Net::HTTP - Scraper básico universal com suporte para extração de dados em múltiplas páginas e contorno de CloudFlare
Visão geral do scraper
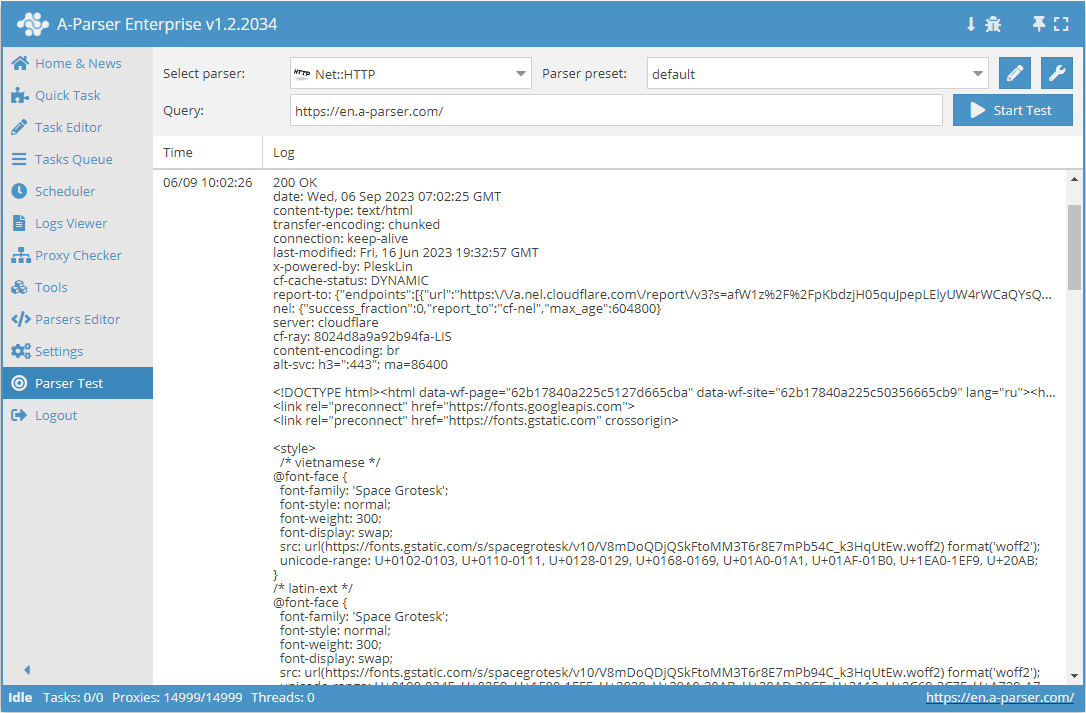
 Net::HTTP – é um scraper universal que permite resolver a maioria das tarefas não padronizadas. Pode ser usado como base para a extração de dados de conteúdo arbitrário de quaisquer sites. Permite baixar o código da página através de um link, suporta extração de dados de múltiplas páginas (navegação por páginas), trabalho automático com proxy, e permite verificar o sucesso da resposta pelo código ou pelo conteúdo da página.
Net::HTTP – é um scraper universal que permite resolver a maioria das tarefas não padronizadas. Pode ser usado como base para a extração de dados de conteúdo arbitrário de quaisquer sites. Permite baixar o código da página através de um link, suporta extração de dados de múltiplas páginas (navegação por páginas), trabalho automático com proxy, e permite verificar o sucesso da resposta pelo código ou pelo conteúdo da página.Casos de uso do scraper
🔗 Leilão de domínios REG.RU
Extração de dados do leilão de domínios expirando com possibilidade de filtragem
🔗 Dados do certificado SSL
Extração de dados do certificado SSL de domínios do site leaderssl.ru
🔗 Extração de dados do recurso Booking.com
Obtenção de resultados de busca de apartamentos e hotéis no site
🔗 Coleta de características de produtos
Exemplo de extração de dados de uma quantidade desconhecida de características de produtos
🔗 Extração de dados da base de filmes do IMDB
Obtém dados sobre cada filme e os grava no resultado
🔗 Verificação de presença de HTTPS
O preset verifica a presença de HTTPS no site
Dados coletados
- Conteúdo
- Código de resposta do servidor
- Descrição da resposta do servidor
- Cabeçalhos de resposta do servidor
- Proxies utilizados na requisição
- Array com todas as páginas coletadas (utilizado quando a opção Use Pages está ativa)
Funcionalidades
- Extração de dados multipáginas (navegação por páginas)
- Trabalho automático com proxies
- Verificação de resposta bem-sucedida por código ou por conteúdo da página
- Suporte a compressão gzip/deflate/brotli
- Detecção e conversão de codificações de sites para UTF-8
- Contorno de proteção CloudFlare
- Escolha do motor (HTTP ou Chrome)
- Opção Check content – executa a expressão regular especificada na página obtida. Se a expressão não for correspondida, a página será carregada novamente com outro proxy.
- Opção Use Pages – permite percorrer um número especificado de páginas com um passo determinado. A variável
$pagenumcontém o número da página atual durante a iteração. - Opção Check next page – é necessário especificar uma expressão regular que extrairá o link para a próxima página (geralmente o botão "Próximo"), se existir. A transição entre páginas ocorre dentro do limite especificado (0 - sem limites).
- Opção Page as new query – a transição para a próxima página ocorre em uma nova requisição. Permite remover a restrição do número de páginas para transição.
Opções de uso
- Download de conteúdo
- Download de imagens
- Verificação do código de resposta do servidor
- Verificação da presença de HTTPS
- Verificação da presença de redirecionamentos
- Listagem de URLs de redirecionamento
- Obtenção do tamanho da página
- Coleta de meta tags
- Extração de dados do código-fonte da página e/ou cabeçalhos
Consultas
Como consultas, é necessário indicar links para as páginas, por exemplo:
http://lenta.ru/
http://a-parser.com/pages/reviews/
Exemplos de formatos de saída
O A-Parser suporta formatação flexível de resultados graças ao motor de modelos integrado Template Toolkit, o que permite exibir resultados em formato livre, bem como estruturado, como CSV ou JSON
Saída de conteúdo
Formato do resultado:
$data
Exemplo de resultado:
<!DOCTYPE html><html id="XenForo" lang="ru-RU" dir="LTR" class="Public NoJs uix_javascriptNeedsInit LoggedOut Sidebar Responsive pageIsLtr hasTabLinks hasSearch is-sidebarOpen hasRightSidebar is-setWidth navStyle_0 pageStyle_0 hasFlexbox" xmlns:fb="http://www.facebook.com/2008/fbml">
<head>
<!-- Google Tag Manager -->
<!-- End Google Tag Manager -->
<meta charset="utf-8" />
<meta http-equiv="X-UA-Compatible" content="IE=Edge,chrome=1" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<base href="https://a-parser.com/" />
<title>A-Parser - scraper para profissionais de SEO</title>
<noscript><style>.JsOnly, .jsOnly { display: none !important; }</style></noscript>
<link rel="stylesheet" href="css.php?css=xenforo,form,public,parser_icons&style=9&dir=LTR&d=1612857138" />
<link rel="stylesheet" href="css.php?css=facebook,google,login_bar,moderator_bar,nat_public_css,node_category,node_forum,node_list,notices,panel_scroller,resource_list_mini,sidebar_share_page,thread_list_simple,twitter,uix_extendedFooter&style=9&dir=LTR&d=1612857138" />
<link rel="stylesheet" href="css.php?css=uix,uix_style&style=9&dir=LTR&d=1612857138" />
Código de resposta do servidor
Formato do resultado:
$code
Exemplo de resultado:
200
O formato do resultado [% response.Redirects.0.Status || code %] permite exibir o status 301, se houver redirecionamentos na requisição.
Obtenção de dados sobre a requisição
A variável $response ajuda a obter informações sobre a requisição e a resposta do servidor
Formato do resultado:
$response.json\n
Exemplo de resultado:
{
"Time": 3.414,
"connection": "keep-alive",
"Decode": "Decode from utf-8(meta charset)",
"cache-control": "max-age=3600,public",
"last-modified": "Tue, 18 May 2021 12:42:56 GMT",
"transfer-encoding": "chunked",
"date": "Thu, 27 May 2021 14:18:42 GMT",
"Status": 200,
"content-encoding": "gzip",
"Body-Length-Decoded": 1507378,
"Reason": "OK",
"Proxy": "http://51.255.55.144:25302",
"content-type": "text/html",
"Redirects": [],
"server": "nginx",
"Request-Raw": "GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n",
"URI": "https://a-parser.com/",
"HTTPVersion": "1.1",
"Body-Length": 299312,
"Decode-Mode": "auto-html",
"etag": "W/\"60a3b650-170032\"",
"Decode-Time": 0.003,
"IP": "remote",
"expires": "Thu, 27 May 2021 15:18:42 GMT"
}
Obtenção de redirecionamentos
Consulta:
https://google.it
Formato do resultado:
$response.Redirects.0.URI -> $response.URI
Exemplo de resultado:
https://google.it/ -> https://www.google.it/
JSON com redirecionamentos
Formato do resultado:
$response.Redirects.json
Exemplo de resultado:
[{"x-powered-by":"PleskLin","connection":"keep-alive","URI":"http://a-parser.com/","location":"https://a-parser.com/","date":"Thu, 18 Feb 2021 09:16:36 GMT","HTTPVersion":"1.1","Status":301,"content-length":"162","Reason":"Moved Permanently","Proxy":"socks5://51.255.55.144:29683","content-type":"text/html","IP":"remote","server":"nginx","Request-Raw":"GET / HTTP/1.1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\nAccept-Encoding: gzip, deflate, br\r\nAccept-Language: en-US,en;q=0.9\r\nConnection: keep-alive\r\nHost: a-parser.com\r\nUpgrade-Insecure-Requests: 1\r\nUser-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)\r\n\r\n"}]
Exibição do status da resposta do servidor
Formato do resultado:
$reason
Exemplo de resultado:
OK
Tempo de resposta do servidor
Formato do resultado:
$response.Time
Exemplo de resultado:
1.457
Obtenção do tamanho da página
Como exemplo, o tamanho é apresentado em três variantes diferentes.
Formato do resultado:
[% "data-length: " _ data.length _ "\n";
"Body-Length: " _ response.${'Body-Length'} _ "\n";
"Body-Length-Decoded: " _ response.${'Body-Length-Decoded'} _ "\n" %]
Exemplo de resultado:
data-length: 70257
Body-Length: 23167
Body-Length-Decoded: 75868
Processamento de resultados
O A-Parser permite processar resultados diretamente durante a extração de dados; nesta seção, apresentamos os casos mais populares para o scraper Net::HTTP
Extração de cabeçalhos H1-H6
Adicionar regex (opção Parse custom results (Usar regex)) <(h\d+)[^>]+>(.+?)<\/h\d+>, no campo "Parse result" selecionar $pages.$i.data - Page content, no campo ao lado da regex selecionar os modificadores sg. Como tipo de resultado, um array será selecionado automaticamente. No campo "Name" indicar headers, depois em "$1 to" indicar tag, clicar no

content. No formato geral do resultado, definir a saída $p1.headers.format('$tag - $content\n').Baixar exemplo
Como importar um exemplo para o A-Parser
eJxtVNuO2jAQ/RVkIS2IW3loH6IVFYuK2ooSlmWfIJUsMgR3HTu1HboI8e+dcUIC
tE+Jj+ccn7nYJ+a4fbMLAxacZcH6xDL/zwI2BxcEX1erRWOrpYStEypp7Ie9/SfW
ZRk3Fgwx1nUg4jHseC4d656YO2aAMtvcOp0uwXqYmeInWKNEApYo3HEW0U4C70h4
bO03m7jTXv8cRZ1Rq9/53H7cbAYeHLEyblWI26SSLBFuDD8i6L9znhK2Bx6T2Uso
2cbEibvVyoFyLDpHUbU91SblVIJmNuyX5P7Og62HJhIbvUazZG426qFdK7/wA6w0
UndCQg1PcVWaaWK+QLsXxXbfvVNleBwLJ7TisjifXNaeXpX4nRNfaYzFXyPATo1O
EXLgBQg8XryvWdOvqbK55z4XHBbsuLTQZRatTjkaie93hAPDnTZhRn4QPzGtxlLO
4ACyDvP6T7mQVJ/xDknfSuL/Q8J/NM5VetdHHcD8MeihUvGrp/BHzYr1TCeXYkiR
CodrO9G5orZ9QPANIKtqNqewVBuojimVy9Nx/jNQMUbWLRtnNXSTxk1bbkGciZ1I
QkzAiBgukbla4SUL1USnmQTKS+VSYlssLOvxGNuyDbSoDd6TJ/4ItFXdNOa0lvb7
S2E1MwLH7yMZTLGS16eWklsu5etydr1DRLylWai+GHPXPj8YbO9cZoPBgPeKm9/f
6nRA9weHOdE4ZpjqOarehepBOV29DsHpjK37ZRdFDOVJEYhhwSz2hQXD81+VjpX2
Coleta de meta tags
Adicione uma regex (opção Parse custom results (Utilizar regex)) (<meta[^>]+>), no campo "Parse result" selecione $pages.$i.data - Page content, no campo ao lado da regex selecione o modificador g. O tipo de resultado será automaticamente selecionado como array. No campo "Name" indique meta, em "$1 para" indique item. No Formato do resultado utilize $p1.meta.format('$item\n').
Baixar exemplo
Como importar um exemplo para o A-Parser
eJxtVO9v2jAQ/V8spBatg/XDvkRTJYqEtokRRtNPNJMscsk8/Gu2Q0FR/vfeJSGB
bp/ie37v3Z3PTsUC93u/duAheBZtK2abNYtYBjkvZWB3zHLnwdH2lq0gRNHXJFkj
3jMqFk4WULMrfTBqA74VunYRbdGiAE8SHjhLaaeAIwpuvygIfPvrIf3wMGYdnrRm
Re/QAdw5fkKw+a64IozkPY9KZCKAYmmdpj26ME5xamlk7yckmOQNcnszIvLLi74Z
Dx5P/ACJQXYuJAzwAqMu5wi7ANo9+4wn4Uj98iwTQRjNZZuS6hnKeNbib0l6bZCL
SyfAL5xRCAVoDAg8ncvdslET03mVjfZnq2FRzqWHO+ax1AXHQrL3O9iX48G42FI9
iFfM6JmUSziAHGiN/2MpZIbzneUo+tYJ/0+J//Go+/YuUx3AvTqsoXdposf4x6DK
zNIU58OQQomAsZ+bUtOkPiG4B7D9ma2IpoyDPk3n3GXHK2xBZ8gcRjazA3TVxtVY
rsGd0bkoYmzAiQzOzFIn+E5iPTfKSqC+dCkljsXDZrgeM9+NgYKhwPfieZPi6oUF
Y6T//tSWap3A6/eZClR4kpdZO8sdl/J5s7zcYcOVwuB3CNZH0yn/2L7dyc6o6avY
i6nQGRynjDwCFAZvF3ZYp/0j738F1cVTj6oaJ/bHr1sOtUcMxPCcPI6DRff1GzD1
gDE=
Opções de navegação por paginação
Uso do Use pages
Use pages. Esta função permite percorrer a paginação indicando antecipadamente um número conhecido de páginas.
Como exemplo, vamos pegar uma das categorias no site do catálogo de produtos https://www.proball.ru/catalog/myachi/. No topo e no rodapé vemos o painel de paginação. Ao clicar nos ícones com os números das páginas, é possível ver na barra do navegador como o parâmetro com o número da página é passado no final da requisição:
https://www.proball.ru/catalog/myachi/?PAGEN_1=1
Use pages é uma espécie de contador que, na verdade, substitui na variável $pagenum os números em ordem, aumentando-os pelo valor que especificarmos
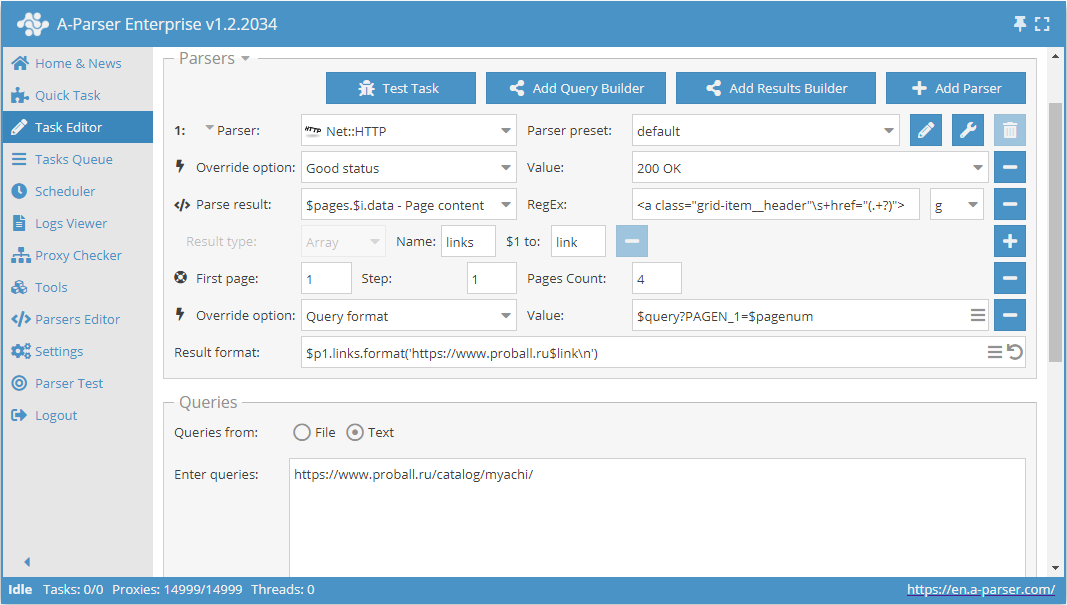
Como visto na captura de tela, no formato de consulta do scraper, a variável $pagenum é usada no local apropriado.
A função Use pages percorrerá e substituirá na consulta todos os valores; na prática, obteremos os links para a requisição
https://www.proball.ru/catalog/myachi/?PAGEN_1=$pagenum
onde, em vez da variável $pagenum, será inserido o número da página, começando de 1 até 4 com passo 1.
Dessa forma, obtém-se a navegação pelas páginas do intervalo desejado. Nisto reside a limitação deste método - é necessário saber antecipadamente a quantidade de páginas existentes na paginação. Obviamente, ao extrair dados de várias categorias simultaneamente, a quantidade de páginas será diferente em cada uma e, como solução, podemos simplesmente indicar uma quantidade maior de páginas presumidas. Mas isso não é totalmente correto, por isso existe uma solução mais otimizada, que será discutida a seguir
Baixar exemplo
eJx1VNtu2kAQ/ZVqhJSgUAhV+2I1jSgqvSgCmtAnjKKtPTZu1rubvXAR8r931jY2
pOmTvWfPXM7M7BzAMvNk5hoNWgPB8gCq/IcAnME5SxF6oJg2qP31EqZog+DbYjEn
PMaEOW6hdwC7V0g2coNaZ7E3ymI6p1LGY1meN4w7oizfXV+vitYicsbK/B5N6Qh0
9RMsKWiKxgdhlsHK36S4I4OP7E3EmTE3IaQU6m1mMX98XCOLUYcQhuZqrTGh28v+
1W03hE9Q2y6qgGkTpQaY1mxPYPmdstxjPBNPpiF65SUEp5lLZTMpzFFqXS7TSoWh
9xrHmecxDsGhEvVgUdW3/hxJJ3y930NR/L+Szw71PpE6Z/YkQqeEb+ejr1+mj8Ob
jvcnXA7FatUkP6mMiKyG/VJYv/JzebG2VplgMNhut32l5W/GeV+7jieFobjothV4
YBtcSHKSZBxbeEKnumQdahT626P3bj8ym7MKVJn4arbZ/RLZcylFSOJ6ORmaiZY5
QRZ3tgb3RxXLWrMfCVfa/qxsIEgYN9gDQ6lOGCUSv7yhUdHMSj2rO0cNkWLE+R1u
kLe00v9nl3GaKDNKyOh7bfg6ZfaPj6KRdxqKOrrVlENLiuWdTI/anxBVU42pR3Kp
sXFQR6790otVKPxgtM0YqRY6S/Cs4OdgJEWSpbN62I5MJxa0FmZiLHPF0WcsHOc9
P+P3beNHpi6wP7QJvjQelyEorWZdgJWSmx8PVapKZzRYH5rmE/r6XA4iWgVcpoN8
z6J1NiBbQjCVNA1+c5XjQi9Hl/J6gDvFRIxUEasdFqti1ayyZuEdThZacKAHCH/M
vOJ4VZ5BGJXHUBcgGBZ/AXULzRU=
Uso do Check next page
Check next page - esta é outra função que permite organizar a navegação pela paginação. A particularidade de seu uso é que, para passar para a próxima página, deve-se usar uma expressão regular que retornará o link para a próxima página. Este é um método mais conveniente e frequentemente aplicado. No entanto, não será possível aplicá-lo para https://www.proball.ru/catalog/myachi/, pois não há links para as próximas páginas no código. Os links lá são gerados por script. Portanto, usaremos como exemplo o site http://www.imdb.com/search/name?gender=female. Aqui há paginação tanto no início quanto no final da lista. Ao analisar o código-fonte, pode-se notar a presença de um link que permite navegar para a próxima página:
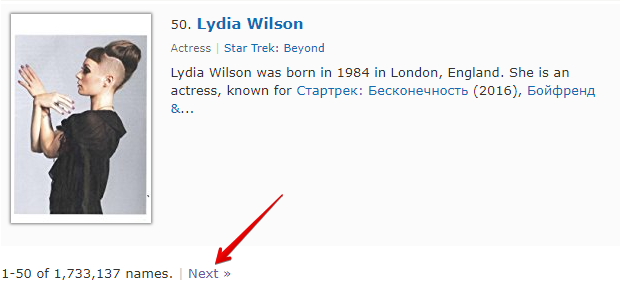
- no campo Next page RegEx, escreveremos a expressão regular
- no campo Limit (Limite), indicaremos a quantidade de páginas que devem ser percorridas
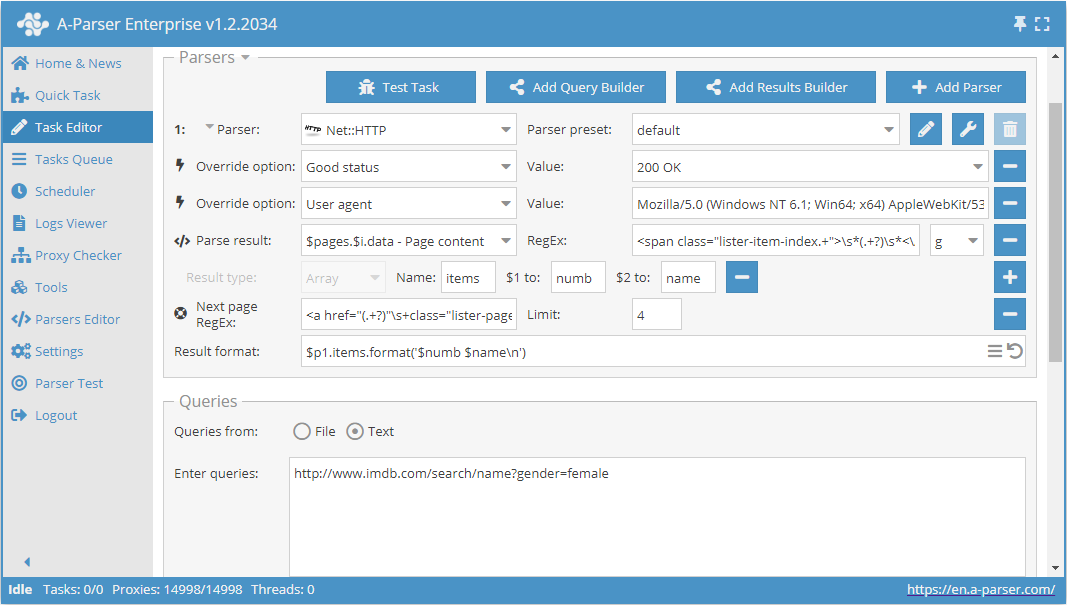
No exemplo, está indicado 4. Ao indicar o limite, definimos quantas páginas o scraper deve percorrer. No nosso caso, serão percorridas 5 páginas, pois a contagem começa em 0. Se indicar o limite 0, o scraper funcionará até percorrer todas as páginas, independentemente da quantidade. Isso é muito útil quando se precisa extrair todos os resultados de todas as páginas
Baixar exemplo
eJx1VGFT2kAQ/SuZG2aUggGq4DSijnXG2qpAlY4fCM6cZANXL7n07iJYhv/e3RAS
sO0XuH3ZvX1vd2+XzHLzYgYaDFjDvNGSJdmZeWwyg8lLDxZ2wKfA6izh2oAmpxHr
gfW86+FwgHgAIU+lZfUls28JYKR6Ba1FQEEiQHuqVHCpMvuVyxRdRh+bzfHq/xEp
ZjrAtLEtY9id+i2k5I2223T2H0UcqLlxekOn47ZOHLQ7RyfOonNUdS6SRMIjPN8I
22gfHruHHWf/5np4d1t3pHgB5wsKU1XncqZVBI32J7fpHjaPW26r1XYeeMi1yMPY
FsVJaqyK7sFkWpleH7wR1mUKhurALWdj+jKFBQZ0TcJjZyK5Mac+k8JY1CQsRAdI
HRZuzWdnvm8+7Lu18yodur7foBhCa10+ejob19Yeo6fueMuJn7E8zXDNbVoQygGu
NX9DMPvv8YgwSm0KR+oji9PoGZGYHHbakVihYrPpxvtJ2DSky52ZhhDVrTUwIv5O
MFXnIMZYh34y02fELAgEJeGSecvdDLciEjSAR2y1Go8LwldKR5zwStJyMzFumEH7
exUS4lRIh+/He9VS5QN/haHCoFBIKOErtPKyVLBvQF83t1Vdu7A7DNeZqWIlmx+x
+JUVIVboi0ctwFzhQCFkIbuAwLcN6xGrZDZNSJrFfl/HMC/k0kCdGaR6xZFI8P4L
itXcKt3P24IFU/GFlLfwCrJ0y+7/nAoZ4DO9CDHoax74b5f+X3esCnnbqfBtzjVy
KJ0CdaumG+0vAElRjR4hkdJQXJBnzu/FTZNATENVNgOfawHtENwp+C44UXEopv18
bWw803iI66wfX6oINwAxjlMp67RO7svGX5i8wGSUBN8HX2YpkFax4JhVSppvD2uq
iRY4WO2i+YjOrE28RmM+n7siCp7diYoaBriezBo0m+e40FDCaQgRz6ZxgqM3VTgU
tHizqaHhMZQKFrgJAsCyWJ3CarwaFxu42NbLrT3sLVfYmJ9msPYhaeSBGNbIYCuY
11r9ASIaBUM=
Como mencionado anteriormente, há a possibilidade de limitar dinamicamente a quantidade de páginas no Use pages. Para isso, deve-se usar conjuntamente Use pages e Check next page. Vamos complementar o exemplo que foi analisado na descrição do Use pages e adicionar a ele a função Check next page:
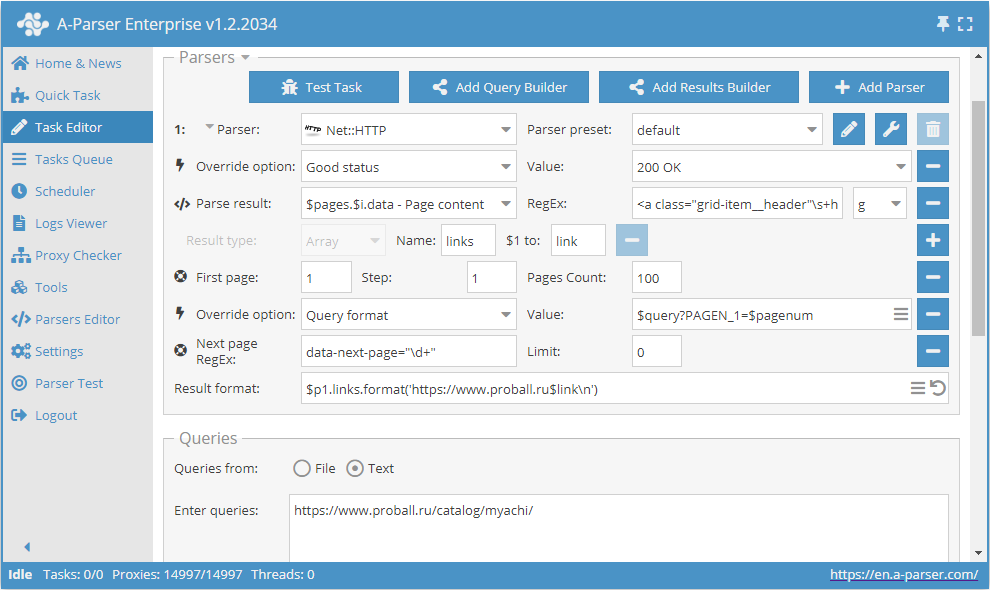
Essas duas funções em conjunto trabalham da seguinte forma: Use pages garante a navegação pelas páginas, e Check next page verifica se a próxima existe. Assim que o Check next page não encontrar a próxima página, a extração dessa categoria será interrompida, sem esperar percorrer toda a quantidade indicada no Use pages. Combinando essas funções, adicionamos eficiência ao trabalho do scraper, economizando tempo e recursos
Baixar exemplo
eJx1VNtuGjEQ/ZXKQkqiEC6V+rJqGtGo9KIIaEKfWBS5u7OLi9d2bC8EIf69M3uF
XJ52fTyXM2fGs2eeu7WbWXDgHQsWe2aKfxaw3MGMp8C6zHDrwNL1gk3AB8GP+XyG
eAwJz6Vn3T3zOwPoozdgrYjJScR4TrWOb3Vx3nCZo8ni42CwPLQeUe68zu7BFYGY
LX+CBSZNwVES7jlb0k0Kz+jwmX+IJHfuOmQpproSHrLHxxXwGGzIwtBdriwkeHve
u7y5CNkXVvnOy4Rpk6UCuLV8h2DxnfCMMCnU2jWGVHkBsWPm2nihlatLreRybals
SFHjWJAdlyzYl0U9eDDVLZ0jnSvSezgYsMPhfS2fcrC7RNuM+6McnQK+mY2+f5s8
Dq87FFHlGXufaLSCaD2BZ191t45EQl8pxK8oxjVpGV+G7FUNJ/53IhNEnqgvl41g
45Im0jPDXiFmr2R+frby3rig399utz1j9V8uZc/mHTIKQ3V20ar+wDcw1xgkERJa
eIynqk0d5Ax0W0e/6EVuc8K4ZEIdbNn9UeKpKFlptCUBBbix1RlCHgurwF1dxaJS
mcYwL3x/lz4sSLh00GUOqY45Eolf3uB4Wu61nVZNQAG1Gkl5BxuQrVkR/2suJE6x
GyXo9LNyfNtk+irGoSnvOBXO0NYih9Yo1nc6rWtfA5hGjQkhmbbQBKgyV3FxSxhQ
NEJtM0amhU4Ingh+CkZaJSKdVuNdW+Zqjqtoqm51ZiQQY5VL2aV3dd82fuQqgenQ
EnzpfFukoKGuVxTzWkv366GkaqzAwfrUNB/Rt+eyH+GrkDrtZzserUQffRGBVOM0
0LYsxgWfmC3K6zJ4NlzFgIoMD8vDstmdzYbdH23QYI/vnf1zs9KGSiILxFAbhy2g
KP8Byg3yDQ==
Uso de macros de substituição
Macros de substituição permitem realizar a substituição sequencial de valores de um intervalo especificado
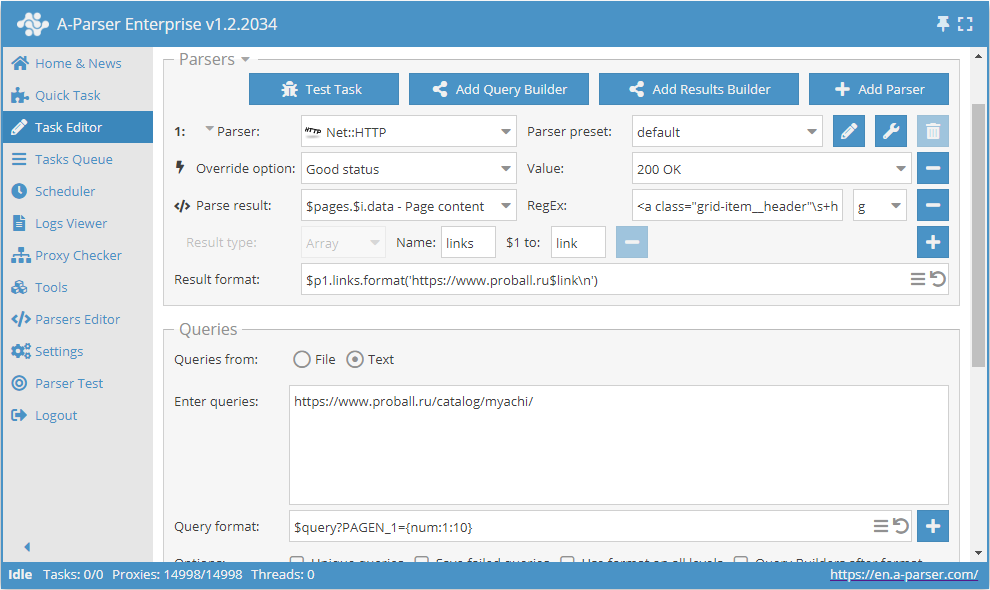
Este preset funcionará da seguinte maneira. Ao indicar no formato da consulta o modelo:
$query?PAGEN_1={num:1:10}
adicionamos a substituição de valores de 1 before 10 (qualquer intervalo pode ser especificado) na própria consulta. Dessa forma, obtemos consultas que garantem a navegação pela quantidade desejada de páginas, do tipo:
https://www.proball.ru/catalog/myachi/?PAGEN_1=1
https://www.proball.ru/catalog/myachi/?PAGEN_1=2
...
https://www.proball.ru/catalog/myachi/?PAGEN_1=10
O uso de macros de substituição para navegar pela paginação é semelhante à função Use pages e possui as mesmas limitações, ou seja, é necessário especificar um intervalo concreto de valores. A vantagem deste método é que, através das macros de substituição, é possível inserir diferentes valores, tanto numéricos quanto textuais, por exemplo, palavras ou expressões. Assim, podemos inserir partes necessárias nas consultas de forma mais flexível ou formar as próprias consultas a partir de partes que estarão localizadas em arquivos diferentes, se a tarefa assim o exigir
Baixar exemplo
eJxtVFtP2zAU/iuTVQkQXUsn7SUaQx2iu4i1HXRPTYW85CT1cGzPx+lFUf47x26a
AOMp8Xcu3+dzccUcx0ecW0BwyKJlxUz4ZxH7yROr8WbH+sxwi2C9fcmm4KLo22Ix
JzyFjJfSsX7F3N4ABekNWCtSIKNI6ZxrnV7rcN5wWZLL8sPFxaruIpISnS7uAEMi
Zg8/0ZJIc0BPwh1nK2/JYUcBn/i7RHLEy5jlRPVeOCgeHtbAU7Axi2M8X1vIyHo6
OL86i9ln1sQuDoR5y9IA3Fq+JzB8p7zwmBTqEVtHf/MAsVW9WrXoRNuC+1L1zGgQ
IgZZgE5P1s4ZjIbD7XY7MFb/4VIObNnzTnGsTs661Pd8AwtNSTIhoYMndGq09KgC
4K3H7GeDBDdecJoKJ7Ti8qDEy+zU/Vbiny84U5p86dcKwInVBUEOdq4B98dbLFkv
nK/m468304fRZaXKIhpFo4val78M6X4d0rAo4xKhz5DUTzhpS19bqC2WO21nxksk
vGJajaW8hQ3Izi1QfimFpO7hOKOg703g2y6z/3LU7Y2fU9Ecbi1p6JxSfavzYzke
AUxboKlHCm2hTdAwN3lpPQwoP85df8amg14IfNGDl2CiVSbyWbMiR89SLWgHZ+pa
F0aCV6xKKangCHfdLIyxKbA/dAJfB18HCpLVriZzWkv8cX+QaqygWfvYzgOhb4/q
MKG1kzofFnuerMWQYgmBXNt9eCbCBPlBQs8BO8NVClQPZ0uoaUvaR6N9W6pnT0dU
1dSRvzg/+Pg7eQ/CqDhIPWDRqH4C36ybyg==
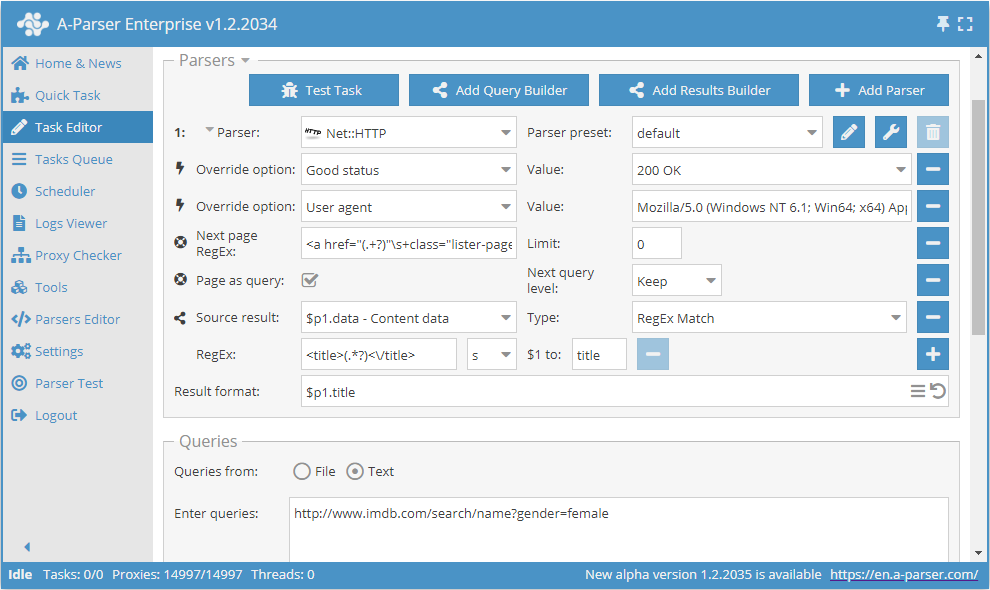
Uso do Page as query
Para reduzir o consumo de memória, a lógica pode ser definida com a ajuda da opção Page as query. Ao ativá-la, as funções Check next page e Use pages colocarão cada página seguinte nas consultas como uma consulta independente, não acumulando assim o seu conteúdo na memória. Page as query permite também definir se deve aumentar o nível da consulta Increase (semelhante ao funcionamento da ferramenta tools.query.add), ou não Keep
Baixar exemplo
eJx1VNty2jAQ/RWPJg/QEts0gUydpBnCDE0bAiQhkwfgQbHXoCJbriQDKcO/dyXM
tc0LeFd7OXv2siSaqqnqSVCgFQkGS5LZbxKQHh1DQ3Vg/piDfCcVklGpQBqrAemA
DoK7fr+H+ghimnNNKkui3zNAVzEDKVkE+MgilMdCRE1h5RnlOZoMvvj+aPWxR46Z
ThFAqnc+5EH8YZxTr+b6TumVpZGYK6fTd+pu9dJBuX5+6Szq52WnkWUcXuHtnmmv
dnbhntWd0v1d/6FdcTibgvMdwqkoO82JFAl4ta+u7575F1W3Wq05zzSmkhVuZB9i
pplI1QZhOMEgHVhow9MeyCvqTCTE10NScj/flIdkOFSfQ06VQhVnSmNhGbqcpujr
mB8rDgnGoFHETBLKSbA8zNBmCTNd8cnqY0zZccsKUFrmcBx9CpBZszbMADX+ajUa
VQh2H3upWkIm1OQ7yaquZpqbEou3ZzqDvsC3mO2rWyh1aGJgnURUg3l1YxunVHb1
Qh8UuE5ghmmX9CVlvy2HqUBb/JQMVAt7hCoNNoBRvm/ADciJlQmGyK3v49qHBDHl
CktWCLVFEUh0/MKwD1QL2S0YREZE2uDcsrEzs/Fvc8YjnPxGjE4/Csf/m3T/ibHa
lrefCsd9LhHDNoqVbrsPO69ItMUYK4/esG5u2o+yaoo8Xc9BxbZwy1nHcJYICds0
ReQiO+54BqmZkl3LcE+2qoMyDtqyp1wSJXIZmgX2ESHV1HBfDKOEMSxscPOPm2Dn
5lvJ/XRTvhoOvbW4MeivnczsamF6uZ6y0QoDhiKN2bhb3IQNmjzt47Hqpk2R4Hob
7tKc84q5FU+7EWyootVG2JFw7Ny0KQy9m+uFMARXP5/XdGSSIaqaAZtgt/azFiFD
yvnLU3v/hezGFoWJ1lngefP53GVJ9OaGIvEUUBlOvBT35AavG9J6HUNC7R6FuDRj
geOM5RoWinu7Pc7LvasbLPEMkF+qt7YxtRoL1CFpCvtPgurqL0u6AK8=
Configurações possíveis
| Nome do parâmetro | Valor padrão | Descrição |
|---|---|---|
| Good status | All | Escolha de qual resposta do servidor será considerada bem-sucedida. Se durante a extração houver outra resposta do servidor, a requisição será repetida com outro proxy |
| Good code RegEx | Possibilidade de especificar uma expressão regular para verificar o código de resposta | |
| Ban Proxy Code RegEx | Possibilidade de banir o proxy temporariamente (Proxy ban time) com base no código de resposta do servidor | |
| Method | GET | Método da requisição |
| POST body | Conteúdo para enviar ao servidor ao usar o método POST. Suporta as variáveis $query – URL da requisição, $query.orig – consulta original e $pagenum - número da página ao usar a opção Use Pages. | |
| Cookies | Possibilidade de especificar cookies para a requisição. | |
| User agent | _O user-agent da versão atual do Chrome é inserido automaticamente_ | Cabeçalho User-Agent ao solicitar páginas |
| Additional headers | Possibilidade de especificar cabeçalhos de requisição arbitrários com suporte às funcionalidades do motor de modelos e uso de variáveis do construtor de consultas | |
| Read only headers | ☐ | Ler apenas cabeçalhos. Em alguns casos, permite economizar tráfego se não houver necessidade de processar o conteúdo |
| Detect charset on content | ☐ | Reconhecer a codificação com base no conteúdo da página |
| Emulate browser headers | ☑ | Emular cabeçalhos de navegador |
| Max redirects count | 7 | Quantidade máxima de redirecionamentos que o scraper seguirá |
| Follow common redirects | ☑ | Permite fazer redirecionamentos http <-> https e www.domain <-> domain dentro do mesmo domínio, ignorando o limite Max redirects count |
| Max cookies count | 16 | Número máximo de cookies para salvar |
| Engine | HTTP (Fast, JavaScript Disabled) | Permite escolher o motor HTTP (mais rápido, sem JavaScript) ou Chrome (mais lento, JavaScript ativado) |
| Chrome Headless | ☐ | Se a opção estiver ativada, o navegador não será exibido |
| Chrome DevTools | ☐ | Permite usar ferramentas de depuração do Chromium |
| Chrome Log Proxy connections | ☐ | Se a opção estiver ativada, informações sobre as conexões do chrome serão exibidas no log |
| Chrome Wait Until | networkidle2 | Define quando a página é considerada carregada. Mais detalhes sobre os valores. |
| Use HTTP/2 transport | ☐ | Define se deve usar HTTP/2 em vez de HTTP/1.1. Alguns sites banem imediatamente se usar HTTP/1.1, enquanto outros, ao contrário, não funcionam via HTTP/2. |
| Try use HTTP/1.1 for Protocol error | ☑ | Indica ao scraper para repetir a requisição com HTTP/1.1 se o HTTP/2 estava ativado e ocorreu um erro de protocolo (ou seja, se o site não funciona via HTTP/2) |
| Don't verify TLS certs | ☐ | Desativação da validação de certificados TLS |
| Randomize TLS Fingerprint | ☐ | Esta opção permite contornar o banimento de sites por impressão digital TLS |
| Bypass CloudFlare with Chrome | ☐ | Contorno automático da verificação CloudFlare |
| Bypass CloudFlare with Chrome Max Pages | 20 | Quantidade máx. de páginas ao contornar CF via Chrome |
| Bypass CloudFlare with Chrome Headless | ☑ | Se a opção estiver ativada, o navegador não será exibido durante o contorno do CF via Chrome |