SE::Google::Position - Verificação de posições de sites por palavras-chave no Google
Visão geral do scraper
Scraper para verificação de posições de sites por palavras-chave no Google. Graças ao scraper SE::Google::Position, você poderá verificar automaticamente as posições nos resultados de busca do Google usando suas próprias bases de domínios. Usando o scraper SE::Google::Position, é possível determinar de forma fácil, precisa e rápida a posição de um site no Google.
A funcionalidade do A-Parser permite salvar as configurações de extração de dados do scraper SE::Google::Position para uso posterior (presets), definir agendamentos de extração de dados e muito mais. Você pode usar a substituição automática de subconsultas a partir de arquivos.
A preservação dos resultados é possível no formato e estrutura que você necessita, graças ao poderoso construtor de modelos integrado Template Toolkit, que permite aplicar lógica adicional aos resultados e exibir dados em vários formatos, incluindo JSON, SQL e CSV.
Casos de uso do scraper
🔗 Trabalhando com a API, parte 1
Exemplo de trabalho com a API do A-Parser usando o scraper de posições SE::Google::Position
🔗 Outro exemplo de trabalho com SE::Google::Position
Determinação da posição do site por palavra-chave, como no navegador do usuário
🔗 Visão geral das opções de representação
O artigo analisa 4 opções diferentes de representação de resultados: texto, CSV, JSON, HTML
🔗 Como descobrir as posições por palavras-chave?
Conhecendo o scraper SE::Google::Position e verificando em qual lugar nos resultados de busca a palavra-chave está localizada
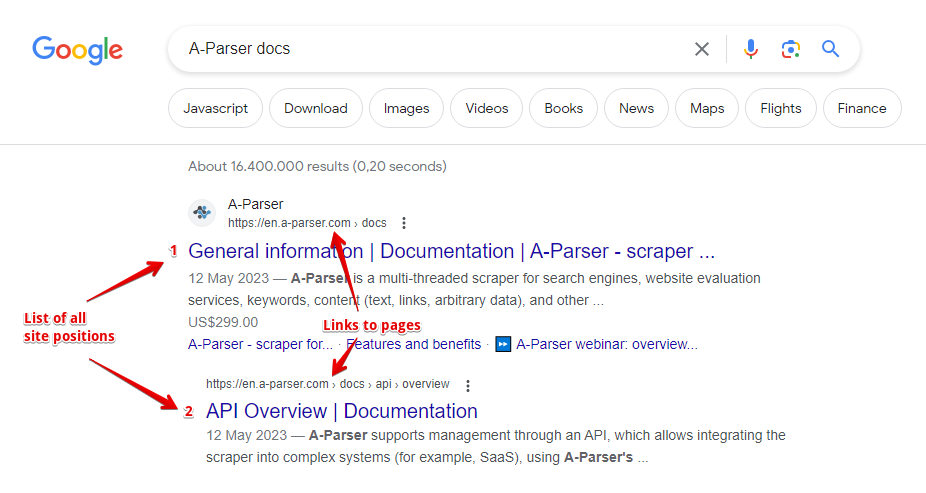
Dados coletados
- A posição do site e o link para a página do site
- Lista de todas as posições do site e links para as páginas
Recursos
- Todos os recursos do scraper
 SE::Google
SE::Google - Interrompe automaticamente a extração de dados ao encontrar o site
- Suporta a busca de subdomínios
- Possibilidade de comparar a posição buscada por domínio, por domínio principal e por link completo
- Coleta de posições para vários domínios simultaneamente
Casos de uso
- Verificação de posições de seus sites e sites de concorrentes
- Busca de páginas com tráfego do site
Consultas
Como consultas, é necessário indicar o domínio do site buscado e a consulta de pesquisa separados por um espaço, por exemplo:
lenta.ru notícias
lenta.ru notícias online
Se for necessário verificar um único site para uma lista de consultas, você pode indicar o domínio no formato de consulta (Query format):
lenta.ru $query
Ou usar apenas uma lista de palavras-chave. Para usar vários domínios em uma consulta simultaneamente, você deve indicar a lista de domínios separados por vírgula e a palavra-chave após um espaço, por exemplo:
lenta.ru,ria.ru,notfound.com notícias feed
Os resultados serão gravados no array $bulkcheck.
A opção Stop when found também é suportada; a extração de dados terminará se as posições forem encontradas para todos os domínios.
Substituições de consultas
Você pode usar macros integradas para a substituição automática de subconsultas a partir de arquivos; por exemplo, se quisermos verificar sites/um site por uma base de chaves, indicaremos algumas consultas principais:
ria.ru
lenta.ru
rbc.ru
yandex.ru
No formato de consultas, indicaremos a macro para substituição de palavras adicionais do arquivo Keywords.txt; este método permite verificar uma base de sites por uma base de chaves e obter as posições como resultado:
$query {subs:Keywords}
Esta macro criará tantas consultas adicionais quantas estiverem no arquivo para cada consulta de pesquisa original, o que resultará em [número de consultas originais(domínios)] x [número de consultas no arquivo Keywords] = [número total de consultas] como resultado da execução da macro.
Opções de exibição de resultados
O A-Parser suporta formatação flexível de resultados graças ao construtor de modelos integrado Template Toolkit, o que permite exibir resultados em forma livre, bem como estruturada, como CSV ou JSON
Exportação da lista de posições
Obtenção do resultado no formato:
domínio buscado - chave: número da posição nos resultados
Formato do resultado:
$domain - $key: $position\n
Exemplo de resultado:
lenta.ru - notícias: 6
lenta.ru - notícias online: 7
...
Verificação simultânea de vários domínios (verificação em lote)
As informações de todos os domínios durante a verificação simultânea de vários domínios estão contidas no array $bulkcheck.
Formato do resultado:
$bulkcheck.format('$domain - $position\n')
Exemplo de consulta:
lenta.ru,ria.ru,notfound.com notícias feed
Exemplo de resultado:
lenta.ru - 1
ria.ru - 3
notfound.com - 0
Links + âncoras + snippets com exibição de posição
Da mesma forma que no SE::Google.
Exibição de links, âncoras e snippets em tabela CSV
Da mesma forma que no SE::Google.
Salvamento de palavras-chave relacionadas
Da mesma forma que no SE::Google.
Concorrência de palavras-chave
Da mesma forma que no SE::Google.
Verificação de indexação de links
Da mesma forma que no SE::Google.
Salvamento no formato SQL
Da mesma forma que no SE::Google.
Dump de resultados em JSON
Da mesma forma que no SE::Google.
Processamento de resultados
O A-Parser permite processar resultados diretamente durante a extração de dados; nesta seção, apresentamos os casos mais populares para o scraper SE::Google::Position
Salvamento de domínios sem posições zero
Tomou-se como base o exemplo de verificação simultânea de vários domínios (veja acima nas opções de exibição de resultados) e adicionou-se um filtro.
Adicione um filtro e, na lista suspensa, selecione a variável de saída da posição. Selecione o tipo: >. Em seguida, no campo Number (Número), insira 0. Com este filtro, você poderá remover todos os resultados com posição zero.
Baixar exemplo
Como importar um exemplo para o A-Parser
eJx1VNtu2zAM/RVDCNAVyIJ2a4HBDwPSYhk2ZE3Wy1OaB9WiUy2y6Ely2szwv4+S
ZTvtuhdZJA/Jw4tcM8ft1i4NWHCWpaualeHOUnbzJU2/Im4UpOkSrXQSdfI+ueE7
SAQWXGqbPEn3iJVLePIHDCZlhLExK7mxYHzI1ZuRCCIg55VybFwzty+BUuIOjJEC
yCgFyTmagjsiFGBsx1XlYaOHSm2zR8i2kxbx7mjUMiJ+o47E/b0+OmbN/6NXFkqD
z/shcs6VhQOPXCoHhuyRQrpifWpfY1fLehyht63f5wOyJ3THMsBSZkFb1qzXXUQ7
C/x9TeXpJLa+N/pW32LLAwb1jKQrXoROCO7AW7tGHE/cs4/AhQjUuGoz+EEMWe+0
/B3IaSQsXY0EOzNYkMpBCOCV+47dio2C7Autgu/P1ie2bMwsUZ1xIiJeWyS1hTs0
i9AD0tcM9VSpOexADbAQ/6KSStDWTHNy+hYd34Ys/onR9OUdpqKZPxni0EcJ0sXi
x+AlcI4bqlw8UN1KFtKRbC+x0i7ObwtQ9j278j0r0ECfJkaO2ekxlaD9gg0jm5aD
6kUZL8byUpmhzuVmEZe2Q1b6ll7sQl9iUSrwdelKqbFf5uthPaY2jsELA8HXzpch
hS+9e4rMISr7/aalWhpJ63fuCRbUycOsMWTGlbq7nh9a2LBSJCjQjk9MNTYyfDS6
nDorJhkWyX11cvZRhBPC+WG4n52Gs9V8aqEP4Twf3KLZzyijl7BB2lHqU7Puf0D9
r61++zeU1g2twC+7bOG+Xx5MOmq8DYjT5i+HCcki
Veja também: Filtros de resultados
Desduplicação de links
Da mesma forma que no SE::Google.
Desduplicação de links por domínio
Da mesma forma que no SE::Google.
Extração de domínios
Da mesma forma que no SE::Google.
Remoção de tags de âncoras e snippets
Da mesma forma que no SE::Google.
Filtragem de links por inclusão
Da mesma forma que no SE::Google.
Configurações possíveis
Suporta todas as configurações do scraper SE::Google, e adicionalmente:
| Nome do parâmetro | Valor padrão | Descrição |
|---|---|---|
| Pages count | 1 | Quantidade de páginas de resultados para extração (de 1 a 10) |
| Result format | $domain - $key: $position\n | Formato padrão de saída do resultado |
| Stop when found | ☑ | Interromper a extração de dados se o domínio for encontrado; não passará para as páginas seguintes |
| Match type | Exact domain | Possibilidade de comparar a posição buscada por domínio, por domínio principal e por link completo (Exact domain / Top level domain / Exact url) |