Reddit::Comments - scraper de comentários no Reddit
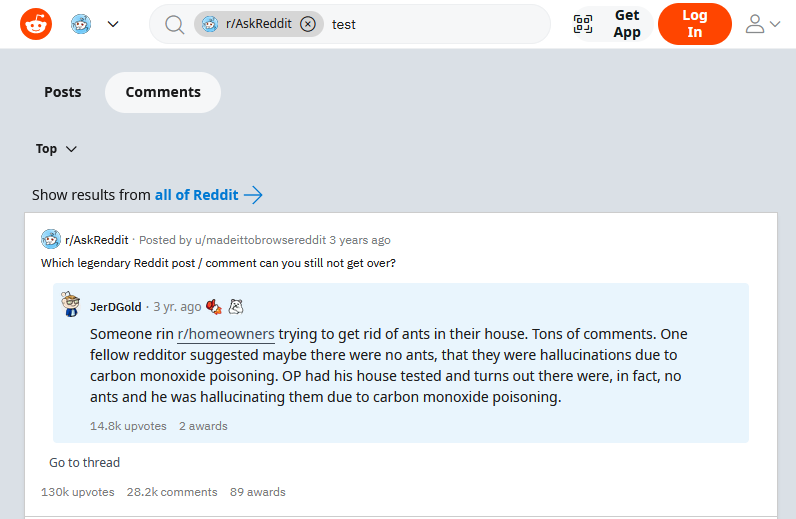
Visão geral do scraper Reddit::Comments
 Reddit::Comments - scraper de mensagens no Reddit.
Reddit::Comments - scraper de mensagens no Reddit.Coleta uma lista de comentários e diversas informações para cada um deles a partir do serviço homônimo.
Você pode usar a multiplicação automática de consultas, substituição de subconsultas a partir de arquivos, geração de combinações alfanuméricas e listas para obter a maior quantidade possível de resultados.
A funcionalidade do A-Parser permite salvar as configurações de extração de dados do scraper Reddit::Posts para uso futuro (predefinições), definir cronogramas de extração de dados e muito mais.
A preservação dos resultados é possível na forma e estrutura que você necessita, graças ao poderoso motor de modelos integrado Template Toolkit, que permite aplicar lógica adicional aos resultados e exibir dados em vários formatos, incluindo JSON, SQL e CSV.
Dados coletados
Array de comentários:
- Link para o comentário
- Conteúdo do comentário (em markdown)
- Classificação e quantidade de prêmios
- Data de criação do comentário
- Autor do comentário e sua etiqueta (flair)
- Link para o post ao qual o comentário pertence
- Título do post e sua etiqueta (flair)
- Classificação do post, quantidade de comentários e quantidade de prêmios
- Data de criação do post
- Comunidade na qual o post foi publicado
- Autor do post e sua etiqueta (flair)
- Conteúdo do post: texto em markdown, link para conteúdo de mídia e link para recurso externo
Recursos
- Especificação do número de páginas para extração de dados
- Especificação do método de ordenação dos resultados
- Possibilidade de extrair dados dentro de uma comunidade específica
Casos de uso
- Quaisquer cenários onde seja necessário coletar comentários deixados em mensagens no Reddit
Consultas
São suportados 2 tipos de consultas:
Palavras-chave
Exemplo:
wordpress features
parser
No resultado, por padrão, será exibida uma lista de links para os comentários, por exemplo:
https://www.reddit.com/r/node/comments/14lmqbq/how_to_work_with_xlsx_files/jpy3r5a/
https://www.reddit.com/r/StardewValley/comments/14qidly/having_problems_installing_stardew_valley/jqnalwz/
https://www.reddit.com/r/elasticsearch/comments/14pr86i/how_to_parsing_this_lin_logstash/jqkstjw/
https://www.reddit.com/r/vexillology/comments/14fh5th/flag_of_riga_michigan/jp10w17/
https://www.reddit.com/r/Marvel/comments/14otc3t/hank_pym_is_a_really_humble_guy_the_mighty/jqf27xy/
https://www.reddit.com/r/math/comments/14p1lkg/from_the_perspective_of_you_mathematicians_what/jqgug4q/
https://www.reddit.com/r/Wordpress/comments/14okx06/help_looking_for_a_specific_plugin_for_booking/jqhwtu5/
https://www.reddit.com/r/osr/comments/13u8g7s/difference_between_whitebox_whitehack/jlzhthi/
...
Palavras-chave e links para comunidades
O scraper suporta a busca por palavra-chave em uma comunidade específica. Para isso, é necessário indicar na consulta a palavra-chave e, após um espaço, o link para a comunidade. Exemplo:
jesus https://www.reddit.com/r/atheism/
stage 3 https://www.reddit.com/r/Audi/
No resultado, por padrão, será exibida uma lista de links para os posts, por exemplo:
https://www.reddit.com/r/atheism/comments/14dp1rv/sen_josh_hawley_shares_his_mindblowingly_stupid/jor20zd/
https://www.reddit.com/r/atheism/comments/14kt69e/why_do_my_christian_friends_view_my_atheism_as_an/jpsgbe5/
https://www.reddit.com/r/atheism/comments/14p6yir/finally_happened_the_one_babysitter_we_can_get/jqhk48s/
https://www.reddit.com/r/Audi/comments/14nyn9m/excuse_me_we_late/jqbdu2a/
https://www.reddit.com/r/Audi/comments/14oqxce/talk_me_inout_of_buying_this_gorgeous_audi_s5/jqev0p6/
https://www.reddit.com/r/Audi/comments/14pqr8a/is_this_a_good_deal_in_your_guys_opinions/jql4wnb/
...
Opções de exibição de resultados
O A-Parser suporta formatação flexível de resultados graças ao motor de modelos integrado Template Toolkit, o que permite exibir resultados em forma livre, bem como estruturada, como CSV ou JSON.
Configurações possíveis
| Parâmetro | Valor padrão | Descrição |
|---|---|---|
| Pages count | 5 | Quantidade de páginas de resultados |
| Sort | Relevance | Ordenação dos resultados |