HTML::TextExtractor - 从网站抓取内容(文本)
爬虫工具概览
 HTML::TextExtractor 从指定页面抓取文本块。该内容爬虫工具支持多页抓取(翻页)。内置绕过 CloudFlare 防护的手段,并可选择 Chrome 作为引擎,用于抓取通过脚本加载数据的页面内容。速度最高可达每分钟 2000 次请求,即每小时 120 000 个链接。
HTML::TextExtractor 从指定页面抓取文本块。该内容爬虫工具支持多页抓取(翻页)。内置绕过 CloudFlare 防护的手段,并可选择 Chrome 作为引擎,用于抓取通过脚本加载数据的页面内容。速度最高可达每分钟 2000 次请求,即每小时 120 000 个链接。爬虫工具应用案例
以 lingualeo.com 为例通过 Chrome 进行文本数据抓取
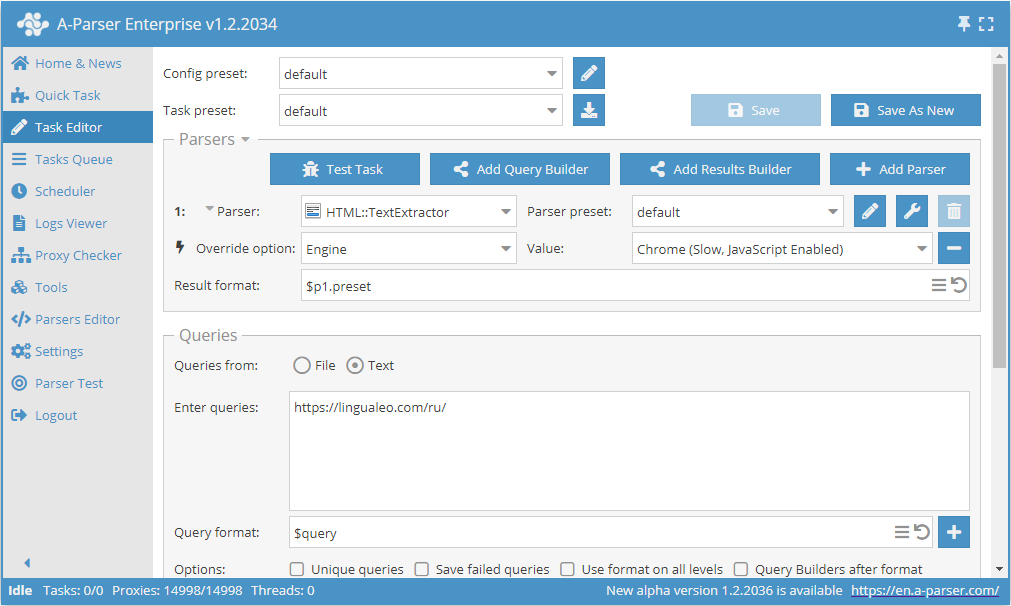
- 添加 Engine 选项,在列表中选择引擎
Chrome (Slow, JavaScript Enabled)。 - 在查询中指定需要抓取文本的网站链接。
备注
当网站在页面加载过程中通过脚本加载正文,且在使用 HTTP (Fast, JavaScript Disabled) 时结果缺失或不完整,此选项非常有用。
下载示例
eJxtU01v2zAM/S9EDhsQJO1hF9/SYME6pHXXpqcgB8GmXa2ypOkjS2Hkv+/Jce2k
680kHx8fxeeWgvCv/sGx5+Ap27Zku2/KqORKRBVoSlY4zy6Vt/Rjc7fOsg0fwvdD
cKIIxgExYFsKb5bRbfbsnCwZRVkiZl1LnaK9UDEBihdnGqbjbjcljES3XxnXiDR6
Yq9nvY6h+CT2vDEoVlLxmF4huhdNYpyUInCqzqqO6MvXWTgkBlGWMkijhTpNSJuM
U5+1/NMp8sFJXQOP0En2KwhEOnBHkpJv7wq3NOliAk3s+n+deigLLvKUPNSuBLSU
Q6ESyqMiAzuBV8ttkoR8S0YvlFrzntUI6+hvolQlXn5Roem2b/wckv/HcRw2PB+F
s/x10DCwdNFNfjd2lWZtaiyuDdZWspEBsV+aqNNtrpB8ZbbDs90nWGMcD2N65n46
zGVZJw+MV1vYMXWxxsVlLpOF0ZWs895X78ioN3BwrpemsYrTXjoqhat4fhwdsvD9
GVIwCvzYvOxGXHg/GKP8z6eTVOskHPgtCWzwkudTe8pCKPX8uD6v0OgoBC8hWJ/N
5wpWi0KxmRWmmbs4p9QcuDZwFVY77ob/bvg720//vqw94mi//cMJnTZMWOTwVB4X
oez6+A9VbWHX
以新闻网站为例进行带翻页的文本数据抓取
结果保存在 aparser/results/example/textextractor 目录中,每个查询对应一个单独的文件。文件名使用查询的序列号。
- 添加 Check next page 选项,正则表达式指定为
(forum\/news\/page-\d+)"[^>]+>下一页。 - 添加 Page as new query 选项。
- 将 File name (文件名) 修改为
example/textextractor/${query.num}.txt。 - 在查询中指定 A-Parser 新闻的第一页链接:
https://a-parser.com/forum/news/。
下载示例
eJx1VN1v2jAQ/18sHjaVEtjoSx4qUVS0TRRoS58Ik6zkQj0c27UdPhTlf9/ZCQmw
7sXJne/jd7+7c0EsNVuz0GDAGhKuCqL8PwnJ44FmikMYLuFgHw9W09hKHYYzFBd0
A6RLFNUGtPNbkR/Lp+mVLVokkNKcW9ItiD0qwLBSWSaFwTuWoBi/Q7w9C7mjPHdm
X1Kp8yyKAgF7gx+F17dRlNx8jcjq9/365j7K+8PBN3d+T/15585h3513A68ZYkCa
JMxlpJyExWW6KcuYq7RPyvK/AF3ikZnB/jkHfWwRWp3DdfQtgPJmU9gBavpluV53
CTKKHJiJ1Bl1+Tpq0Ktpbi5f6Q6WEi9TxqFVT1Ca0czhgqofgUX0cKI46BQfLmFP
5FnZswd7UXGV0fWnRfEm2IdnWEi0dc4MzETLDFUubq08ntCuSMfLBEPk3ve58iFh
SrlBDgxCn1AEmlzfMAuaIsp5TSlSJMWIc09Pa+bjP+SMJzhMoxSdftaOn5vM/4lR
NuWdp9qB3mvE0ETx0sP8qfVK5FRuTmRwNw8om7HMRTUYXd/ThrOZM8ukhiZNHbnO
joukQLixaVs4Uq3qooyLtlwqYylStpljAZolcLLMxRK3dS7G0g2Cq0vknGNbDLy0
4zIydRuc0AK8dh77FAirWVFipeTm12sFVWmG43jnAGbI5HnWOmRMOX97mZ7fkHak
UHi3VpkwCOht9VD0YpkFfq/9VgfExbCwkThdWGG5bl6U5kEqPn1XwgIXlvwxi8ra
FepsUYeMGWwMCQflX6y1tO0=
采集数据
- 从指定页面抓取文本块
- 包含所有采集页面的数组(在使用 Use Pages 选项时使用)
功能
- 多页文本数据抓取(翻页)
- 自动清除文本中的 HTML 标签
- 可设置文本块的最小长度
- 可选删除文本中的链接锚点
- 支持 gzip/deflate/brotli 压缩
- 识别并将网站编码转换为 UTF-8
- 绕过 CloudFlare 防护
- 引擎选择(HTTP 或 Chrome)
使用场景
- 从任何网站抓取文本内容
查询
查询中必须指定需要抓取文本块的页面链接,例如:
https://a-parser.com/
结果输出示例
A-Parser 凭借内置的 Template Toolkit 模板引擎支持灵活的结果格式化,允许以任意形式以及结构化形式(如 CSV 或 JSON)输出结果。
默认输出
结果格式:
$texts.format('$text\n')
结果示例:
您好,各领域顶尖专业人士组成的超级团队!感谢你们提供学习西班牙语、土耳其语和葡萄牙语的机会!祝愿你们的功能进一步扩展!充满灵感与创造力!并请求增加学习德语和法语的机会!”
我已经使用 Lingualeo 很多年了,第一次开始学习时甚至还没有应用程序,只有网站)感谢开发者,请继续保持这种创意和对事业的热爱)
IT 技术英语:词典、教材、杂志
在线学习语言 在线学习英语 在线学习越南语 在线学习希腊语 在线学习印尼语 在线学习西班牙语 在线学习意大利语 在线学习中文 在线学习韩语 在线学习德语 在线学习荷兰语 在线学习波兰语 在线学习葡萄牙语 在线学习塞尔维亚语 在线学习土耳其语 在线学习乌克兰语 在线学习法语 在线学习印地语 在线学习捷克语 在线学习日语
可选设置
| 参数名称 | 默认值 | 描述 |
|---|---|---|
| Min block length | 50 | 文本块的最小字符长度。 |
| Skip anchor text | ☐ | 是否忽略文本中的锚点。 |
| Ignore tags list | 用于指定需要忽略的标签。示例:div,span,p | |
| Good status | All | 选择哪些服务器响应被视为成功。如果数据抓取时收到其他响应,将使用另一个代理重试请求。 |
| Good code RegEx | 可指定用于检查响应代码的正则表达式。 | |
| Method | GET | 请求方法。 |
| POST body | 使用 POST 方法时发送到服务器的内容。支持变量 $query – 请求 URL,$query.orig – 原始查询,以及在使用 Use Pages 选项时的 $pagenum – 页码。 | |
| Cookies | 可为请求指定 cookies。 | |
| User agent | `_自动填充当前版本 Chrome 的 user-agent_ | 请求页面时的 User-Agent 请求头。 |
| Additional headers | 可指定自定义请求头,支持模板引擎功能并可使用请求构造器中的变量。 | |
| Read only headers | ☐ | 仅读取响应头。在无需处理内容的情况下可节省流量。 |
| Detect charset on content | ☐ | 根据页面内容识别编码。 |
| Emulate browser headers | ☐ | 模拟浏览器请求头。 |
| Max redirects count | 7 | 爬虫工具将跟随的最大重定向次数。 |
| Max cookies count | 16 | 要保存的最大 cookies 数量。 |
| Bypass CloudFlare | ☑ | 自动绕过 CloudFlare 检查。 |
| Follow common redirects | ☑ | 允许在同一域名内绕过 Max redirects count 限制进行 http <-> https 和 www.domain <-> domain 的重定向。 |
| Engine | HTTP (Fast, JavaScript Disabled) | 允许选择 HTTP 引擎(更快,无 JavaScript)或 Chrome 引擎(较慢,启用 JavaScript)。 |
| Chrome Headless | ☐ | 如果启用此选项,浏览器将不会显示。 |
| Chrome DevTools | ☑ | 允许使用 Chromium 调试工具。 |
| Chrome Log Proxy connections | ☑ | 如果启用此选项,日志中将输出 chrome 连接信息。 |
| Chrome Wait Until | networkidle2 | 定义何时认为页面已加载。查看详情。 |
| Use HTTP/2 transport | ☐ | 定义是否使用 HTTP/2 代替 HTTP/1.1。例如,如果使用 HTTP/1.1,Google 和 Majestic 会立即封禁。 |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | 通过 Chrome 绕过 CF。 |
| Bypass CloudFlare with Chrome Max Pages | 通过 Chrome 绕过 CF 时的最大页数。 |