML
- parâmetro nofollow
- tag
<a>completa
- Array com todas as páginas coletadas (usado quando a opção Use Pages está ativa)
Recursos
- Extração de dados multipáginas (navegação por páginas)
- Navegação pelas páginas internas do site até a profundidade especificada (opção Parse to level) – permite percorrer todas as páginas do site, coletando links internos e externos
- Limite de navegação por páginas (opção Follow links limit)
- Limpa automaticamente a âncora de tags HTML
- Identificação de nofollow para cada link
- Possibilidade de especificar se subdomínios devem ser considerados como páginas internas do site
- Suporta compressão gzip/deflate/brotli
- Identificação e conversão de codificações de sites para UTF-8
- Contorno de proteção CloudFlare
- Escolha do motor (HTTP ou Chrome)
Casos de uso
- Obtenção do mapa completo do site (salvando todos os links internos)
- Obtenção de todos os links externos de um site
- Verificação de backlink para o seu próprio site
Consultas
Como consultas, é necessário indicar os links das páginas das quais se deseja coletar os links, ou o ponto de entrada (por exemplo, a página inicial do site), nos casos em que a opção Parse to level é utilizada:
https://lenta.ru/
https://a-parser.com/wiki/index/
Exemplos de saída de resultados
O A-Parser suporta formatação flexível de resultados graças ao motor de modelos integrado Template Toolkit, o que permite exibir resultados em formato livre, bem como estruturado, por exemplo, CSV ou JSON
Saída de links externos e internos com suas quantidades
Formato do resultado:
External links: $extcount\n$extlinks.format('$link\n')
Internal links: $intcount\n$intlinks.format('$link\n')
Exemplo de resultado:
External links: 12
https://www.youtube.com/c/AParser_channel
https://t.me/a_parser
https://en.a-parser.com/
https://spyserp.com/ru/
https://sitechecker.pro/
https://arsenkin.ru/tools/
https://spyserp.com/
http://www.promkaskad.ru/
https://www.youtube.com/channel/UCvypGICrfCky8tPtebmIvQw
https://www.facebook.com/AParserRu
https://twitter.com/a_parser
https://www.youtube.com/c/AParser_channel
Internal links: 129
https://a-parser.com/
https://a-parser.com/
https://a-parser.com/a-parser-for-seo/
https://a-parser.com/a-parser-for-business-and-freelancers/
https://a-parser.com/a-parser-for-developers/
https://a-parser.com/a-parser-for-marketing-and-analytics/
https://a-parser.com/a-parser-for-e-commerce/
https://a-parser.com/a-parser-for-cpa/
https://a-parser.com/wiki/features-and-benefits/
https://a-parser.com/wiki/parsers/
Configurações possíveis
nota
| Nome do parâmetro | Valor padrão | Descrição |
|---|---|---|
| Good status | All | Escolha de qual resposta do servidor será considerada bem-sucedida. Se houver outra resposta do servidor durante a extração, a consulta será repetida com outro proxy |
| Good code RegEx | Possibilidade de especificar uma expressão regular para verificar o código de resposta | |
| Ban Proxy Code RegEx | Possibilidade de banir o proxy temporariamente (Proxy ban time) com base no código de resposta do servidor | |
| Method | GET | Método da requisição |
| POST body | Conteúdo para enviar ao servidor ao usar o método POST. Suporta as variáveis $query – URL da consulta, $query.orig – consulta original e $pagenum - número da página ao usar a opção Use Pages. | |
| Cookies | Possibilidade de especificar cookies para a requisição. | |
| User agent | _O user-agent da versão atual do Chrome é inserido automaticamente_ | Cabeçalho User-Agent ao solicitar páginas |
| Additional headers | Possibilidade de especificar cabeçalhos de requisição personalizados com suporte aos recursos do motor de modelos e uso de variáveis do construtor de consultas | |
| Read only headers | ☐ | Ler apenas cabeçalhos. Em alguns casos, permite economizar tráfego se não houver necessidade de processar o conteúdo |
| Detect charset on content | ☐ | Reconhecer a codificação com base no conteúdo da página |
| Emulate browser headers | ☐ | Emular cabeçalhos de navegador |
| Max redirects count | 0 | Número máximo de redirecionamentos que o scraper seguirá |
| Follow common redirects | ☑ | Permite fazer redirecionamentos http <-> https e www.domain <-> domain dentro do mesmo domínio, ignorando o limite Max redirects count |
| Max cookies count | 16 | Número máximo de cookies para salvar |
| Engine | HTTP (Fast, JavaScript Disabled) | Permite escolher o motor HTTP (mais rápido, sem JavaScript) ou Chrome (mais lento, JavaScript ativado) |
| Chrome Headless | ☐ | Se a opção estiver ativada, o navegador não será exibido |
| Chrome DevTools | ☑ | Permite usar ferramentas de depuração do Chromium |
| Chrome Log Proxy connections | ☑ | Se a opção estiver ativada, informações sobre as conexões do chrome serão exibidas no log |
| Chrome Wait Until | networkidle2 | Define quando a página é considerada carregada. Mais detalhes sobre os valores. |
| Use HTTP/2 transport | ☐ | Define se deve usar HTTP/2 em vez de HTTP/1.1. Por exemplo, Google e Majestic banem imediatamente se usar HTTP/1.1. |
| Don't verify TLS certs | ☐ | Desativação da validação de certificados TLS |
| Randomize TLS Fingerprint | ☐ | Esta opção permite contornar o banimento de sites por impressão digital TLS |
| Bypass CloudFlare | ☑ | Contorno automático da verificação CloudFlare |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Contorno de CF via Chrome |
| Bypass CloudFlare with Chrome Max Pages | 20 | Número máx. de páginas ao contornar CF via Chrome |
| Subdomains are internal | ☐ | Se deve considerar subdomínios como links internos |
| Follow links | Internal only | Quais links seguir |
| Follow links limit | 0 | Limite de Follow links, aplicado a cada domínio único |
| Skip comment blocks | ☐ | Se deve ignorar blocos de comentários |