HTML::TextExtractor - Scraping di contenuti (testo) da siti web
Panoramica dello scraper
 HTML::TextExtractor estrae blocchi di testo dalla pagina specificata. Questo scraper di contenuti supporta lo scraping multipagina (navigazione tra le pagine). Dispone di strumenti integrati per il bypass della protezione CloudFlare e anche la possibilità di scegliere Chrome come motore per lo scraping di contenuti dalle pagine in cui i dati vengono caricati tramite script. È in grado di raggiungere una velocità fino a 2000 richieste al minuto – ovvero 120 000 link all'ora.
HTML::TextExtractor estrae blocchi di testo dalla pagina specificata. Questo scraper di contenuti supporta lo scraping multipagina (navigazione tra le pagine). Dispone di strumenti integrati per il bypass della protezione CloudFlare e anche la possibilità di scegliere Chrome come motore per lo scraping di contenuti dalle pagine in cui i dati vengono caricati tramite script. È in grado di raggiungere una velocità fino a 2000 richieste al minuto – ovvero 120 000 link all'ora.Casi d'uso dello scraper
Scraping di testo tramite Chrome sull'esempio di lingualeo.com
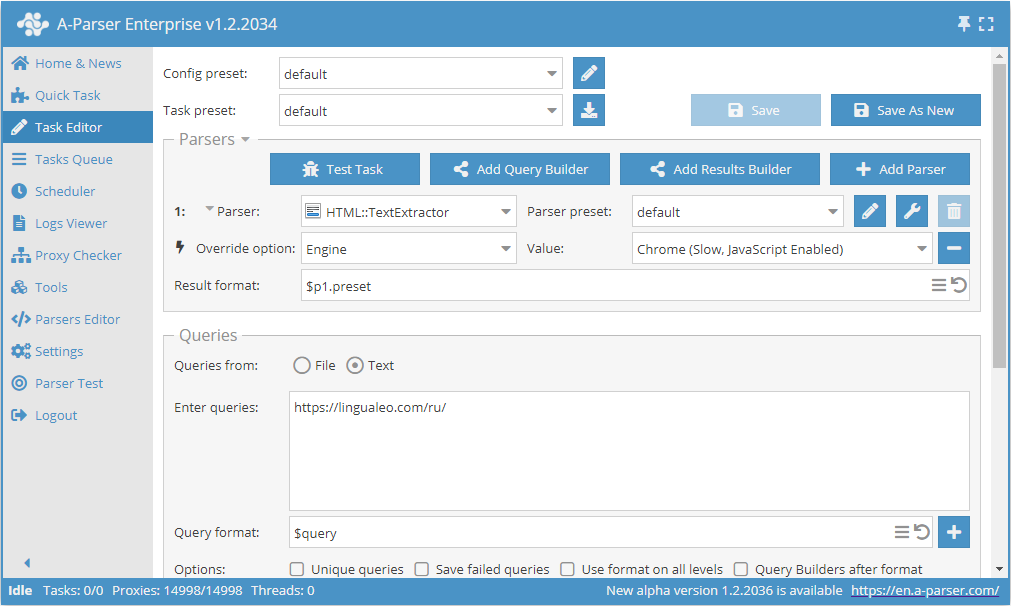
- Aggiungere l'opzione Engine, nell'elenco selezionare il motore
Chrome (Slow, JavaScript Enabled). - Come query, indicare il link al sito da cui si desidera estrarre il testo.
Questa opzione può essere utile nei casi in cui il sito carica il testo principale tramite script durante il caricamento della pagina e, utilizzando HTTP (Fast, JavaScript Disabled), il risultato è assente o incompleto.
Scarica esempio
Come importare un esempio in A-Parser
eJxtU01v2zAM/S9EDhsQJO1hF9/SYME6pHXXpqcgB8GmXa2ypOkjS2Hkv+/Jce2k
680kHx8fxeeWgvCv/sGx5+Ap27Zku2/KqORKRBVoSlY4zy6Vt/Rjc7fOsg0fwvdD
cKIIxgExYFsKb5bRbfbsnCwZRVkiZl1LnaK9UDEBihdnGqbjbjcljES3XxnXiDR6
Yq9nvY6h+CT2vDEoVlLxmF4huhdNYpyUInCqzqqO6MvXWTgkBlGWMkijhTpNSJuM
U5+1/NMp8sFJXQOP0En2KwhEOnBHkpJv7wq3NOliAk3s+n+deigLLvKUPNSuBLSU
Q6ESyqMiAzuBV8ttkoR8S0YvlFrzntUI6+hvolQlXn5Roem2b/wckv/HcRw2PB+F
s/x10DCwdNFNfjd2lWZtaiyuDdZWspEBsV+aqNNtrpB8ZbbDs90nWGMcD2N65n46
zGVZJw+MV1vYMXWxxsVlLpOF0ZWs895X78ioN3BwrpemsYrTXjoqhat4fhwdsvD9
GVIwCvzYvOxGXHg/GKP8z6eTVOskHPgtCWzwkudTe8pCKPX8uD6v0OgoBC8hWJ/N
5wpWi0KxmRWmmbs4p9QcuDZwFVY77ob/bvg720//vqw94mi//cMJnTZMWOTwVB4X
oez6+A9VbWHX
Scraping di testo con navigazione tra le pagine sull'esempio delle notizie
I risultati vengono salvati nella directory aparser/results/example/textextractor in un file separato per ogni query. Come nome viene indicato il numero d'ordine della query.
- Aggiungere l'opzione Check next page, come espressione regolare indicare
(forum\/news\/page-\d+)"[^>]+>Avanti. - Aggiungere l'opzione Page as new query.
- Cambiare il File name (Nome file) in
example/textextractor/${query.num}.txt. - Come query, indicare il link alla prima pagina delle notizie di A-Parser:
https://a-parser.com/forum/news/.
Scarica esempio
Come importare un esempio in A-Parser
eJx1VN1v2jAQ/18sHjaVEtjoSx4qUVS0TRRoS58Ik6zkQj0c27UdPhTlf9/ZCQmw
7sXJne/jd7+7c0EsNVuz0GDAGhKuCqL8PwnJ44FmikMYLuFgHw9W09hKHYYzFBd0
A6RLFNUGtPNbkR/Lp+mVLVokkNKcW9ItiD0qwLBSWSaFwTuWoBi/Q7w9C7mjPHdm
X1Kp8yyKAgF7gx+F17dRlNx8jcjq9/365j7K+8PBN3d+T/15585h3513A68ZYkCa
JMxlpJyExWW6KcuYq7RPyvK/AF3ikZnB/jkHfWwRWp3DdfQtgPJmU9gBavpluV53
CTKKHJiJ1Bl1+Tpq0Ktpbi5f6Q6WEi9TxqFVT1Ca0czhgqofgUX0cKI46BQfLmFP
5FnZswd7UXGV0fWnRfEm2IdnWEi0dc4MzETLDFUubq08ntCuSMfLBEPk3ve58iFh
SrlBDgxCn1AEmlzfMAuaIsp5TSlSJMWIc09Pa+bjP+SMJzhMoxSdftaOn5vM/4lR
NuWdp9qB3mvE0ETx0sP8qfVK5FRuTmRwNw8om7HMRTUYXd/ThrOZM8ukhiZNHbnO
joukQLixaVs4Uq3qooyLtlwqYylStpljAZolcLLMxRK3dS7G0g2Cq0vknGNbDLy0
4zIydRuc0AK8dh77FAirWVFipeTm12sFVWmG43jnAGbI5HnWOmRMOX97mZ7fkHak
UHi3VpkwCOht9VD0YpkFfq/9VgfExbCwkThdWGG5bl6U5kEqPn1XwgIXlvwxi8ra
FepsUYeMGWwMCQflX6y1tO0=
Dati raccolti
- Estrae blocchi di testo dalla pagina specificata
- Array con tutte le pagine raccolte (utilizzato quando l'opzione Use Pages è attiva)
Funzionalità
- Scraping di testo multipagina (navigazione tra le pagine)
- Pulizia automatica del testo dai tag HTML
- Possibilità di impostare la lunghezza minima del blocco di testo
- Rimozione opzionale degli anchor di collegamento dal testo
- Supporta la compressione gzip/deflate/brotli
- Rilevamento e conversione della codifica dei siti in UTF-8
- Bypass della protezione CloudFlare
- Scelta del motore (HTTP o Chrome)
Casi d'uso
- Scraping di contenuti testuali da qualsiasi sito
Query
Come query è necessario indicare i link alle pagine da cui si desidera estrarre i blocchi di testo, ad esempio:
https://a-parser.com/
Esempi di output dei risultati
A-Parser supporta una formattazione flessibile dei risultati grazie al motore di modelli integrato Template Toolkit, che gli consente di produrre risultati in forma libera o strutturata, come CSV o JSON
Output predefinito
Formato del risultato:
$texts.format('$text\n')
Esempio di risultato:
Salve, Super Team di Massimi Professionisti del proprio Settore! Grazie per l'opportunità di studiare lo spagnolo, il turco e il portoghese! Vi auguro un ulteriore ampliamento delle vostre possibilità! Ispirazione e creatività! E una richiesta di aggiungere la possibilità di studiare il tedesco e il francese!”
Utilizzo Lingualeo già da molti anni, ho iniziato a studiare la prima volta quando l'applicazione non esisteva affatto, c'era solo il sito) Grazie agli sviluppatori, continuate così, con creatività e con un grande amore per il vostro lavoro)
Inglese tecnico per l'IT: dizionari, manuali, riviste
Impara le lingue online Impara l'inglese online Impara il vietnamita online Impara il greco online Impara l'indonesiano online Impara lo spagnolo online Impara l'italiano online Impara il cinese online Impara il coreano online Impara il tedesco online Impara l'olandese online Impara il polacco online Impara il portoghese online Impara il serbo online Impara il turco online Impara l'ucraino online Impara il francese online Impara l'hindi online Impara il ceco online Impara il giapponese online
Impostazioni possibili
| Nome parametro | Valore predefinito | Descrizione |
|---|---|---|
| Min block length | 50 | Lunghezza minima del blocco di testo in caratteri. |
| Skip anchor text | ☐ | Se saltare gli anchor nel testo. |
| Ignore tags list | Opzione per specificare i tag da ignorare. Esempio: div,span,p | |
| Good status | All | Scelta di quale risposta dal server sarà considerata corretta. Se durante lo scraping si riceve una risposta diversa, la query verrà ripetuta con un altro proxy. |
| Good code RegEx | Possibilità di specificare un'espressione regolare per controllare il codice di risposta. | |
| Method | GET | Metodo della richiesta. |
| POST body | Contenuto da inviare al server quando si utilizza il metodo POST. Supporta le variabili $query – URL della richiesta, $query.orig – query originale e $pagenum - numero della pagina quando si utilizza l'opzione Use Pages. | |
| Cookies | Possibilità di specificare i cookie per la richiesta. | |
| User agent | `_Viene inserito automaticamente lo user-agent della versione attuale di Chrome_ | Intestazione User-Agent per la richiesta delle pagine. |
| Additional headers | Possibilità di specificare intestazioni di richiesta arbitrarie con supporto alle funzionalità del motore di modelli e utilizzo di variabili dal costruttore di query. | |
| Read only headers | ☐ | Leggere solo le intestazioni. In alcuni casi permette di risparmiare traffico se non è necessario elaborare il contenuto. |
| Detect charset on content | ☐ | Riconoscere la codifica in base al contenuto della pagina. |
| Emulate browser headers | ☐ | Emulare le intestazioni del browser. |
| Max redirects count | 7 | Numero massimo di reindirizzamenti che lo scraper seguirà. |
| Max cookies count | 16 | Numero massimo di cookie da salvare. |
| Bypass CloudFlare | ☑ | Bypass automatico del controllo CloudFlare. |
| Follow common redirects | ☑ | Permette di effettuare reindirizzamenti http <-> https e www.domain <-> domain all'interno dello stesso dominio ignorando il limite Max redirects count. |
| Engine | HTTP (Fast, JavaScript Disabled) | Permette di scegliere il motore HTTP (più veloce, senza JavaScript) o Chrome (più lento, JavaScript abilitato). |
| Chrome Headless | ☐ | Se l'opzione è attiva, il browser non verrà visualizzato. |
| Chrome DevTools | ☑ | Permette di utilizzare gli strumenti di debug di Chromium. |
| Chrome Log Proxy connections | ☑ | Se l'opzione è attiva, nel log verranno visualizzate le informazioni sulle connessioni chrome. |
| Chrome Wait Until | networkidle2 | Definisce quando la pagina è considerata caricata. Dettagli sui valori. |
| Use HTTP/2 transport | ☐ | Definisce se utilizzare HTTP/2 invece di HTTP/1.1. Ad esempio, Google e Majestic bannano immediatamente se si utilizza HTTP/1.1. |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Bypass di CF tramite Chrome. |
| Bypass CloudFlare with Chrome Max Pages | Numero massimo di pagine durante il bypass di CF tramite Chrome. |