HTML::TextExtractor - Datenerfassung von Inhalten (Text) von Websites
Übersicht über den Parser
 HTML::TextExtractor extrahiert Textblöcke von der angegebenen Seite. Dieser Content-Parser unterstützt mehrseitiges Scraping (Paginierung). Er verfügt über integrierte Tools zur Umgehung des Schutzes von CloudFlare und bietet zudem die Möglichkeit, Chrome als Engine für das Scraping von Inhalten auf Seiten zu wählen, deren Daten über Skripte geladen werden. Er kann Geschwindigkeiten von bis zu 2000 Anfragen pro Minute erreichen – das sind 120 000 Links pro Stunde.
HTML::TextExtractor extrahiert Textblöcke von der angegebenen Seite. Dieser Content-Parser unterstützt mehrseitiges Scraping (Paginierung). Er verfügt über integrierte Tools zur Umgehung des Schutzes von CloudFlare und bietet zudem die Möglichkeit, Chrome als Engine für das Scraping von Inhalten auf Seiten zu wählen, deren Daten über Skripte geladen werden. Er kann Geschwindigkeiten von bis zu 2000 Anfragen pro Minute erreichen – das sind 120 000 Links pro Stunde.Anwendungsbeispiele für den Parser
Text-Datenerfassung über Chrome am Beispiel von lingualeo.com
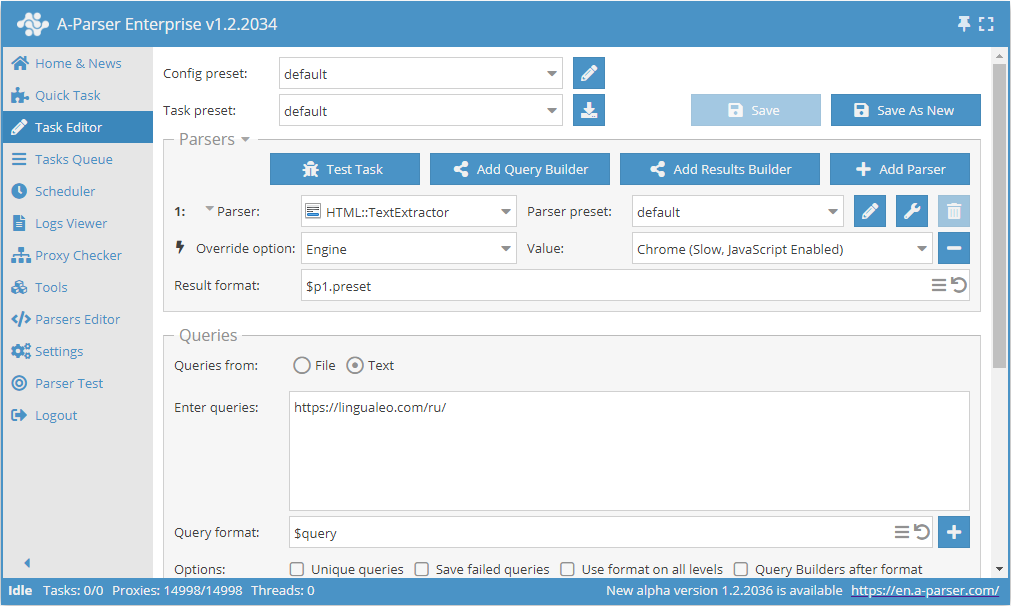
- Die Option Engine hinzufügen und in der Liste den Engine-Typ
Chrome (Slow, JavaScript Enabled)auswählen. - Als Abfrage den Link zur Website angeben, von der der Text extrahiert werden soll.
Diese Option kann in Fällen nützlich sein, in denen die Website den Haupttext während des Ladens der Seite über Skripte nachlädt und bei Verwendung von HTTP (Fast, JavaScript Disabled) das Ergebnis fehlt oder unvollständig ist.
Beispiel herunterladen
Wie man ein Preset in A-Parser importiert
eJxtU01v2zAM/S9EDhsQJO1hF9/SYME6pHXXpqcgB8GmXa2ypOkjS2Hkv+/Jce2k
680kHx8fxeeWgvCv/sGx5+Ap27Zku2/KqORKRBVoSlY4zy6Vt/Rjc7fOsg0fwvdD
cKIIxgExYFsKb5bRbfbsnCwZRVkiZl1LnaK9UDEBihdnGqbjbjcljES3XxnXiDR6
Yq9nvY6h+CT2vDEoVlLxmF4huhdNYpyUInCqzqqO6MvXWTgkBlGWMkijhTpNSJuM
U5+1/NMp8sFJXQOP0En2KwhEOnBHkpJv7wq3NOliAk3s+n+deigLLvKUPNSuBLSU
Q6ESyqMiAzuBV8ttkoR8S0YvlFrzntUI6+hvolQlXn5Roem2b/wckv/HcRw2PB+F
s/x10DCwdNFNfjd2lWZtaiyuDdZWspEBsV+aqNNtrpB8ZbbDs90nWGMcD2N65n46
zGVZJw+MV1vYMXWxxsVlLpOF0ZWs895X78ioN3BwrpemsYrTXjoqhat4fhwdsvD9
GVIwCvzYvOxGXHg/GKP8z6eTVOskHPgtCWzwkudTe8pCKPX8uD6v0OgoBC8hWJ/N
5wpWi0KxmRWmmbs4p9QcuDZwFVY77ob/bvg720//vqw94mi//cMJnTZMWOTwVB4X
oez6+A9VbWHX
Text-Datenerfassung mit Paginierung am Beispiel von Nachrichten
Die Ergebnisse werden im Verzeichnis aparser/results/example/textextractor in einer separaten Datei für jede Abfrage gespeichert. Als Name wird die laufende Nummer der Abfrage verwendet.
- Die Option Check next page hinzufügen und als regulären Ausdruck
(forum\/news\/page-\d+)"[^>]+>Vorwärtsangeben. - Die Option Page as new query hinzufügen.
- Den File name (Dateinamen) in
example/textextractor/${query.num}.txtändern. - Als Abfrage den Link zur ersten Seite mit A-Parser-Nachrichten angeben:
https://a-parser.com/forum/news/.
Beispiel herunterladen
Wie man ein Preset in A-Parser importiert
eJx1VN1v2jAQ/18sHjaVEtjoSx4qUVS0TRRoS58Ik6zkQj0c27UdPhTlf9/ZCQmw
7sXJne/jd7+7c0EsNVuz0GDAGhKuCqL8PwnJ44FmikMYLuFgHw9W09hKHYYzFBd0
A6RLFNUGtPNbkR/Lp+mVLVokkNKcW9ItiD0qwLBSWSaFwTuWoBi/Q7w9C7mjPHdm
X1Kp8yyKAgF7gx+F17dRlNx8jcjq9/365j7K+8PBN3d+T/15585h3513A68ZYkCa
JMxlpJyExWW6KcuYq7RPyvK/AF3ikZnB/jkHfWwRWp3DdfQtgPJmU9gBavpluV53
CTKKHJiJ1Bl1+Tpq0Ktpbi5f6Q6WEi9TxqFVT1Ca0czhgqofgUX0cKI46BQfLmFP
5FnZswd7UXGV0fWnRfEm2IdnWEi0dc4MzETLDFUubq08ntCuSMfLBEPk3ve58iFh
SrlBDgxCn1AEmlzfMAuaIsp5TSlSJMWIc09Pa+bjP+SMJzhMoxSdftaOn5vM/4lR
NuWdp9qB3mvE0ETx0sP8qfVK5FRuTmRwNw8om7HMRTUYXd/ThrOZM8ukhiZNHbnO
joukQLixaVs4Uq3qooyLtlwqYylStpljAZolcLLMxRK3dS7G0g2Cq0vknGNbDLy0
4zIydRuc0AK8dh77FAirWVFipeTm12sFVWmG43jnAGbI5HnWOmRMOX97mZ7fkHak
UHi3VpkwCOht9VD0YpkFfq/9VgfExbCwkThdWGG5bl6U5kEqPn1XwgIXlvwxi8ra
FepsUYeMGWwMCQflX6y1tO0=
Erfasste Daten
- Extrahiert Textblöcke von der angegebenen Seite
- Array mit allen erfassten Seiten (wird bei Verwendung der Option Use Pages genutzt)
Funktionen
- Mehrseitige Text-Datenerfassung (Paginierung)
- Automatische Bereinigung des Textes von HTML-Tags
- Möglichkeit, eine Mindestlänge für Textblöcke festzulegen
- Optionales Entfernen von Link-Ankern aus dem Text
- Unterstützt Kompressionen wie gzip/deflate/brotli
- Erkennung und Umwandlung von Website-Kodierungen in UTF-8
- Umgehung des CloudFlare-Schutzes
- Auswahl der Engine (HTTP oder Chrome)
Anwendungsfälle
- Extraktion von Textinhalten von beliebigen Websites
Abfragen
Als Abfragen müssen Links zu den Seiten angegeben werden, von denen Textblöcke extrahiert werden sollen, zum Beispiel:
https://a-parser.com/
Beispiele für die Ergebnisausgabe
A-Parser unterstützt eine flexible Formatierung der Ergebnisse dank der integrierten Template-Engine Template Toolkit, was die Ausgabe in beliebiger Form sowie in strukturierter Form wie CSV oder JSON ermöglicht.
Standardausgabe
Ergebnisformat:
$texts.format('$text\n')
Beispielergebnis:
Hallo, Super-Team von hochkarätigen Profis ihres Fachs! Vielen Dank für die Möglichkeit, Spanisch, Türkisch und Portugiesisch zu lernen! Ich wünsche Ihnen eine weitere Erweiterung Ihrer Möglichkeiten! Inspiration und Kreativität! Und die Bitte, die Möglichkeit zum Erlernen der deutschen und französischen Sprache hinzuzufügen!”
Ich nutze Lingualeo schon seit vielen Jahren, habe das erste Mal angefangen, als es noch gar keine App gab, sondern nur die Website) Danke an die Entwickler, macht weiter so, mit Kreativität und viel Liebe zur Sache)
Technisches Englisch für IT: Wörterbücher, Lehrbücher, Zeitschriften
Sprachen online lernen Englisch online lernen Vietnamesisch online lernen Griechisch online lernen Indonesisch online lernen Spanisch online lernen Italienisch online lernen Chinesisch online lernen Koreanisch online lernen Deutsch online lernen Niederländisch online lernen Polnisch online lernen Portugiesisch online lernen Serbisch online lernen Türkisch online lernen Ukrainisch online lernen Französisch online lernen Hindi online lernen Tschechisch online lernen Japanisch online lernen
Mögliche Einstellungen
| Name des Parameters | Standardwert | Beschreibung |
|---|---|---|
| Min block length | 50 | Minimale Länge des Textblocks in Zeichen. |
| Skip anchor text | ☐ | Ob Anker im Text übersprungen werden sollen. |
| Ignore tags list | Option zur Angabe von Tags, die ignoriert werden sollen. Beispiel: div,span,p | |
| Good status | All | Auswahl, welche Antwort vom Server als erfolgreich gilt. Wenn beim Scrapen eine andere Antwort vom Server kommt, wird die Abfrage mit einem anderen Proxy wiederholt. |
| Good code RegEx | Möglichkeit, einen regulären Ausdruck zur Überprüfung des Antwortcodes anzugeben. | |
| Method | GET | Anfragemethode. |
| POST body | Inhalt, der bei Verwendung der POST-Methode an den Server gesendet wird. Unterstützt Variablen wie $query – Abfrage-URL, $query.orig – ursprüngliche Abfrage und $pagenum – Seitenzahl bei Verwendung der Option Use Pages. | |
| Cookies | Möglichkeit, Cookies für die Abfrage anzugeben. | |
| User agent | `_Automatisch wird der User-Agent der aktuellen Chrome-Version eingesetzt_ | Der User-Agent Header beim Abrufen von Seiten. |
| Additional headers | Möglichkeit, benutzerdefinierte Anfrage-Header anzugeben, unterstützt durch die Funktionen der Template-Engine und Variablen aus dem Abfrage-Builder. | |
| Read only headers | ☐ | Nur Header lesen. In manchen Fällen spart dies Traffic, wenn der Inhalt nicht verarbeitet werden muss. |
| Detect charset on content | ☐ | Kodierung basierend auf dem Seiteninhalt erkennen. |
| Emulate browser headers | ☐ | Browser-Header emulieren. |
| Max redirects count | 7 | Maximale Anzahl an Weiterleitungen, denen der Parser folgt. |
| Max cookies count | 16 | Maximale Anzahl an zu speichernden Cookies. |
| Bypass CloudFlare | ☑ | Automatische Umgehung der CloudFlare-Prüfung. |
| Follow common redirects | ☑ | Ermöglicht Weiterleitungen http <-> https und www.domain <-> domain innerhalb einer Domain unter Umgehung des Limits Max redirects count. |
| Engine | HTTP (Fast, JavaScript Disabled) | Ermöglicht die Wahl zwischen der HTTP-Engine (schneller, ohne JavaScript) oder Chrome (langsamer, JavaScript aktiviert). |
| Chrome Headless | ☐ | Wenn diese Option aktiviert ist, wird der Browser nicht angezeigt. |
| Chrome DevTools | ☑ | Ermöglicht die Verwendung von Chromium-Debugging-Tools. |
| Chrome Log Proxy connections | ☑ | Wenn diese Option aktiviert ist, werden Informationen zu Chrome-Verbindungen im Log ausgegeben. |
| Chrome Wait Until | networkidle2 | Bestimmt, wann eine Seite als geladen gilt. Details zu den Werten. |
| Use HTTP/2 transport | ☐ | Bestimmt, ob HTTP/2 anstelle von HTTP/1.1 verwendet werden soll. Zum Beispiel sperren Google und Majestic sofort, wenn HTTP/1.1 verwendet wird. |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | CF-Umgehung über Chrome. |
| Bypass CloudFlare with Chrome Max Pages | Maximale Anzahl an Seiten bei der CF-Umgehung über Chrome. |