HTML::TextExtractor - サイトからのコンテンツ(テキスト)スクレイピング
スクレイパーの概要
 HTML::TextExtractor は指定されたページからテキストブロックをスクレイピングします。このコンテンツスクレイパーはマルチページスクレイピング(ページ遷移)をサポートしています。組み込みの CloudFlare 回避機能を備えており、またスクリプトでデータが読み込まれるページのコンテンツをスクレイピングするために Chrome をエンジンとして選択することも可能です。最大で毎分 2000 リクエスト、つまり1時間あたり 120,000 リンクの速度を実現可能です。
HTML::TextExtractor は指定されたページからテキストブロックをスクレイピングします。このコンテンツスクレイパーはマルチページスクレイピング(ページ遷移)をサポートしています。組み込みの CloudFlare 回避機能を備えており、またスクリプトでデータが読み込まれるページのコンテンツをスクレイピングするために Chrome をエンジンとして選択することも可能です。最大で毎分 2000 リクエスト、つまり1時間あたり 120,000 リンクの速度を実現可能です。スクレイパーのユースケース
lingualeo.comを例としたChrome経由のテキストスクレイピング
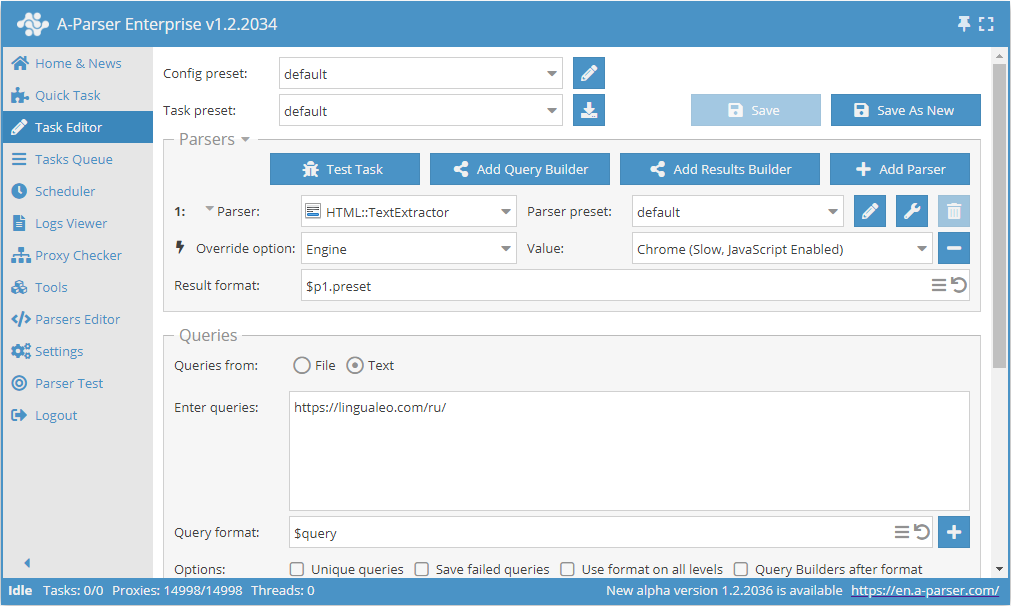
- Engine オプションを追加し、リストからエンジン
Chrome (Slow, JavaScript Enabled)を選択します。 - クエリとして、テキストをスクレイピングしたいサイトのリンクを指定します。
注記
このオプションは、サイトがページの読み込み中にスクリプトでメインテキストを読み込む場合や、HTTP (Fast, JavaScript Disabled) を使用した際に結果が得られない、または不完全な場合に役立ちます。
サンプルをダウンロード
eJxtU01v2zAM/S9EDhsQJO1hF9/SYME6pHXXpqcgB8GmXa2ypOkjS2Hkv+/Jce2k
680kHx8fxeeWgvCv/sGx5+Ap27Zku2/KqORKRBVoSlY4zy6Vt/Rjc7fOsg0fwvdD
cKIIxgExYFsKb5bRbfbsnCwZRVkiZl1LnaK9UDEBihdnGqbjbjcljES3XxnXiDR6
Yq9nvY6h+CT2vDEoVlLxmF4huhdNYpyUInCqzqqO6MvXWTgkBlGWMkijhTpNSJuM
U5+1/NMp8sFJXQOP0En2KwhEOnBHkpJv7wq3NOliAk3s+n+deigLLvKUPNSuBLSU
Q6ESyqMiAzuBV8ttkoR8S0YvlFrzntUI6+hvolQlXn5Roem2b/wckv/HcRw2PB+F
s/x10DCwdNFNfjd2lWZtaiyuDdZWspEBsV+aqNNtrpB8ZbbDs90nWGMcD2N65n46
zGVZJw+MV1vYMXWxxsVlLpOF0ZWs895X78ioN3BwrpemsYrTXjoqhat4fhwdsvD9
GVIwCvzYvOxGXHg/GKP8z6eTVOskHPgtCWzwkudTe8pCKPX8uD6v0OgoBC8hWJ/N
5wpWi0KxmRWmmbs4p9QcuDZwFVY77ob/bvg720//vqw94mi//cMJnTZMWOTwVB4X
oez6+A9VbWHX
ニュースを例としたページ遷移を伴うテキストスクレイピング
結果は aparser/results/example/textextractor ディレクトリに、クエリごとに個別のファイルとして保存されます。ファイル名にはクエリの連番が指定されます。
- Check next page オプションを追加し、正規表現として
(forum\/news\/page-\d+)"[^>]+>次へを指定します。 - Page as new query オプションを追加します。
- File name (ファイル名) を
example/textextractor/${query.num}.txtに変更します。 - クエリとして A-Parser ニュースの最初のページへのリンクを指定します:
https://a-parser.com/forum/news/。
サンプルをダウンロード
eJx1VN1v2jAQ/18sHjaVEtjoSx4qUVS0TRRoS58Ik6zkQj0c27UdPhTlf9/ZCQmw
7sXJne/jd7+7c0EsNVuz0GDAGhKuCqL8PwnJ44FmikMYLuFgHw9W09hKHYYzFBd0
A6RLFNUGtPNbkR/Lp+mVLVokkNKcW9ItiD0qwLBSWSaFwTuWoBi/Q7w9C7mjPHdm
X1Kp8yyKAgF7gx+F17dRlNx8jcjq9/365j7K+8PBN3d+T/15585h3513A68ZYkCa
JMxlpJyExWW6KcuYq7RPyvK/AF3ikZnB/jkHfWwRWp3DdfQtgPJmU9gBavpluV53
CTKKHJiJ1Bl1+Tpq0Ktpbi5f6Q6WEi9TxqFVT1Ca0czhgqofgUX0cKI46BQfLmFP
5FnZswd7UXGV0fWnRfEm2IdnWEi0dc4MzETLDFUubq08ntCuSMfLBEPk3ve58iFh
SrlBDgxCn1AEmlzfMAuaIsp5TSlSJMWIc09Pa+bjP+SMJzhMoxSdftaOn5vM/4lR
NuWdp9qB3mvE0ETx0sP8qfVK5FRuTmRwNw8om7HMRTUYXd/ThrOZM8ukhiZNHbnO
joukQLixaVs4Uq3qooyLtlwqYylStpljAZolcLLMxRK3dS7G0g2Cq0vknGNbDLy0
4zIydRuc0AK8dh77FAirWVFipeTm12sFVWmG43jnAGbI5HnWOmRMOX97mZ7fkHak
UHi3VpkwCOht9VD0YpkFfq/9VgfExbCwkThdWGG5bl6U5kEqPn1XwgIXlvwxi8ra
FepsUYeMGWwMCQflX6y1tO0=
収集データ
- 指定されたページからテキストブロックをスクレイピングします
- 収集されたすべてのページの配列 (Use Pages オプション使用時に利用)
機能
- 複数ページのテキストスクレイピング(ページ遷移)
- HTMLタグからのテキスト自動クリーニング
- テキストブロックの最小長を指定可能
- テキストからのリンクアンカーのオプション削除
- gzip/deflate/brotli 圧縮をサポート
- サイトのエンコーディングを判定し UTF-8 へ変換
- CloudFlare 保護の回避
- エンジンの選択 (HTTP または Chrome)
ユースケース
- あらゆるサイトからのテキストコンテンツのスクレイピング
クエリ
クエリとして、テキストブロックをスクレイピングしたいページのリンクを指定する必要があります。例:
https://a-parser.com/
結果の出力例
A-Parserは内蔵のテンプレートエンジン Template Toolkit により柔軟な結果のフォーマットをサポートしており、任意の形式や、CSVやJSONなどの構造化された形式で結果を出力できます。
デフォルト出力
結果フォーマット:
$texts.format('$text\n')
結果の例:
こんにちは、最高のプロフェッショナルチームの皆さん!スペイン語、トルコ語、ポルトガル語を学ぶ機会をありがとうございます!皆さんの可能性がさらに広がることを願っています!インスピレーションと創造性を!そして、ドイツ語とフランス語を学ぶ機能も追加してほしいです!”
長年Lingualeoを使っています。アプリが全くなかったサイトだけの頃から始めました。開発者の皆さん、ありがとうございます。創造性と愛を持って、そのまま続けてください。
IT向けテクニカル英語:辞書、教科書、雑誌
オンラインで言語を学ぶ オンラインで英語を学ぶ オンラインでベトナム語を学ぶ オンラインでギリシャ語を学ぶ オンラインでインドネシア語を学ぶ オンラインでスペイン語を学ぶ オンラインでイタリア語を学ぶ オンラインで中国語を学ぶ オンラインで韓国語を学ぶ オンラインでドイツ語を学ぶ オンラインでオランダ語を学ぶ オンラインでポーランド語を学ぶ オンラインでポルトガル語を学ぶ オンラインでセルビア語を学ぶ オンラインでトルコ語を学ぶ オンラインでウクライナ語を学ぶ オンラインでフランス語を学ぶ オンラインでヒンディー語を学ぶ オンラインでチェコ語を学ぶ オンラインで日本語を学ぶ
設定可能な項目
| パラメータ名 | デフォルト値 | 説明 |
|---|---|---|
| Min block length | 50 | テキストブロックの最小文字数。 |
| Skip anchor text | ☐ | テキスト内のアンカーをスキップするかどうか。 |
| Ignore tags list | 無視するタグを指定するオプション。指定例: div,span,p | |
| Good status | All | サーバーからのどのレスポンスを成功と見なすかを選択します。スクレイピング中に別のレスポンスがあった場合、別のプロキシでリクエストが再試行されます。 |
| Good code RegEx | レスポンスコードを確認するための正規表現を指定できます。 | |
| Method | GET | リクエストメソッド。 |
| POST body | POSTメソッド使用時にサーバーに送信するコンテンツ。変数 $query(リクエストURL)、$query.orig(元のクエリ)、$pagenum(Use Pages オプション使用時のページ番号)をサポートしています。 | |
| Cookies | リクエストに使用するCookieを指定できます。 | |
| User agent | `_最新バージョンのChromeのUser-Agentが自動的に設定されます_ | ページリクエスト時の User-Agent ヘッダー。 |
| Additional headers | テンプレートエンジンの機能やクエリコンストラクタの変数を使用して、任意のカスタムリクエストヘッダーを指定できます。 | |
| Read only headers | ☐ | ヘッダーのみを読み取ります。コンテンツを処理する必要がない場合、トラフィックを節約できることがあります。 |
| Detect charset on content | ☐ | ページの内容に基づいてエンコーディングを認識します。 |
| Emulate browser headers | ☐ | ブラウザのヘッダーをエミュレートします。 |
| Max redirects count | 7 | スクレイパーが追跡する最大リダイレクト数。 |
| Max cookies count | 16 | 保存するCookieの最大数。 |
| Bypass CloudFlare | ☑ | CloudFlareのチェックを自動的に回避します。 |
| Follow common redirects | ☑ | 同一ドメイン内での http <-> https および www.domain <-> domain のリダイレクトを、Max redirects count の制限を無視して許可します。 |
| Engine | HTTP (Fast, JavaScript Disabled) | HTTP(高速、JavaScriptなし)またはChrome(低速、JavaScript有効)のエンジンを選択できます。 |
| Chrome Headless | ☐ | 有効にすると、ブラウザは表示されません。 |
| Chrome DevTools | ☑ | Chromiumのデバッグツールを使用できるようにします。 |
| Chrome Log Proxy connections | ☑ | 有効にすると、Chromeの接続に関する情報がログに出力されます。 |
| Chrome Wait Until | networkidle2 | ページがいつ読み込まれたと見なすかを定義します。値の詳細。 |
| Use HTTP/2 transport | ☐ | HTTP/1.1の代わりにHTTP/2を使用するかどうかを定義します。例えば、GoogleやMajesticはHTTP/1.1を使用すると即座にブロックします。 |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Chrome経由でCloudFlareを回避します。 |
| Bypass CloudFlare with Chrome Max Pages | Chrome経由でCloudFlareを回避する際の最大ページ数。 |