SE::Baidu - Scraper de resultados de busca do Baidu
Visão geral do scraper
Scraper de resultados de busca do Baidu. Graças ao scraper Baidu, você poderá obter enormes bases de links prontos para uso posterior. Você pode usar consultas da mesma forma que as digita na barra de pesquisa do Bing, incluindo operadores de pesquisa (filetype, site, intitle).
A funcionalidade do A-Parser permite salvar as configurações de extração de dados do scraper Baidu para uso futuro (predefinições), definir cronogramas de extração de dados e muito mais. Você pode usar a multiplicação automática de consultas, substituição de subconsultas a partir de arquivos, combinação de caracteres alfanuméricos e listas para obter o máximo possível de resultados.
No scraper Baidu, a preservação dos resultados é possível no formato e estrutura que você necessita, graças ao poderoso motor de modelos integrado Template Toolkit que permite aplicar lógica adicional aos resultados e exibir dados em vários formatos, incluindo JSON, SQL e CSV.
Casos de uso do scraper
🔗 Extração de dados de links completos do Baidu
Este recurso demonstra como realizar a extração de dados de links completos
🔗 Sugestões do Baidu
Extração de dados multinível de sugestões do Baidu
🔗 JS Scraper JS::SE::Baidu::Suggest
Criação de JS Scrapers. Obtenção de sugestões do Baidu
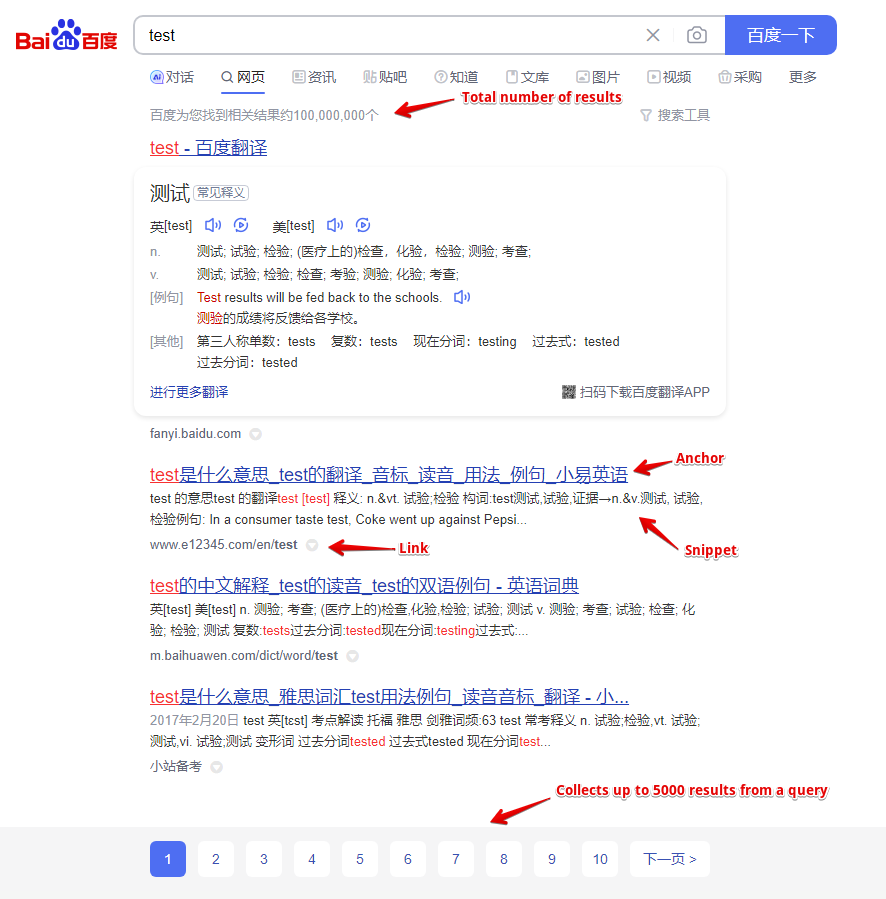
Dados coletados
- Links
- Snippets
- Âncoras
- Número total de resultados
- Lista de palavras relacionadas
- Número de páginas de resultados
Recursos
- Coleta até 5000 resultados por consulta
- Suporte para todos os operadores de pesquisa do Baidu (filetype:, site:, intitle:).
- Coleta resultados por consulta e palavras-chave relacionadas
- Conversão de links curtos em links completos (opção Get full links)
Casos de uso
- Coleta de bases de links - para A-Poster, XRumer, AllSubmitter, etc.
- Avaliação da concorrência para palavras-chave
- Verificação de indexação de sites
- Coleta de páginas que contêm palavras-chave específicas no título da página
Consultas
Como consultas, é necessário indicar frases de pesquisa, por exemplo:
test
site:www.baidu.com
百度产品大全
intitle:scraper
Substituições de consultas
Você pode usar macros integradas para multiplicar consultas, por exemplo, se quisermos obter uma base muito grande de fóruns, indicaremos algumas consultas principais em diferentes idiomas:
forum
fórum
foro
论坛
No formato de consultas, indicaremos a permutação de caracteres de a a zzzz, este método permite rotacionar ao máximo os resultados de busca e obter muitos novos resultados únicos:
$query {az:a:zzzz}
Esta macro criará 475254 consultas adicionais para cada consulta de pesquisa inicial, o que resultará em um total de 4 x 475254 = 1901016 consultas de pesquisa, um número impressionante, mas que não é problema para o A-Parser. Com uma velocidade de 2000 consultas por minuto, tal tarefa será processada em apenas 16 horas.
Uso de operadores
Você pode usar operadores de pesquisa no formato da consulta, desta forma ele será automaticamente adicionado a cada consulta da sua lista:
site:$query
Exemplos de saída de resultados
O A-Parser suporta formatação flexível de resultados graças ao motor de modelos integrado Template Toolkit, o que permite exibir resultados de forma arbitrária, bem como estruturada, por exemplo, CSV ou JSON
Exportação de lista de links
Da mesma forma que no SE::Google.
Links + âncoras + snippets com exibição de posição
Da mesma forma que no SE::Google.
Exibição de links, âncoras e snippets em tabela CSV
Da mesma forma que no SE::Google.
Salvando palavras-chave relacionadas
Da mesma forma que no SE::Google.
Concorrência de palavras-chave
Da mesma forma que no SE::Google.
Verificação de indexação de links
Da mesma forma que no SE::Google.
Salvando em formato SQL
Da mesma forma que no SE::Google.
Dump de resultados em JSON
Da mesma forma que no SE::Google.
Processamento de resultados
O A-Parser permite processar os resultados diretamente durante a extração de dados, nesta seção apresentamos os casos mais populares para o scraper Baidu
Desduplicação de links
Da mesma forma que no SE::Google.
Desduplicação de links por domínio
Da mesma forma que no SE::Google.
Extração de domínios
Da mesma forma que no SE::Google.
Remoção de tags de âncoras e snippets
Da mesma forma que no SE::Google.
Filtragem de links por ocorrência
Da mesma forma que no SE::Google.
Configurações possíveis
| Nome do parâmetro | Valor padrão | Descrição |
|---|---|---|
| Pages count | 5 | Número de páginas para extração de dados (de 1 a 100) |
| Links per page | 50 | Número de links nos resultados para cada página (10 / 20 / 50) |
| Get full links | ☐ | Conversão de links curtos em completos (desativado por padrão) |