HTML::TextExtractor - Cào dữ liệu nội dung (văn bản) từ trang web
Tổng quan về công cụ cào dữ liệu
 HTML::TextExtractor cào dữ liệu các khối văn bản từ trang được chỉ định. Công cụ cào dữ liệu nội dung này hỗ trợ cào dữ liệu nhiều trang (chuyển hướng qua các trang). Có tích hợp các công cụ vượt qua bảo vệ CloudFlare và cũng có khả năng lựa chọn Chrome làm công cụ để cào dữ liệu nội dung từ các trang mà dữ liệu được tải bằng tập lệnh. Có khả năng đạt tốc độ lên đến 2000 truy vấn mỗi phút – tương đương 120 000 liên kết mỗi giờ.
HTML::TextExtractor cào dữ liệu các khối văn bản từ trang được chỉ định. Công cụ cào dữ liệu nội dung này hỗ trợ cào dữ liệu nhiều trang (chuyển hướng qua các trang). Có tích hợp các công cụ vượt qua bảo vệ CloudFlare và cũng có khả năng lựa chọn Chrome làm công cụ để cào dữ liệu nội dung từ các trang mà dữ liệu được tải bằng tập lệnh. Có khả năng đạt tốc độ lên đến 2000 truy vấn mỗi phút – tương đương 120 000 liên kết mỗi giờ.Các trường hợp ứng dụng công cụ cào dữ liệu
Cào dữ liệu văn bản qua Chrome lấy ví dụ từ lingualeo.com
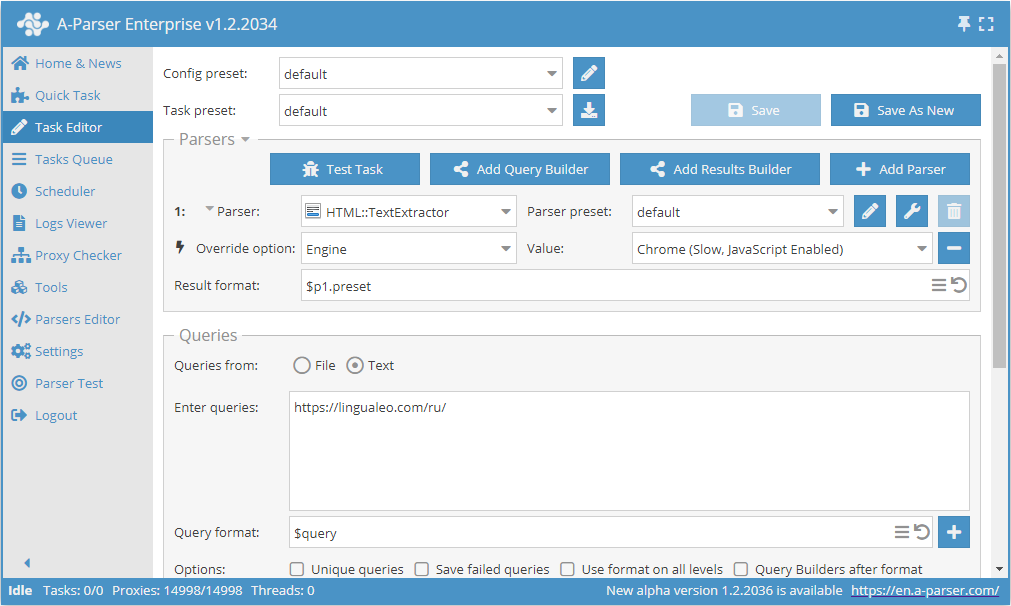
- Thêm tùy chọn Engine, trong danh sách chọn trình duyệt
Chrome (Slow, JavaScript Enabled). - Trong phần truy vấn, hãy chỉ định liên kết đến trang web mà bạn cần cào dữ liệu văn bản.
ghi chú
Tùy chọn này có thể hữu ích trong trường hợp trang web tải văn bản chính bằng các tập lệnh trong quá trình tải trang và khi sử dụng HTTP (Fast, JavaScript Disabled) kết quả bị thiếu hoặc không đầy đủ.
Tải xuống ví dụ
eJxtU01v2zAM/S9EDhsQJO1hF9/SYME6pHXXpqcgB8GmXa2ypOkjS2Hkv+/Jce2k
680kHx8fxeeWgvCv/sGx5+Ap27Zku2/KqORKRBVoSlY4zy6Vt/Rjc7fOsg0fwvdD
cKIIxgExYFsKb5bRbfbsnCwZRVkiZl1LnaK9UDEBihdnGqbjbjcljES3XxnXiDR6
Yq9nvY6h+CT2vDEoVlLxmF4huhdNYpyUInCqzqqO6MvXWTgkBlGWMkijhTpNSJuM
U5+1/NMp8sFJXQOP0En2KwhEOnBHkpJv7wq3NOliAk3s+n+deigLLvKUPNSuBLSU
Q6ESyqMiAzuBV8ttkoR8S0YvlFrzntUI6+hvolQlXn5Roem2b/wckv/HcRw2PB+F
s/x10DCwdNFNfjd2lWZtaiyuDdZWspEBsV+aqNNtrpB8ZbbDs90nWGMcD2N65n46
zGVZJw+MV1vYMXWxxsVlLpOF0ZWs895X78ioN3BwrpemsYrTXjoqhat4fhwdsvD9
GVIwCvzYvOxGXHg/GKP8z6eTVOskHPgtCWzwkudTe8pCKPX8uD6v0OgoBC8hWJ/N
5wpWi0KxmRWmmbs4p9QcuDZwFVY77ob/bvg720//vqw94mi//cMJnTZMWOTwVB4X
oez6+A9VbWHX
Cào dữ liệu văn bản với chuyển trang qua ví dụ tin tức
Kết quả được lưu trong thư mục aparser/results/example/textextractor vào một tệp riêng biệt cho mỗi truy vấn. Số thứ tự của truy vấn được sử dụng làm tên tệp.
- Thêm tùy chọn Check next page, nhập biểu thức chính quy là
(forum\/news\/page-\d+)"[^>]+>Tiếp theo. - Thêm tùy chọn Page as new query.
- Thay đổi File name (Tên tệp) thành
example/textextractor/${query.num}.txt. - Nhập liên kết đến trang tin tức đầu tiên của A-Parser làm truy vấn:
https://a-parser.com/forum/news/.
Tải xuống ví dụ
eJx1VN1v2jAQ/18sHjaVEtjoSx4qUVS0TRRoS58Ik6zkQj0c27UdPhTlf9/ZCQmw
7sXJne/jd7+7c0EsNVuz0GDAGhKuCqL8PwnJ44FmikMYLuFgHw9W09hKHYYzFBd0
A6RLFNUGtPNbkR/Lp+mVLVokkNKcW9ItiD0qwLBSWSaFwTuWoBi/Q7w9C7mjPHdm
X1Kp8yyKAgF7gx+F17dRlNx8jcjq9/365j7K+8PBN3d+T/15585h3513A68ZYkCa
JMxlpJyExWW6KcuYq7RPyvK/AF3ikZnB/jkHfWwRWp3DdfQtgPJmU9gBavpluV53
CTKKHJiJ1Bl1+Tpq0Ktpbi5f6Q6WEi9TxqFVT1Ca0czhgqofgUX0cKI46BQfLmFP
5FnZswd7UXGV0fWnRfEm2IdnWEi0dc4MzETLDFUubq08ntCuSMfLBEPk3ve58iFh
SrlBDgxCn1AEmlzfMAuaIsp5TSlSJMWIc09Pa+bjP+SMJzhMoxSdftaOn5vM/4lR
NuWdp9qB3mvE0ETx0sP8qfVK5FRuTmRwNw8om7HMRTUYXd/ThrOZM8ukhiZNHbnO
joukQLixaVs4Uq3qooyLtlwqYylStpljAZolcLLMxRK3dS7G0g2Cq0vknGNbDLy0
4zIydRuc0AK8dh77FAirWVFipeTm12sFVWmG43jnAGbI5HnWOmRMOX97mZ7fkHak
UHi3VpkwCOht9VD0YpkFfq/9VgfExbCwkThdWGG5bl6U5kEqPn1XwgIXlvwxi8ra
FepsUYeMGWwMCQflX6y1tO0=
Dữ liệu thu thập được
- Cào các khối văn bản từ trang được chỉ định
- Mảng chứa tất cả các trang đã thu thập (được sử dụng khi bật tùy chọn Use Pages)
Khả năng
- Cào dữ liệu văn bản nhiều trang (chuyển trang)
- Tự động làm sạch văn bản khỏi các thẻ HTML
- Có thể thiết lập độ dài tối thiểu cho khối văn bản
- Tùy chọn xóa các neo liên kết (anchor) khỏi văn bản
- Hỗ trợ nén gzip/deflate/brotli
- Xác định và chuyển đổi bảng mã của trang web sang UTF-8
- Vượt qua bảo vệ CloudFlare
- Lựa chọn công cụ (HTTP hoặc Chrome)
Các trường hợp sử dụng
- Cào nội dung văn bản từ bất kỳ trang web nào
Truy vấn
Các truy vấn phải là liên kết đến các trang mà bạn cần cào các khối văn bản, ví dụ:
https://a-parser.com/
Các tùy chọn xuất kết quả
A-Parser hỗ trợ định dạng kết quả linh hoạt nhờ công cụ mẫu tích hợp Template Toolkit, cho phép xuất kết quả ở định dạng tùy ý cũng như định dạng có cấu trúc như CSV hoặc JSON
Xuất mặc định
Định dạng kết quả:
$texts.format('$text\n')
Ví dụ kết quả:
Xin chào, Đội ngũ Siêu đẳng gồm những Chuyên gia bậc nhất trong lĩnh vực của mình! Cảm ơn vì cơ hội học tiếng Tây Ban Nha, Thổ Nhĩ Kỳ và Bồ Đào Nha! Chúc các bạn tiếp tục mở rộng Khả năng của mình! Luôn tràn đầy Cảm hứng và Sáng tạo! Và xin vui lòng thêm Khả năng học tiếng Đức và tiếng Pháp!”
Tôi đã sử dụng Lingualeo nhiều năm nay, lần đầu tiên bắt đầu học là khi chưa có ứng dụng, chỉ có trang web) Cảm ơn các nhà phát triển, hãy tiếp tục phát huy tinh thần đó, với sự sáng tạo và tình yêu lớn dành cho công việc)
Tiếng Anh kỹ thuật cho IT: từ điển, giáo trình, tạp chí
Học ngôn ngữ trực tuyến Học tiếng Anh trực tuyến Học tiếng Việt trực tuyến Học tiếng Hy Lạp trực tuyến Học tiếng Indonesia trực tuyến Học tiếng Tây Ban Nha trực tuyến Học tiếng Ý trực tuyến Học tiếng Trung trực tuyến Học tiếng Hàn trực tuyến Học tiếng Đức trực tuyến Học tiếng Hà Lan trực tuyến Học tiếng Ba Lan trực tuyến Học tiếng Bồ Đào Nha trực tuyến Học tiếng Serbia trực tuyến Học tiếng Thổ Nhĩ Kỳ trực tuyến Học tiếng Ukraina trực tuyến Học tiếng Pháp trực tuyến Học tiếng Hindi trực tuyến Học tiếng Séc trực tuyến Học tiếng Nhật trực tuyến
Các cài đặt có thể có
| Tên tham số | Giá trị mặc định | Mô tả |
|---|---|---|
| Min block length | 50 | Độ dài tối thiểu của khối văn bản tính bằng ký tự. |
| Skip anchor text | ☐ | Có bỏ qua các neo (anchors) trong văn bản hay không. |
| Ignore tags list | Tùy chọn để chỉ định các thẻ cần bỏ qua. Ví dụ: div,span,p | |
| Good status | All | Chọn phản hồi nào từ máy chủ sẽ được coi là thành công. Nếu khi cào dữ liệu nhận được phản hồi khác từ máy chủ, truy vấn sẽ được lặp lại với proxy khác. |
| Good code RegEx | Khả năng chỉ định biểu thức chính quy để kiểm tra mã phản hồi. | |
| Method | GET | Phương thức truy vấn. |
| POST body | Nội dung để gửi đến máy chủ khi sử dụng phương thức POST. Hỗ trợ các biến $query – URL truy vấn, $query.orig – truy vấn gốc và $pagenum - số trang khi sử dụng tùy chọn Use Pages. | |
| Cookies | Khả năng chỉ định cookies cho truy vấn. | |
| User agent | `_Tự động chèn user-agent của phiên bản Chrome hiện tại_ | Tiêu đề User-Agent khi truy vấn trang. |
| Additional headers | Khả năng chỉ định các tiêu đề truy vấn tùy chỉnh với sự hỗ trợ của các tính năng bộ tạo mẫu và sử dụng các biến từ trình tạo truy vấn. | |
| Read only headers | ☐ | Chỉ đọc tiêu đề. Trong một số trường hợp cho phép tiết kiệm lưu lượng nếu không cần xử lý nội dung. |
| Detect charset on content | ☐ | Nhận dạng bảng mã dựa trên nội dung trang. |
| Emulate browser headers | ☐ | Mô phỏng tiêu đề trình duyệt. |
| Max redirects count | 7 | Số lượng chuyển hướng tối đa mà công cụ cào dữ liệu sẽ thực hiện. |
| Max cookies count | 16 | Số lượng cookies tối đa để lưu trữ. |
| Bypass CloudFlare | ☑ | Tự động vượt qua kiểm tra CloudFlare. |
| Follow common redirects | ☑ | Cho phép thực hiện chuyển hướng http <-> https và www.domain <-> domain trong phạm vi một tên miền mà không tính vào giới hạn Max redirects count. |
| Engine | HTTP (Fast, JavaScript Disabled) | Cho phép chọn công cụ HTTP (nhanh hơn, không có JavaScript) hoặc Chrome (chậm hơn, có bật JavaScript). |
| Chrome Headless | ☐ | Nếu tùy chọn này được bật, trình duyệt sẽ không hiển thị. |
| Chrome DevTools | ☑ | Cho phép sử dụng các công cụ gỡ lỗi Chromium. |
| Chrome Log Proxy connections | ☑ | Nếu tùy chọn này được bật, thông tin về các kết nối chrome sẽ được hiển thị trong nhật ký (log). |
| Chrome Wait Until | networkidle2 | Xác định khi nào trang được coi là đã tải xong. Chi tiết về các giá trị. |
| Use HTTP/2 transport | ☐ | Xác định xem có sử dụng HTTP/2 thay vì HTTP/1.1 hay không. Ví dụ, Google và Majestic sẽ chặn ngay lập tức nếu sử dụng HTTP/1.1. |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Vượt qua CF thông qua Chrome. |
| Bypass CloudFlare with Chrome Max Pages | Số lượng trang tối đa khi vượt qua CF thông qua Chrome. |