HTML::TextExtractor - Dataskrapning av innehåll (text) från webbplatser
Översikt av scrapern
 HTML::TextExtractor skrapar textblock från den angivna sidan. Denna innehållsscraper stöder flersidig dataskrapning (sidnavigering). Har inbyggda verktyg för att kringgå skydd CloudFlare och även möjlighet att välja Chrome som motor för dataskrapning av innehåll från sidor där data laddas med skript. Kan nå en hastighet på upp till 2000 sökfrågor per minut – det är 120 000 länkar per timme.
HTML::TextExtractor skrapar textblock från den angivna sidan. Denna innehållsscraper stöder flersidig dataskrapning (sidnavigering). Har inbyggda verktyg för att kringgå skydd CloudFlare och även möjlighet att välja Chrome som motor för dataskrapning av innehåll från sidor där data laddas med skript. Kan nå en hastighet på upp till 2000 sökfrågor per minut – det är 120 000 länkar per timme.Användningsfall för scrapern
Dataskrapning av text via Chrome med lingualeo.com som exempel
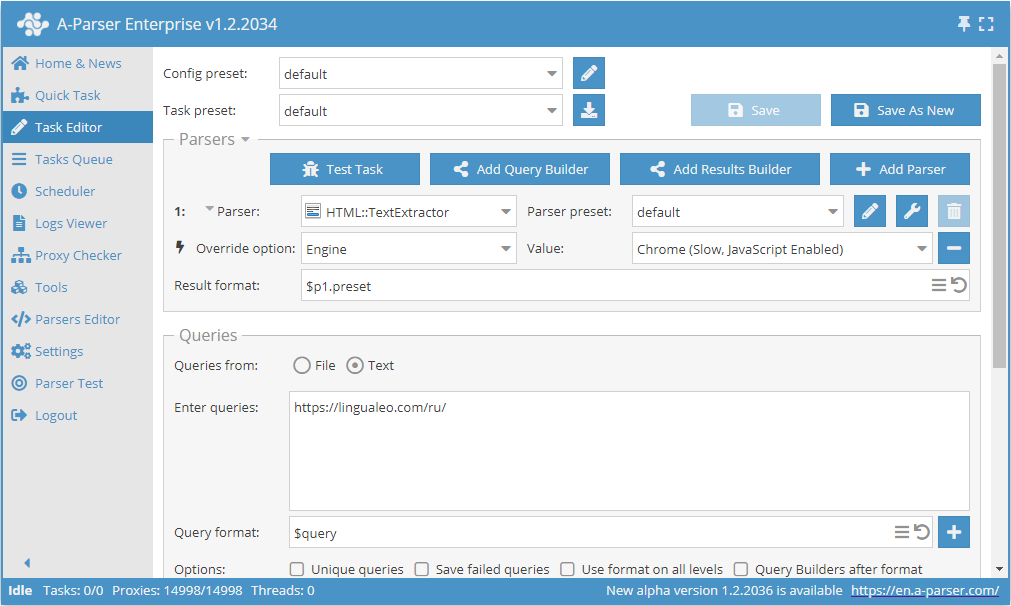
- Lägg till alternativet Engine, välj motorn
Chrome (Slow, JavaScript Enabled)i listan. - Ange länken till webbplatsen som texten ska skrapas från som sökfråga.
Detta alternativ kan vara användbart i fall där webbplatsen laddar huvudsaklig text med skript under sidladdningen och när HTTP (Fast, JavaScript Disabled) används blir resultatet tomt eller ofullständigt.
Ladda ner exempel
Hur man importerar ett exempel till A-Parser
eJxtU01v2zAM/S9EDhsQJO1hF9/SYME6pHXXpqcgB8GmXa2ypOkjS2Hkv+/Jce2k
680kHx8fxeeWgvCv/sGx5+Ap27Zku2/KqORKRBVoSlY4zy6Vt/Rjc7fOsg0fwvdD
cKIIxgExYFsKb5bRbfbsnCwZRVkiZl1LnaK9UDEBihdnGqbjbjcljES3XxnXiDR6
Yq9nvY6h+CT2vDEoVlLxmF4huhdNYpyUInCqzqqO6MvXWTgkBlGWMkijhTpNSJuM
U5+1/NMp8sFJXQOP0En2KwhEOnBHkpJv7wq3NOliAk3s+n+deigLLvKUPNSuBLSU
Q6ESyqMiAzuBV8ttkoR8S0YvlFrzntUI6+hvolQlXn5Roem2b/wckv/HcRw2PB+F
s/x10DCwdNFNfjd2lWZtaiyuDdZWspEBsV+aqNNtrpB8ZbbDs90nWGMcD2N65n46
zGVZJw+MV1vYMXWxxsVlLpOF0ZWs895X78ioN3BwrpemsYrTXjoqhat4fhwdsvD9
GVIwCvzYvOxGXHg/GKP8z6eTVOskHPgtCWzwkudTe8pCKPX8uD6v0OgoBC8hWJ/N
5wpWi0KxmRWmmbs4p9QcuDZwFVY77ob/bvg720//vqw94mi//cMJnTZMWOTwVB4X
oez6+A9VbWHX
Dataskrapning av text med sidnavigering med nyheter som exempel
Resultaten sparas i katalogen aparser/results/example/textextractor i en separat fil för varje sökfråga. Som namn anges sökfrågans ordningsnummer.
- Lägg till alternativet Check next page, ange
(forum\/news\/page-\d+)"[^>]+>Nästasom reguljärt uttryck. - Lägg till alternativet Page as new query.
- Ändra File name (Filnamn) till
example/textextractor/${query.num}.txt. - Ange länken till den första sidan med A-Parser-nyheter som sökfråga:
https://a-parser.com/forum/news/.
Ladda ner exempel
Hur man importerar ett exempel till A-Parser
eJx1VN1v2jAQ/18sHjaVEtjoSx4qUVS0TRRoS58Ik6zkQj0c27UdPhTlf9/ZCQmw
7sXJne/jd7+7c0EsNVuz0GDAGhKuCqL8PwnJ44FmikMYLuFgHw9W09hKHYYzFBd0
A6RLFNUGtPNbkR/Lp+mVLVokkNKcW9ItiD0qwLBSWSaFwTuWoBi/Q7w9C7mjPHdm
X1Kp8yyKAgF7gx+F17dRlNx8jcjq9/365j7K+8PBN3d+T/15585h3513A68ZYkCa
JMxlpJyExWW6KcuYq7RPyvK/AF3ikZnB/jkHfWwRWp3DdfQtgPJmU9gBavpluV53
CTKKHJiJ1Bl1+Tpq0Ktpbi5f6Q6WEi9TxqFVT1Ca0czhgqofgUX0cKI46BQfLmFP
5FnZswd7UXGV0fWnRfEm2IdnWEi0dc4MzETLDFUubq08ntCuSMfLBEPk3ve58iFh
SrlBDgxCn1AEmlzfMAuaIsp5TSlSJMWIc09Pa+bjP+SMJzhMoxSdftaOn5vM/4lR
NuWdp9qB3mvE0ETx0sP8qfVK5FRuTmRwNw8om7HMRTUYXd/ThrOZM8ukhiZNHbnO
joukQLixaVs4Uq3qooyLtlwqYylStpljAZolcLLMxRK3dS7G0g2Cq0vknGNbDLy0
4zIydRuc0AK8dh77FAirWVFipeTm12sFVWmG43jnAGbI5HnWOmRMOX97mZ7fkHak
UHi3VpkwCOht9VD0YpkFfq/9VgfExbCwkThdWGG5bl6U5kEqPn1XwgIXlvwxi8ra
FepsUYeMGWwMCQflX6y1tO0=
Insamlade data
- Skrapar textblock från den angivna sidan
- Array med alla insamlade sidor (används när alternativet Use Pages är aktiverat)
Funktioner
- Flersidig dataskrapning av text (sidnavigering)
- Automatisk rensning av text från HTML-taggar
- Möjlighet att ställa in minsta längd för ett textblock
- Valfri borttagning av länkankare från texten
- Stöder komprimering med gzip/deflate/brotli
- Identifiering och konvertering av webbplatsers kodning till UTF-8
- Kringgående av CloudFlare-skydd
- Val av motor (HTTP eller Chrome)
Användningsområden
- Dataskrapning av textinnehåll från vilka webbplatser som helst
Sökfrågor
Som sökfrågor måste länkar till de sidor som textblocken ska skrapas från anges, till exempel:
https://a-parser.com/
Exempel på resultatutmatning
A-Parser stöder flexibel formatering av resultat tack vare den inbyggda mallmotorn Template Toolkit, vilket gör det möjligt att mata ut resultat i valfri form, såväl som i strukturerad form, till exempel CSV eller JSON
Standardutmatning
Resultatformat:
$texts.format('$text\n')
Exempel på resultat:
Hej, Superteamet av de främsta proffsen inom sitt område! Tack för möjligheten att studera spanska, turkiska och portugisiska! Jag önskar er ytterligare expansion av era möjligheter! Inspiration och kreativitet! Och en begäran om att lägga till möjligheten att studera tyska och franska!”
Jag har använt Lingualeo i många år, började första gången när appen inte fanns alls, det fanns bara en webbplats) Tack till utvecklarna, fortsätt i samma anda, med kreativitet och stor kärlek till arbetet)
Teknisk engelska för IT: ordböcker, läroböcker, tidskrifter
Lär dig språk online Lär dig engelska online Lär dig vietnamesiska online Lär dig grekiska online Lär dig indonesiska online Lär dig spanska online Lär dig italienska online Lär dig kinesiska online Lär dig koreanska online Lär dig tyska online Lär dig nederländska online Lär dig polska online Lär dig portugisiska online Lär dig serbiska online Lär dig turkiska online Lär dig ukrainska online Lär dig franska online Lär dig hindi online Lär dig tjeckiska online Lär dig japanska online
Möjliga inställningar
| Namn på parameter | Standardvärde | Beskrivning |
|---|---|---|
| Min block length | 50 | Minsta längd på textblock i tecken. |
| Skip anchor text | ☐ | Om ankare i texten ska hoppas över. |
| Ignore tags list | Alternativ för att ange taggar som ska ignoreras. Exempel på angivelse: div,span,p | |
| Good status | All | Val av vilket svar från servern som ska anses vara lyckat. Om ett annat svar erhålls vid dataskrapning kommer sökfrågan att upprepas med en annan proxy. |
| Good code RegEx | Möjlighet att ange ett reguljärt uttryck för att kontrollera svarskoden. | |
| Method | GET | Metod för sökfrågan. |
| POST body | Innehåll som ska skickas till servern när POST-metoden används. Stöder variablerna $query – sökfrågans URL, $query.orig – ursprunglig sökfråga och $pagenum - sidnummer när alternativet Use Pages används. | |
| Cookies | Möjlighet att ange cookies för sökfrågan. | |
| User agent | `_Automatiskt infogas user-agent för den aktuella versionen av Chrome_ | Headern User-Agent vid begäran av sidor. |
| Additional headers | Möjlighet att ange godtyckliga sökfrågeheaders med stöd för mallmotorns funktioner och användning av variabler från sökfrågebyggaren. | |
| Read only headers | ☐ | Läs endast headers. I vissa fall sparar detta trafik om det inte finns behov av att bearbeta innehållet. |
| Detect charset on content | ☐ | Identifiera kodning baserat på sidans innehåll. |
| Emulate browser headers | ☐ | Emulera webbläsarheaders. |
| Max redirects count | 7 | Maximalt antal omdirigeringar som scrapern kommer att följa. |
| Max cookies count | 16 | Maximalt antal cookies att spara. |
| Bypass CloudFlare | ☑ | Automatiskt kringgående av CloudFlare-kontroll. |
| Follow common redirects | ☑ | Tillåter omdirigeringar http <-> https och www.domain <-> domain inom samma domän, förbi gränsen för Max redirects count. |
| Engine | HTTP (Fast, JavaScript Disabled) | Tillåter val av motor: HTTP (snabbare, utan JavaScript) eller Chrome (långsammare, JavaScript aktiverat). |
| Chrome Headless | ☐ | Om alternativet är aktiverat kommer webbläsaren inte att visas. |
| Chrome DevTools | ☑ | Tillåter användning av verktyg för Chromium-felsökning. |
| Chrome Log Proxy connections | ☑ | Om alternativet är aktiverat kommer information om Chrome-anslutningar att visas i loggen. |
| Chrome Wait Until | networkidle2 | Definierar när sidan anses vara laddad. Mer om värdena. |
| Use HTTP/2 transport | ☐ | Definierar om HTTP/2 ska användas istället för HTTP/1.1. Till exempel bannlyser Google och Majestic omedelbart om HTTP/1.1 används. |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Kringgående av CF via Chrome. |
| Bypass CloudFlare with Chrome Max Pages | Max antal sidor vid kringgående av CF via Chrome. |