HTML::TextExtractor - Scrapowanie kontentu (tekstu) ze strony
Przegląd scrapera
 HTML::TextExtractor scrapuje bloki tekstowe ze wskazanej strony. Ten scraper treści obsługuje wielostronicowe scrapowanie (przechodzenie po stronach). Posiada wbudowane narzędzia do omijania ochrony CloudFlare a także możliwość wyboru Chrome jako silnika do scrapowania treści ze stron, na których dane są ładowane skryptami. Jest w stanie osiągnąć prędkość do 2000 zapytań na minutę – co daje 120 000 linków na godzinę.
HTML::TextExtractor scrapuje bloki tekstowe ze wskazanej strony. Ten scraper treści obsługuje wielostronicowe scrapowanie (przechodzenie po stronach). Posiada wbudowane narzędzia do omijania ochrony CloudFlare a także możliwość wyboru Chrome jako silnika do scrapowania treści ze stron, na których dane są ładowane skryptami. Jest w stanie osiągnąć prędkość do 2000 zapytań na minutę – co daje 120 000 linków na godzinę.Przypadki użycia scrapera
Scrapowanie tekstu przez Chrome na przykładzie lingualeo.com
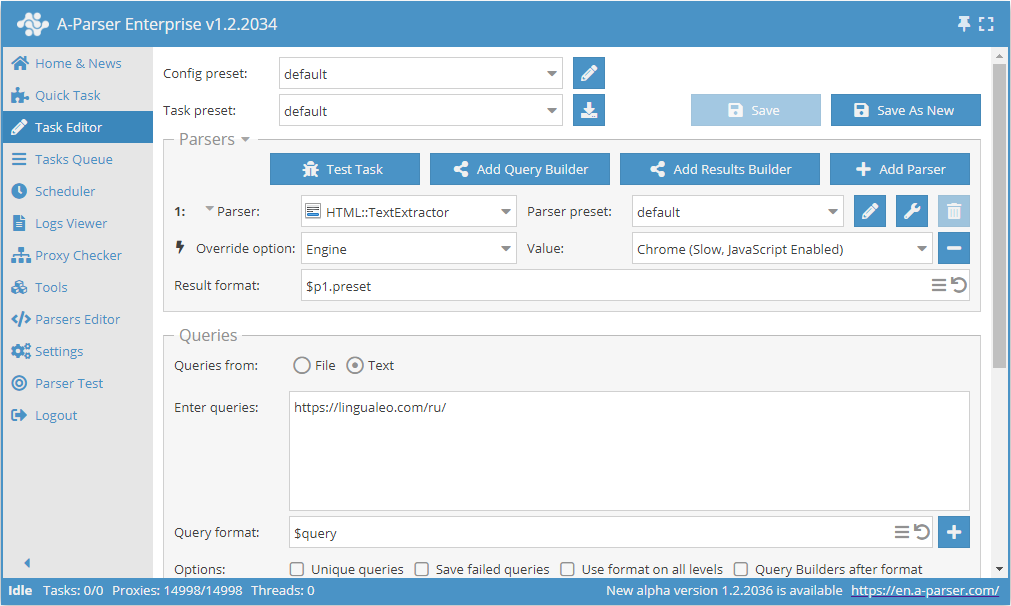
- Dodać opcję Engine, na liście wybrać silnik
Chrome (Slow, JavaScript Enabled). - Jako zapytanie podać link do strony, z której należy sprasować tekst.
Ta opcja może być przydatna w przypadkach, gdy strona ładuje główny tekst skryptami w trakcie ładowania strony i przy użyciu HTTP (Fast, JavaScript Disabled) wynik jest nieobecny lub niepełny.
Pobierz przykład
Jak zaimportować przykład do A-Parser
eJxtU01v2zAM/S9EDhsQJO1hF9/SYME6pHXXpqcgB8GmXa2ypOkjS2Hkv+/Jce2k
680kHx8fxeeWgvCv/sGx5+Ap27Zku2/KqORKRBVoSlY4zy6Vt/Rjc7fOsg0fwvdD
cKIIxgExYFsKb5bRbfbsnCwZRVkiZl1LnaK9UDEBihdnGqbjbjcljES3XxnXiDR6
Yq9nvY6h+CT2vDEoVlLxmF4huhdNYpyUInCqzqqO6MvXWTgkBlGWMkijhTpNSJuM
U5+1/NMp8sFJXQOP0En2KwhEOnBHkpJv7wq3NOliAk3s+n+deigLLvKUPNSuBLSU
Q6ESyqMiAzuBV8ttkoR8S0YvlFrzntUI6+hvolQlXn5Roem2b/wckv/HcRw2PB+F
s/x10DCwdNFNfjd2lWZtaiyuDdZWspEBsV+aqNNtrpB8ZbbDs90nWGMcD2N65n46
zGVZJw+MV1vYMXWxxsVlLpOF0ZWs895X78ioN3BwrpemsYrTXjoqhat4fhwdsvD9
GVIwCvzYvOxGXHg/GKP8z6eTVOskHPgtCWzwkudTe8pCKPX8uD6v0OgoBC8hWJ/N
5wpWi0KxmRWmmbs4p9QcuDZwFVY77ob/bvg720//vqw94mi//cMJnTZMWOTwVB4X
oez6+A9VbWHX
Scrapowanie tekstu z przechodzeniem po stronach na przykładzie wiadomości
Wyniki są zapisywane w katalogu aparser/results/example/textextractor w osobnym pliku dla każdego zapytania. Jako nazwa używany jest numer porządkowy zapytania.
- Dodać opcję Check next page, jako wyrażenie regularne podać
(forum\/news\/page-\d+)"[^>]+>Dalej. - Dodać opcję Page as new query.
- Zmienić File name (Nazwa pliku) na
example/textextractor/${query.num}.txt. - Jako zapytanie podać link do pierwszej strony z wiadomościami A-Parser:
https://a-parser.com/forum/news/.
Pobierz przykład
Jak zaimportować przykład do A-Parser
eJx1VN1v2jAQ/18sHjaVEtjoSx4qUVS0TRRoS58Ik6zkQj0c27UdPhTlf9/ZCQmw
7sXJne/jd7+7c0EsNVuz0GDAGhKuCqL8PwnJ44FmikMYLuFgHw9W09hKHYYzFBd0
A6RLFNUGtPNbkR/Lp+mVLVokkNKcW9ItiD0qwLBSWSaFwTuWoBi/Q7w9C7mjPHdm
X1Kp8yyKAgF7gx+F17dRlNx8jcjq9/365j7K+8PBN3d+T/15585h3513A68ZYkCa
JMxlpJyExWW6KcuYq7RPyvK/AF3ikZnB/jkHfWwRWp3DdfQtgPJmU9gBavpluV53
CTKKHJiJ1Bl1+Tpq0Ktpbi5f6Q6WEi9TxqFVT1Ca0czhgqofgUX0cKI46BQfLmFP
5FnZswd7UXGV0fWnRfEm2IdnWEi0dc4MzETLDFUubq08ntCuSMfLBEPk3ve58iFh
SrlBDgxCn1AEmlzfMAuaIsp5TSlSJMWIc09Pa+bjP+SMJzhMoxSdftaOn5vM/4lR
NuWdp9qB3mvE0ETx0sP8qfVK5FRuTmRwNw8om7HMRTUYXd/ThrOZM8ukhiZNHbnO
joukQLixaVs4Uq3qooyLtlwqYylStpljAZolcLLMxRK3dS7G0g2Cq0vknGNbDLy0
4zIydRuc0AK8dh77FAirWVFipeTm12sFVWmG43jnAGbI5HnWOmRMOX97mZ7fkHak
UHi3VpkwCOht9VD0YpkFfq/9VgfExbCwkThdWGG5bl6U5kEqPn1XwgIXlvwxi8ra
FepsUYeMGWwMCQflX6y1tO0=
Zbierane dane
- Scrapuje bloki tekstowe ze wskazanej strony
- Tablica ze wszystkimi zebranymi stronami (używana przy działaniu opcji Use Pages)
Funkcje
- Wielostronicowe scrapowanie tekstu (przechodzenie po stronach)
- Automatyczne oczyszczanie tekstu z tagów HTML
- Możliwość ustawienia minimalnej długości bloku tekstowego
- Opcjonalne usuwanie kotwic linków z tekstu
- Obsługuje kompresję gzip/deflate/brotli
- Wykrywanie i konwersja kodowania stron na UTF-8
- Omijanie ochrony CloudFlare
- Wybór silnika (HTTP lub Chrome)
Warianty użycia
- Scrapowanie treści tekstowych z dowolnych stron
Zapytania
Jako zapytania należy podawać linki do stron, z których należy sprasować bloki tekstowe, na przykład:
https://a-parser.com/
Warianty wyprowadzania wyników
A-Parser obsługuje elastyczne formatowanie wyników dzięki wbudowanemu silnikowi szablonów Template Toolkit, co pozwala mu wyprowadzać wyniki w dowolnej formie, a także w strukturalnej, na przykład CSV lub JSON
Wynik domyślny
Format wyniku:
$texts.format('$text\n')
Przykład wyniku:
Witaj, Super Zespole Najwyższej Klasy Profesjonalistów w swoim fachu! Dziękuję za możliwość nauki języka hiszpańskiego, tureckiego i portugalskiego! Życzę Wam dalszego rozszerzania Waszych Możliwości! Inspiracji i Twórczości! I prośba o dodanie Możliwości nauki języka niemieckiego i francuskiego!”
Używam Lingualeo już od wielu lat, pierwszy raz zacząłem ćwiczyć jeszcze gdy aplikacji w ogóle nie było, była tylko strona) Dzięki dla programistów, kontynuujcie w tym samym duchu, z kreatywnością i wielką miłością do tego, co robicie)
Techniczny angielski dla IT: słowniki, podręczniki, czasopisma
Ucz się języków online Ucz się angielskiego online Ucz się wietnamskiego online Ucz się greckiego online Ucz się indonezyjskiego online Ucz się hiszpańskiego online Ucz się włoskiego online Ucz się chińskiego online Ucz się koreańskiego online Ucz się niemieckiego online Ucz się niderlandzkiego online Ucz się polskiego online Ucz się portugalskiego online Ucz się serbskiego online Ucz się tureckiego online Ucz się ukraińskiego online Ucz się francuskiego online Ucz się hindi online Ucz się czeskiego online Ucz się japońskiego online
Możliwe ustawienia
| Nazwa parametru | Wartość domyślna | Opis |
|---|---|---|
| Min block length | 50 | Minimalna długość bloku tekstowego w znakach. |
| Skip anchor text | ☐ | Czy pomijać kotwice w tekście. |
| Ignore tags list | Opcja do wskazania tagów, które należy ignorować. Przykład wskazania: div,span,p | |
| Good status | All | Wybór, która odpowiedź z serwera będzie uznana za sukces. Jeśli podczas scrapowania wystąpi inna odpowiedź z serwera, zapytanie zostanie powtórzone z innym proxy. |
| Good code RegEx | Możliwość wskazania wyrażenia regularnego do sprawdzenia kodu odpowiedzi. | |
| Method | GET | Metoda zapytania. |
| POST body | Treść do przesłania na serwer przy użyciu metody POST. Obsługuje zmienne $query – URL zapytania, $query.orig – zapytanie źródłowe oraz $pagenum - numer strony przy użyciu opcji Use Pages. | |
| Cookies | Możliwość wskazania plików cookies dla zapytania. | |
| User agent | `_Automatycznie podstawiany jest user-agent aktualnej wersji Chrome_ | Nagłówek User-Agent przy zapytaniu o strony. |
| Additional headers | Możliwość wskazania dowolnych nagłówków zapytania z obsługą możliwości silnika szablonów i użyciem zmiennych z konstruktora zapytań. | |
| Read only headers | ☐ | Czytać tylko nagłówki. W niektórych przypadkach pozwala oszczędzać transfer, jeśli nie ma potrzeby przetwarzania treści. |
| Detect charset on content | ☐ | Rozpoznawać kodowanie na podstawie zawartości strony. |
| Emulate browser headers | ☐ | Emulować nagłówki przeglądarki. |
| Max redirects count | 7 | Maksymalna liczba przekierowań, po których będzie przechodził scraper. |
| Max cookies count | 16 | Maksymalna liczba plików cookies do zapisania. |
| Bypass CloudFlare | ☑ | Automatyczne omijanie weryfikacji CloudFlare. |
| Follow common redirects | ☑ | Pozwala na przekierowania http <-> https oraz www.domain <-> domain w obrębie jednej domeny z pominięciem limitu Max redirects count. |
| Engine | HTTP (Fast, JavaScript Disabled) | Pozwala wybrać silnik HTTP (szybszy, bez JavaScript) lub Chrome (wolniejszy, JavaScript włączony). |
| Chrome Headless | ☐ | Jeśli opcja jest włączona, przeglądarka nie będzie wyświetlana. |
| Chrome DevTools | ☑ | Pozwala używać narzędzi do debugowania Chromium. |
| Chrome Log Proxy connections | ☑ | Jeśli opcja jest włączona, w logu będą wyświetlane informacje o połączeniach chrome. |
| Chrome Wait Until | networkidle2 | Określa, kiedy strona jest uznawana za załadowaną. Więcej o wartościach. |
| Use HTTP/2 transport | ☐ | Określa, czy używać HTTP/2 zamiast HTTP/1.1. Na przykład Google i Majestic natychmiast banują, jeśli używa się HTTP/1.1. |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Omijanie CF przez Chrome. |
| Bypass CloudFlare with Chrome Max Pages | Maks. liczba stron przy omijaniu CF przez Chrome. |