SE::DuckDuckGo::Position - Verificação de posições de sites por palavras-chave no DuckDuckGo
Visão geral do scraper
Scraper de verificação de posições de sites por palavras-chave no DuckDuckGo. Graças ao scraper SE::DuckDuckGo::Position, você poderá verificar automaticamente as posições nos resultados de busca do DuckDuckGo usando suas próprias bases de domínios. Utilizando o scraper SE::DuckDuckGo::Position, é possível determinar a posição de um site no DuckDuckGo de forma fácil, precisa e rápida.
A funcionalidade do A-Parser permite salvar as configurações de extração de dados do scraper SE::DuckDuckGo::Position para uso futuro (presets), definir cronogramas de extração de dados e muito mais. Você pode utilizar a substituição automática de subconsultas a partir de arquivos.
A preservação dos resultados é possível no formato e estrutura que você desejar, graças ao poderoso motor de modelos integrado Template Toolkit, que permite aplicar lógica adicional aos resultados e exibir dados em vários formatos, incluindo JSON, SQL e CSV.
Dados coletados
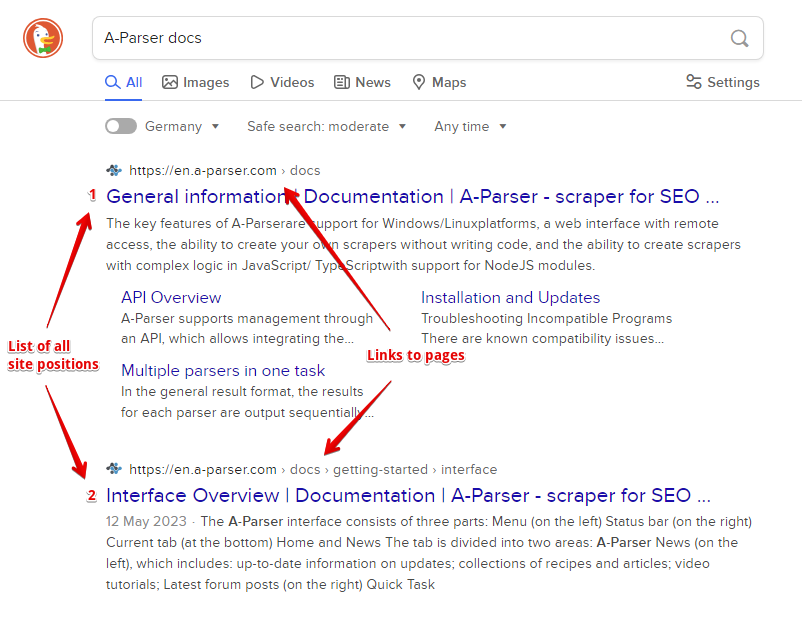
- A posição do site e o link para a página do site
- Lista de todas as posições do site e links para as páginas
Recursos
- Todos os recursos do scraper
 SE::DuckDuckGo
SE::DuckDuckGo - Interrompe automaticamente a extração de dados ao encontrar o site
- Suporta busca de subdomínios
- Possibilidade de comparar a posição buscada por domínio, por domínio principal e por link completo
- Coleta de posições simultaneamente para vários domínios
Casos de uso
- Verificação de posições de seus próprios sites e de sites concorrentes
- Busca de páginas com tráfego do site
Consultas
Como consultas, é necessário indicar o domínio do site buscado e a consulta de pesquisa separados por um espaço, por exemplo:
lenta.ru notícias
lenta.ru notícias online
ria.ru notícias
a-parser.com A-Parser
Se for necessário verificar um único site por uma lista de consultas, você pode indicar o domínio no formato de consulta (Query format):
lenta.ru $query
Ou usar apenas uma lista de palavras-chave. Para usar vários domínios em uma consulta simultaneamente, você deve indicar a lista de domínios separados por vírgula e a palavra-chave após um espaço, por exemplo:
lenta.ru,ria.ru,notfound.com notícias lenta
Os resultados serão gravados na matriz $bulkcheck.
A opção Stop when found também é suportada; a extração de dados terminará se as posições forem encontradas para todos os domínios.
Substituições de consultas
Você pode usar macros integradas para substituição automática de subconsultas a partir de arquivos; por exemplo, queremos verificar sites/site por uma base de chaves, indicaremos algumas consultas principais:
ria.ru
lenta.ru
rbc.ru
yandex.ru
No formato de consultas, indicaremos a macro de substituição de palavras adicionais do arquivo Keywords.txt; este método permite verificar uma base de sites por uma base de chaves e obter as posições como resultado:
$query {subs:Keywords}
Esta macro criará tantas consultas adicionais quantas estiverem no arquivo para cada consulta de pesquisa original, o que resultará em [quantidade de consultas originais(domínios)] x [quantidade de consultas no arquivo Keywords] = [quantidade total de consultas] como resultado da execução da macro.
Opções de exibição de resultados
O A-Parser suporta formatação flexível de resultados graças ao motor de modelos integrado Template Toolkit, o que permite exibir resultados de forma arbitrária, bem como estruturada, como CSV ou JSON.
Exportação da lista de posições
Obtenção do resultado no formato:
domínio buscado - chave: número da posição nos resultados
Formato do resultado:
$domain - $key: $position\n
Exemplo de resultado:
lenta.ru - notícias online: 13
lenta.ru - notícias: 26
ria.ru - notícias: 1
a-parser.com - A-Parser: 1
...
Verificação simultânea de vários domínios (verificação em lote)
As informações de todos os domínios em uma verificação simultânea de vários domínios estão contidas na matriz $bulkcheck.
Formato do resultado:
$bulkcheck.format('$domain - $position\n')
Exemplo de consulta:
lenta.ru,ria.ru,notfound.com notícias lenta
Exemplo de resultado:
lenta.ru - 2
ria.ru - 6
notfound.com - 0
Links + âncoras + snippets com exibição de posição
Da mesma forma que no SE::Google.
Exibição de links, âncoras e snippets em tabela CSV
Da mesma forma que no SE::Google.
Salvando palavras-chave relacionadas
Da mesma forma que no SE::Google.
Concorrência de palavras-chave
Da mesma forma que no SE::Google.
Verificação de indexação de links
Da mesma forma que no SE::Google.
Salvando em formato SQL
Da mesma forma que no SE::Google.
Dump de resultados em JSON
Da mesma forma que no SE::Google.
Processamento de resultados
O A-Parser permite processar resultados diretamente durante a extração de dados; nesta seção, apresentamos os casos mais populares para o scraper SE::DuckDuckGo::Position
Salvando domínios sem posições zero
Tomou-se como base o exemplo de verificação simultânea de vários domínios (veja acima nas opções de exibição de resultados) e foi adicionado um filtro.
Adicione um filtro e, na lista suspensa, selecione a variável de saída da posição. Selecione o tipo: >. Em seguida, em Number (Número), insira 0. Com este filtro, você poderá remover todos os resultados com posição zero.
Baixar exemplo
Como importar um exemplo para o A-Parser
eJx1VNtu2zAM/RVDCNAVyIJ2a4HBDwPSbhk2dE3Wy1OSB8WiWy2y6OmSXoL8+yhZ
ttNufYgi3g55SMpb5rhd25kBC86yfL5ldbyznF1/zfMvvliH3zfM8xla6STq7H12
zTeQCay41DZ7kO4evct49gwGszq5sSGrubFgAuz8TTRyE1Byrxwbbpl7qoFS4waM
kQLIKAXJ3kJt8PGJ5A1XnlxKrizs3o4o0VTcEZUI3EaxwcqrdXEPxXrUeLw7GDQ8
iNWgLX2x0AeHbA+9lMqBIZwEmM9ZBxR4tlyWw+R608R93kt9RHeso1vOLGjLdstl
i2gnsZpQYX08SiPojKHdN9jUAb16QtIlryIvwR0Ea0vrcOQeAwIXIpbGVZMhDKPP
eqvln1icRvKlq5FgJwYrUjmIAEH51FY3Z4MoB6I+xv5qYtJAhsxSqRNOhYjXFklt
4Q7NNPaA9FuGeqzUBWxA9W4R/8xLJWhzxiUFfU+B/3eZ/oOx6+jtp6L9eDBUQ4cS
pbPpzz5K4AXeEXOxIt5KVtKRbM/Ra5fmtwaou55dhp5VaKBLk5BTdnpUNeiwjP3I
xnWvekHjxVheKgvUpbybpgVvPb2+oZc71edY1QoCL+2VGoanctWvx9imMQShL/B1
8HlMEai3T5E5RGV/XDel1kbS+p2GAivq5H7WBFlwpW6vLvYtrF8pEhRox0fGD42M
fxpdSZ0VowKrbOGPTj6KeEI8P/T3k+N4NppPjesqnqd9WDKHGRX0Eu6QdpT6tFt2
H6HuE7d9+1OUb3e0Br/trAkJPQsBpKPm2+hxvPsLSinNVw==
Veja também: Filtros de resultados
Desduplicação de links
Da mesma forma que no SE::Google.
Desduplicação de links por domínio
Da mesma forma que no SE::Google.
Extração de domínios
Da mesma forma que no SE::Google.
Remoção de tags de âncoras e snippets
Da mesma forma que no SE::Google.
Filtragem de links por inclusão
Da mesma forma que no SE::Google.
Configurações possíveis
Suporta todas as configurações do scraper SE::DuckDuckGo, além de adicionalmente:
| Nome do parâmetro | Valor padrão | Descrição |
|---|---|---|
| Result format | $domain - $key: $position\n | Formato padrão de saída do resultado |
| Stop when found | ☑ | Interromper a extração de dados se o domínio for encontrado, não passará para as próximas páginas |
| Match type | Exact domain | Possibilidade de comparar a posição buscada por domínio, por domínio principal e por link completo (Exact domain / Top level domain / Exact url) |