HTML::TextExtractor - Extração de dados de conteúdo (texto) de sites
Visão geral do scraper
 HTML::TextExtractor extrai blocos de texto da página especificada. Este scraper de conteúdo suporta extração em múltiplas páginas (navegação por páginas). Possui ferramentas integradas para contornar a proteção CloudFlare e também a possibilidade de escolher Chrome como motor para extração de conteúdo de páginas cujos dados são carregados por scripts. Capaz de atingir velocidades de até 2000 requisições por minuto – isso são 120 000 links por hora.
HTML::TextExtractor extrai blocos de texto da página especificada. Este scraper de conteúdo suporta extração em múltiplas páginas (navegação por páginas). Possui ferramentas integradas para contornar a proteção CloudFlare e também a possibilidade de escolher Chrome como motor para extração de conteúdo de páginas cujos dados são carregados por scripts. Capaz de atingir velocidades de até 2000 requisições por minuto – isso são 120 000 links por hora.Casos de uso do scraper
Extração de texto via Chrome usando o exemplo lingualeo.com
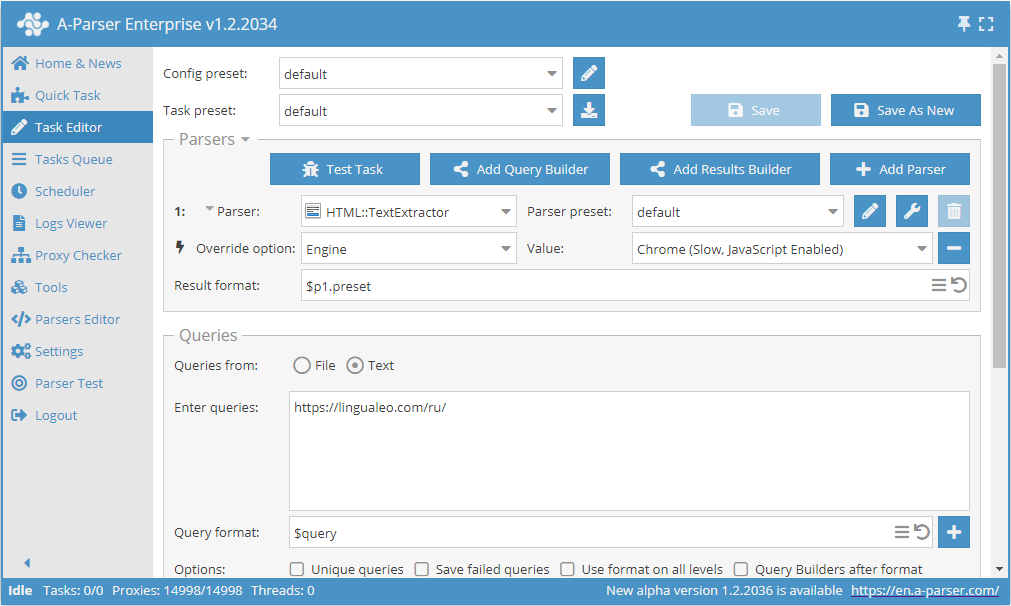
- Adicionar a opção Engine, na lista selecionar o motor
Chrome (Slow, JavaScript Enabled). - Como consulta, indicar o link para o site do qual se deseja extrair o texto.
Esta opção pode ser útil em casos onde o site carrega o texto principal via scripts durante o carregamento da página e, ao usar HTTP (Fast, JavaScript Disabled), o resultado é inexistente ou incompleto.
Baixar exemplo
Como importar o exemplo para o A-Parser
eJxtU01v2zAM/S9EDhsQJO1hF9/SYME6pHXXpqcgB8GmXa2ypOkjS2Hkv+/Jce2k
680kHx8fxeeWgvCv/sGx5+Ap27Zku2/KqORKRBVoSlY4zy6Vt/Rjc7fOsg0fwvdD
cKIIxgExYFsKb5bRbfbsnCwZRVkiZl1LnaK9UDEBihdnGqbjbjcljES3XxnXiDR6
Yq9nvY6h+CT2vDEoVlLxmF4huhdNYpyUInCqzqqO6MvXWTgkBlGWMkijhTpNSJuM
U5+1/NMp8sFJXQOP0En2KwhEOnBHkpJv7wq3NOliAk3s+n+deigLLvKUPNSuBLSU
Q6ESyqMiAzuBV8ttkoR8S0YvlFrzntUI6+hvolQlXn5Roem2b/wckv/HcRw2PB+F
s/x10DCwdNFNfjd2lWZtaiyuDdZWspEBsV+aqNNtrpB8ZbbDs90nWGMcD2N65n46
zGVZJw+MV1vYMXWxxsVlLpOF0ZWs895X78ioN3BwrpemsYrTXjoqhat4fhwdsvD9
GVIwCvzYvOxGXHg/GKP8z6eTVOskHPgtCWzwkudTe8pCKPX8uD6v0OgoBC8hWJ/N
5wpWi0KxmRWmmbs4p9QcuDZwFVY77ob/bvg720//vqw94mi//cMJnTZMWOTwVB4X
oez6+A9VbWHX
Extração de texto com navegação por páginas usando o exemplo de notícias
Os resultados são salvos no diretório aparser/results/example/textextractor em um arquivo separado para cada consulta. Como nome, é utilizado o número sequencial da consulta.
- Adicionar a opção Check next page, como regex indicar
(forum\/news\/page-\d+)"[^>]+>Próximo. - Adicionar a opção Page as new query.
- Alterar o File name (Nome do arquivo) para
example/textextractor/${query.num}.txt. - Como consulta, indicar o link para a primeira página de notícias do A-Parser:
https://a-parser.com/forum/news/.
Baixar exemplo
Como importar o exemplo para o A-Parser
eJx1VN1v2jAQ/18sHjaVEtjoSx4qUVS0TRRoS58Ik6zkQj0c27UdPhTlf9/ZCQmw
7sXJne/jd7+7c0EsNVuz0GDAGhKuCqL8PwnJ44FmikMYLuFgHw9W09hKHYYzFBd0
A6RLFNUGtPNbkR/Lp+mVLVokkNKcW9ItiD0qwLBSWSaFwTuWoBi/Q7w9C7mjPHdm
X1Kp8yyKAgF7gx+F17dRlNx8jcjq9/365j7K+8PBN3d+T/15585h3513A68ZYkCa
JMxlpJyExWW6KcuYq7RPyvK/AF3ikZnB/jkHfWwRWp3DdfQtgPJmU9gBavpluV53
CTKKHJiJ1Bl1+Tpq0Ktpbi5f6Q6WEi9TxqFVT1Ca0czhgqofgUX0cKI46BQfLmFP
5FnZswd7UXGV0fWnRfEm2IdnWEi0dc4MzETLDFUubq08ntCuSMfLBEPk3ve58iFh
SrlBDgxCn1AEmlzfMAuaIsp5TSlSJMWIc09Pa+bjP+SMJzhMoxSdftaOn5vM/4lR
NuWdp9qB3mvE0ETx0sP8qfVK5FRuTmRwNw8om7HMRTUYXd/ThrOZM8ukhiZNHbnO
joukQLixaVs4Uq3qooyLtlwqYylStpljAZolcLLMxRK3dS7G0g2Cq0vknGNbDLy0
4zIydRuc0AK8dh77FAirWVFipeTm12sFVWmG43jnAGbI5HnWOmRMOX97mZ7fkHak
UHi3VpkwCOht9VD0YpkFfq/9VgfExbCwkThdWGG5bl6U5kEqPn1XwgIXlvwxi8ra
FepsUYeMGWwMCQflX6y1tO0=
Dados coletados
- Extrai blocos de texto da página especificada
- Array com todas as páginas coletadas (usado quando a opção Use Pages está ativa)
Recursos
- Extração de texto em múltiplas páginas (navegação por páginas)
- Limpeza automática de tags HTML do texto
- Possibilidade de definir o comprimento mínimo do bloco de texto
- Remoção opcional de âncoras de links do texto
- Suporta compressão gzip/deflate/brotli
- Detecção e conversão de codificações de sites para UTF-8
- Bypass de proteção CloudFlare
- Escolha do motor (HTTP ou Chrome)
Opções de uso
- Extração de conteúdo de texto de quaisquer sites
Consultas
Como consultas, é necessário indicar os links das páginas das quais se deseja extrair os blocos de texto, por exemplo:
https://a-parser.com/
Exemplos de saída de resultados
O A-Parser suporta formatação flexível de resultados graças ao motor de modelos integrado Template Toolkit, o que permite exibir resultados em formato livre, bem como estruturado, como CSV ou JSON
Saída padrão
Formato do resultado:
$texts.format('$text\n')
Exemplo de resultado:
Olá, Super Equipe de Profissionais de Altíssimo Nível! Obrigado pela oportunidade de estudar Espanhol, Turco e Português! Desejo a vocês uma maior expansão de suas Possibilidades! Inspiração e Criatividade! E por favor, adicionem a Possibilidade de estudar Alemão e Francês!”
Uso o lingualeo há muitos anos, comecei a praticar pela primeira vez quando ainda não existia o aplicativo, era apenas o site) Obrigado aos desenvolvedores, continuem assim, com criatividade e muito amor pelo que fazem)
Inglês técnico para TI: dicionários, livros didáticos, revistas
Aprenda idiomas online Aprenda inglês online Aprenda vietnamita online Aprenda grego online Aprenda indonésio online Aprenda espanhol online Aprenda italiano online Aprenda chinês online Aprenda coreano online Aprenda alemão online Aprenda holandês online Aprenda polonês online Aprenda português online Aprenda sérvio online Aprenda turco online Aprenda ucraniano online Aprenda francês online Aprenda hindi online Aprenda tcheco online Aprenda japonês online
Configurações possíveis
| Nome do parâmetro | Valor padrão | Descrição |
|---|---|---|
| Min block length | 50 | Comprimento mínimo do bloco de texto em caracteres. |
| Skip anchor text | ☐ | Se deve ignorar as âncoras no texto. |
| Ignore tags list | Opção para especificar as tags que devem ser ignoradas. Exemplo: div,span,p | |
| Good status | All | Escolha de qual resposta do servidor será considerada bem-sucedida. Se houver outra resposta do servidor durante a extração, a consulta será repetida com outro proxy. |
| Good code RegEx | Possibilidade de especificar uma expressão regular para verificar o código de resposta. | |
| Method | GET | Método da requisição. |
| POST body | Conteúdo para enviar ao servidor ao usar o método POST. Suporta as variáveis $query – URL da consulta, $query.orig – consulta original e $pagenum - número da página ao usar a opção Use Pages. | |
| Cookies | Possibilidade de especificar cookies para a requisição. | |
| User agent | `_O user-agent da versão atual do Chrome é inserido automaticamente_ | Cabeçalho User-Agent ao solicitar páginas. |
| Additional headers | Possibilidade de especificar cabeçalhos de requisição personalizados com suporte aos recursos do motor de modelos e uso de variáveis do construtor de consultas. | |
| Read only headers | ☐ | Ler apenas os cabeçalhos. Em alguns casos, permite economizar tráfego se não houver necessidade de processar o conteúdo. |
| Detect charset on content | ☐ | Reconhecer a codificação com base no conteúdo da página. |
| Emulate browser headers | ☐ | Emular cabeçalhos de navegador. |
| Max redirects count | 7 | Número máximo de redirecionamentos que o scraper seguirá. |
| Max cookies count | 16 | Número máximo de cookies para salvar. |
| Bypass CloudFlare | ☑ | Bypass automático da verificação do CloudFlare. |
| Follow common redirects | ☑ | Permite fazer redirecionamentos http <-> https e www.domain <-> domain dentro do mesmo domínio, ignorando o limite Max redirects count. |
| Engine | HTTP (Fast, JavaScript Disabled) | Permite escolher o motor HTTP (mais rápido, sem JavaScript) ou Chrome (mais lento, JavaScript ativado). |
| Chrome Headless | ☐ | Se a opção estiver ativada, o navegador não será exibido. |
| Chrome DevTools | ☑ | Permite usar ferramentas de depuração do Chromium. |
| Chrome Log Proxy connections | ☑ | Se a opção estiver ativada, informações sobre as conexões do chrome serão exibidas no log. |
| Chrome Wait Until | networkidle2 | Define quando a página é considerada carregada. Mais detalhes sobre os valores. |
| Use HTTP/2 transport | ☐ | Define se deve usar HTTP/2 em vez de HTTP/1.1. Por exemplo, Google e Majestic banem imediatamente se usar HTTP/1.1. |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Bypass de CF via Chrome. |
| Bypass CloudFlare with Chrome Max Pages | Número máx. de páginas ao contornar CF via Chrome. |