HTML::LinkExtractor - Scraper för externa och interna länkar från angiven webbplats
Översikt av scrapern
 HTML::LinkExtractor – scraper för externa och interna länkar från en angiven webbplats. Stöder flersidig dataskrapning och navigering genom interna sidor på webbplatsen till angivet djup, vilket gör det möjligt att gå igenom alla sidor på webbplatsen och samla in interna och externa länkar. Har inbyggda verktyg för att kringgå skydd från CloudFlare och även möjlighet att välja Chrome som motor för att skrapa e-post från sidor där data laddas med skript. Kan uppnå en hastighet på upp till 2000 frågor per minut – vilket är 120 000 länkar per timme.
HTML::LinkExtractor – scraper för externa och interna länkar från en angiven webbplats. Stöder flersidig dataskrapning och navigering genom interna sidor på webbplatsen till angivet djup, vilket gör det möjligt att gå igenom alla sidor på webbplatsen och samla in interna och externa länkar. Har inbyggda verktyg för att kringgå skydd från CloudFlare och även möjlighet att välja Chrome som motor för att skrapa e-post från sidor där data laddas med skript. Kan uppnå en hastighet på upp till 2000 frågor per minut – vilket är 120 000 länkar per timme.Användningsfall för scrapern
Insamling av alla externa länkar från en webbplats
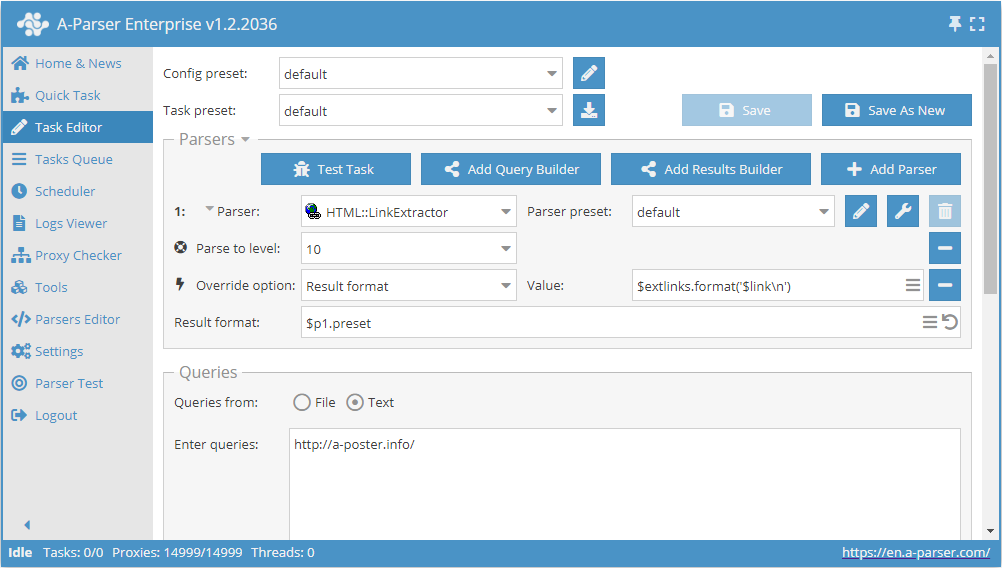
- Lägg till alternativet Parse to level, välj värdet
10i listan (navigering genom angränsande sidor upp till nivå 10). - Lägg till alternativet Result format, ange
$extlinks.format('$link\n')som värde (utmatning av externa länkar). - I avsnittet Queries (Frågor), markera alternativet
Unique queries(Frågedubblettkontroll). - I avsnittet Results, markera alternativet
Unique string(Dubblettkontroll per rad). - Ange länken till den webbplats som du vill skrapa externa länkar från som fråga.
Ladda ner exempel
Hur man importerar ett exempel till A-Parser
eJxtU01v2zAM/S9CgK5AlrSHXnxLgwZb4dZdm57SHISYztTIoirRWQrD/32U7NjJ
1ptIvsfHL9WCpN/5JwceyItkVQsb3yIRORSy0iTGwkrnwYXwSvxYPqRJkiqzuzuQ
kxtCx4geWwv6tMBstKTQeI6pnM2YIoU9aPbspa4Yc33VnOD34JzK4Ugo0JWSuJa2
hI4iRnAgzeJ+0gK+XYyC+fZmLi5Fs16PRUvxixgODHs96Xrqgy9yD0sMKkrD4F6w
9SjLqJNLghA96lxO6BAyyDxXoTOpW4UwlUH11aiPWKcnp8yW8Ww6BX7hsGQ3QUwS
nJ/HCldiFG3BaarI/9VyREKugrHwXO1Cci15Hyik9hxRBE7yBrJu2Ekt0My0joMe
YDH9baV0zlucFUz62RG/hmT/5Wj6Dk+leGV/HNfQZ4nWbfYwsHJMccuNG+S2tSoV
se3nWJmwmyt27gBsP7bHACvRQS/TZe7U+VAtmHAfw9ZmdnCdtXG2mXPnBk2htll3
c0dkZZb8GzIzx9JqCH2ZSmveiofn4UJmvltDMIYC/yXPo8TZPyJE7e9f2lKtU3yB
N6HAkid5qtql3EitX5/T04gYLoqN30Q2mU7ld4ueFzpRpsCpCESCLfJFcVvNuv+/
/S+vv/zFSd3wwt79U4sO3QUs+3hMnrfBP7b5C6wbebo=
tips
Insamling av alla interna länkar från en webbplats
På samma sätt som i det första fallet, men i steg 2 ska värdet $intlinks.format('$link\n') anges (utmatning av interna länkar).
Ladda ner exempel
Hur man importerar ett exempel till A-Parser
eJxtU8tu2zAQ/BfCQBrAtZNDL7o5Roy2cOI0j5PjA2GtXNYUyZIrN4Ggf++QkiW7
zY27O7OzL9aCZdiHB0+BOIhsXQuX3iITORWy0izGwkkfyMfwWnx9vltm2VKZ/e0b
e7ll64HosbXgd0dgW8fKmoCYymGmFEs6kIbnIHUFzPVVc4I/kPcqpyOhsL6UjFra
EjqKGCnDGuJh0gI+XYyi+fpqLi5Fs9mMRUsJixSODHc96Xrqg0/yQM82qihNg3sB
616WSSeXTDF61Lmc8FvMIPNcxc6kbhXiVAbVF6N+pzoDe2V2wMP0isLC2xJuppQk
Ot+PFa7FKNkCaarE/9FyRMa+orEIqHYhUUveBwqpAyKKyUtsYNUNO6uFNTOt06AH
WEp/UymdY4uzAqRvHfFjyOq/HE3f4akUVvbHo4Y+S7JuVncDK7dLu0PjxqJtrUrF
sMPcVibu5grOPZHrx3YfYaX11Mt0mTt1HKojE+9j2NrMDa6zNs42c+7cWlOo3aq7
uSOyMs/4DSszt6XTFPsyldbYSqDH4UJmoVtDNIYC/yXPk8TZP2Jrdfj+1JbqvMIF
fokFlpjkqWqXciu1fnlcnkbEcFEwfjK7bDqVn50NWOhEmcJORSQy7SwuCm01m/7/
9r+8/vAXZ3WDhf0KDy06dhex8GFMAdvAj23+ApcrebQ=
Navigera endast till länkar som inte innehåller ordet forum
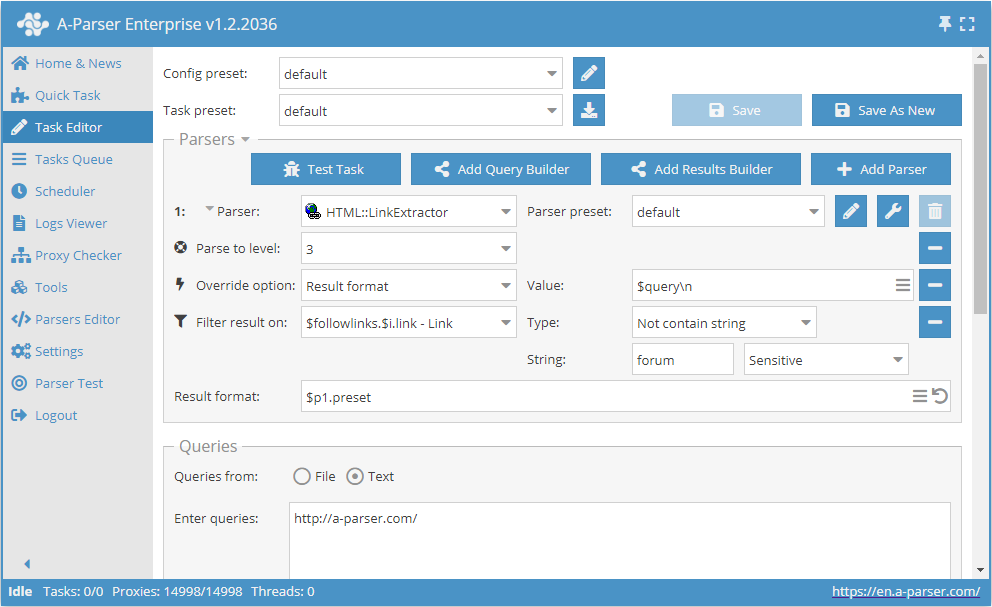
- Lägg till alternativet Parse to level, välj värdet
3i listan (navigering genom angränsande sidor upp till nivå 3). - Lägg till alternativet Result format, ange
$querysom värde. - Lägg till ett filter. Filtrera efter
$followlinks.$i.link - Link, välj typenNot contain string(Innehåller inte strängen), och angeforumsom själva strängen. - I avsnittet Queries (Frågor), markera alternativet
Unique queries(Frågedubblettkontroll). - I avsnittet Results, markera alternativet
Unique string(Dubblettkontroll per rad). - Ange länken till den webbplats som du vill skrapa länkar från som fråga.
Ladda ner exempel
Hur man importerar ett exempel till A-Parser
eJxtVE1v2zAM/S/CDhuQJS2GXXxLgwbd4DZdm57SHISYzrTIkipRaQvD/33UR2xn
6ykh+R75+CG3DLk7uHsLDtCxYtMyE/+zglVQcy+RTZjh1oEN4Q27Wd+WRVEKdbh+
Q8t3qC0hemzL8N0AsbVBoZWjmKjIjClKOIIkz5FLT5hv3Qh+BGtFBSd8rW3DkaQk
BZnBPr14sO/Pz4qNuLWQCEFFhhcbokupXyWpDArCL9tOMnCdWErjTivkQo3yU1nf
kJ3Uk8MB9dBtt6fkbhmFBSnmcppn1Qcf+RHWOkmCwb0k6443sYGKI4ToNHX4+csU
30IGXlUi1OQyVQjTHqo+KfESBTq0Qu0JHwYhwC2tbsiNEJPE6ZwUbvK0Quc+8n8l
DivQepgwR2qXnLRUfaDm0lFE0Jg4bXaVl1i0TKu5lHGBAyymv/JCVnQd85pIPzLx
Y8jqvxxd3+G4FN3CqyUNfZZoXa1uB1alS72PW4z7bQSS7Rbaq7CbC3IeAEw/trsA
a7SFvkzOnKvTAzCgwuENW5ubwXXWxtlmzp10UbXYr/Ixn5BeremVrdRCN0ZC6Et5
KWkrDh6GC5m7vIZgDAL/JS9iibP3iVpL9/MxSTVW0AV+DwIbmuS4ak6541I+PZTj
CBsuiozfiKaYzfjX9PCnO93MWOAh7DUdFHXVbfvPQv/xaD/8OBRtR/v64+4TOjQX
sOSjKbn4yi67v8azl7c=
tips
Insamlade data
- Antal externa länkar
- Antal interna länkar
- Externa länkar:
- själva länkarna
- ankare
- ankare rensade från HTML-taggar
- nofollow-parameter
- hela
<a>-taggen
- Interna länkar:
- själva länkarna
- ankare
- ankare rensade från HTML-taggar
- nofollow-parameter
- hela
<a>-taggen
- Array med alla insamlade sidor (används när alternativet Use Pages är aktiverat)
Funktioner
- Flersidig dataskrapning (navigering mellan sidor)
- Navigering genom interna sidor på webbplatsen till angivet djup (alternativet Parse to level) – gör det möjligt att gå igenom alla sidor på webbplatsen och samla in interna och externa länkar
- Gräns för länknavigering (alternativet Follow links limit)
- Rensar automatiskt ankare från HTML-taggar
- Identifiering av nofollow för varje länk
- Möjlighet att ange att underdomäner ska räknas som interna sidor på webbplatsen
- Stöder komprimering med gzip/deflate/brotli
- Identifiering och konvertering av webbplatsers kodning till UTF-8
- Förbigång av CloudFlare-skydd
- Val av motor (HTTP eller Chrome)
Användningsområden
- Hämta en fullständig webbplatskarta (spara alla interna länkar)
- Hämta alla externa länkar från en webbplats
- Kontrollera en tillbakalänk till den egna webbplatsen
Frågor
Som frågor måste du ange länkar till de sidor som du vill samla in länkar från, eller en ingångspunkt (till exempel webbplatsens startsida) när alternativet Parse to level används:
https://lenta.ru/
https://a-parser.com/wiki/index/
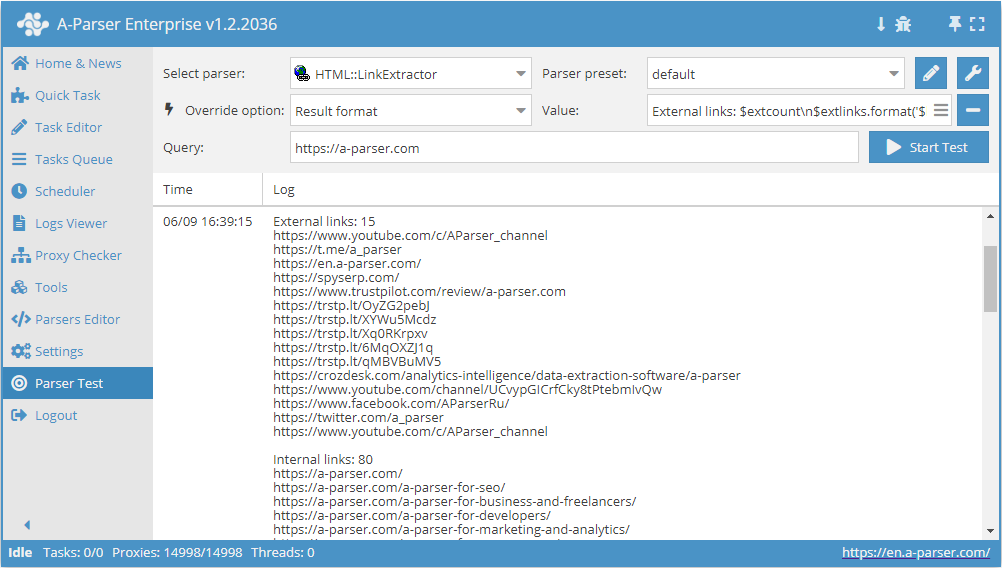
Exempel på resultatutmatning
A-Parser stöder flexibel formatering av resultat tack vare den inbyggda mallmotorn Template Toolkit, vilket gör det möjligt att mata ut resultat i valfri form, såväl som i strukturerad form som CSV eller JSON
Utmatning av externa och interna länkar med deras antal
Resultatformat:
External links: $extcount\n$extlinks.format('$link\n')
Internal links: $intcount\n$intlinks.format('$link\n')
Exempel på resultat:
External links: 12
https://www.youtube.com/c/AParser_channel
https://t.me/a_parser
https://en.a-parser.com/
https://spyserp.com/ru/
https://sitechecker.pro/
https://arsenkin.ru/tools/
https://spyserp.com/
http://www.promkaskad.ru/
https://www.youtube.com/channel/UCvypGICrfCky8tPtebmIvQw
https://www.facebook.com/AParserRu
https://twitter.com/a_parser
https://www.youtube.com/c/AParser_channel
Internal links: 129
https://a-parser.com/
https://a-parser.com/
https://a-parser.com/a-parser-for-seo/
https://a-parser.com/a-parser-for-business-and-freelancers/
https://a-parser.com/a-parser-for-developers/
https://a-parser.com/a-parser-for-marketing-and-analytics/
https://a-parser.com/a-parser-for-e-commerce/
https://a-parser.com/a-parser-for-cpa/
https://a-parser.com/wiki/features-and-benefits/
https://a-parser.com/wiki/parsers/
Möjliga inställningar
anteckning
| Parameternamn | Standardvärde | Beskrivning |
|---|---|---|
| Good status | All | Val av vilket svar från servern som ska anses vara lyckat. Om ett annat svar erhålls vid skrapning kommer begäran att upprepas med en annan proxy |
| Good code RegEx | Möjlighet att ange ett reguljärt uttryck för att kontrollera svarskoden | |
| Ban Proxy Code RegEx | Möjlighet att banna proxyn under en viss tid (Proxy ban time) baserat på serverns svarskod | |
| Method | GET | Metod för begäran |
| POST body | Innehåll som ska skickas till servern när POST-metoden används. Stöder variablerna $query – fråge-URL, $query.orig – ursprunglig fråga och $pagenum - sidnummer när alternativet Use Pages används. | |
| Cookies | Möjlighet att ange cookies för begäran. | |
| User agent | _User-agent för den aktuella versionen av Chrome läggs till automatiskt_ | User-Agent-huvud vid begäran av sidor |
| Additional headers | Möjlighet att ange anpassade begäranshuvuden med stöd för mallmotorns funktioner och användning av variabler från frågebyggaren | |
| Read only headers | ☐ | Läs endast huvuden. I vissa fall sparar detta trafik om det inte finns något behov av att bearbeta innehållet |
| Detect charset on content | ☐ | Identifiera kodning baserat på sidans innehåll |
| Emulate browser headers | ☐ | Emulera webbläsarhuvuden |
| Max redirects count | 0 | Maximalt antal omdirigeringar som scrapern kommer att följa |
| Follow common redirects | ☑ | Tillåter omdirigeringar http <-> https och www.domain <-> domain inom samma domän utanför gränsen för Max redirects count |
| Max cookies count | 16 | Maximalt antal cookies som ska sparas |
| Engine | HTTP (Fast, JavaScript Disabled) | Gör det möjligt att välja motor: HTTP (snabbare, utan JavaScript) eller Chrome (långsammare, JavaScript aktiverat) |
| Chrome Headless | ☐ | Om alternativet är aktiverat kommer webbläsaren inte att visas |
| Chrome DevTools | ☑ | Tillåter användning av verktyg för felsökning av Chromium |
| Chrome Log Proxy connections | ☑ | Om alternativet är aktiverat kommer information om Chrome-anslutningar att visas i loggen |
| Chrome Wait Until | networkidle2 | Definierar när sidan anses vara laddad. Mer information om värdena. |
| Use HTTP/2 transport | ☐ | Definierar om HTTP/2 ska användas istället för HTTP/1.1. Till exempel bannar Google och Majestic omedelbart om HTTP/1.1 används. |
| Don't verify TLS certs | ☐ | Inaktivera validering av TLS-certifikat |
| Randomize TLS Fingerprint | ☐ | Detta alternativ gör det möjligt att kringgå blockering av webbplatser baserat på TLS-fingeravtryck |
| Bypass CloudFlare | ☑ | Automatisk förbigång av CloudFlare-kontroll |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Förbigång av CF via Chrome |
| Bypass CloudFlare with Chrome Max Pages | 20 | Max antal sidor vid förbigång av CF via Chrome |
| Subdomains are internal | ☐ | Om underdomäner ska räknas som interna länkar |
| Follow links | Internal only | Vilka länkar som ska följas |
| Follow links limit | 0 | Gräns för Follow links, tillämpas på varje unik domän |
| Skip comment blocks | ☐ | Om kommentarsblock ska hoppas över |