HTML::TextExtractor - Siteden içerik (metin) veri çekme
Veri kazıyıcı incelemesi
 HTML::TextExtractor belirtilen sayfadaki metin bloklarını kazır. Bu içerik veri kazıyıcı, çok sayfalı veri çekmeyi (sayfalar arası geçiş) destekler. Yerleşik koruma atlatma araçlarına sahiptir CloudFlare ve ayrıca seçim yapma imkanı sunar Chrome verilerin scriptlerle yüklendiği sayfalardan içerik çekmek için motor olarak. Şu hıza kadar çıkabilir: 2000 dakikada sorgu – bu da 120 000 saatte bağlantı demektir.
HTML::TextExtractor belirtilen sayfadaki metin bloklarını kazır. Bu içerik veri kazıyıcı, çok sayfalı veri çekmeyi (sayfalar arası geçiş) destekler. Yerleşik koruma atlatma araçlarına sahiptir CloudFlare ve ayrıca seçim yapma imkanı sunar Chrome verilerin scriptlerle yüklendiği sayfalardan içerik çekmek için motor olarak. Şu hıza kadar çıkabilir: 2000 dakikada sorgu – bu da 120 000 saatte bağlantı demektir.Veri kazıyıcı kullanım örnekleri
lingualeo.com örneğinde Chrome üzerinden metin veri çekme
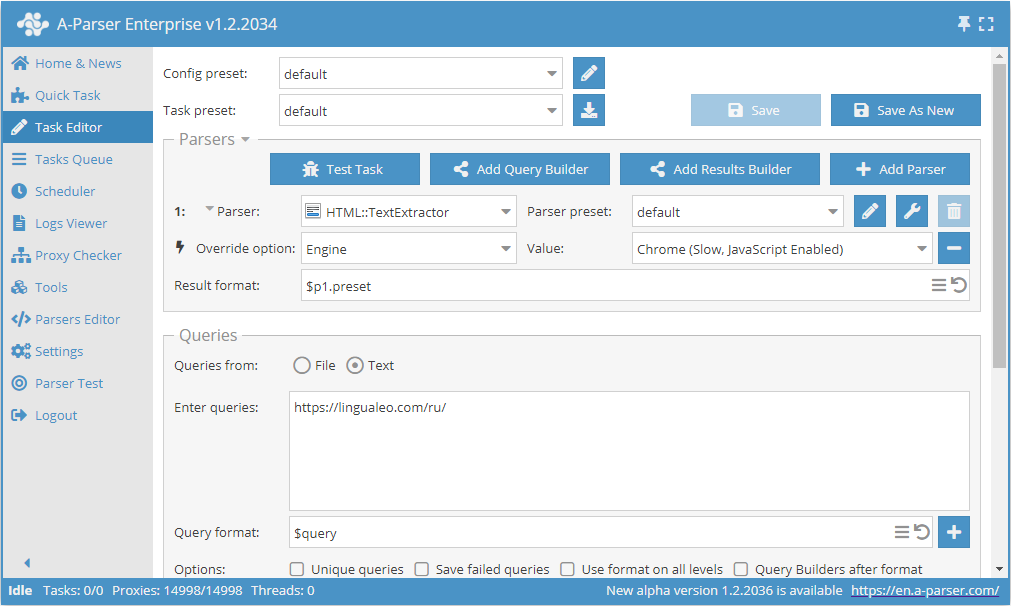
- Engine seçeneğini ekleyin, listeden
Chrome (Slow, JavaScript Enabled)motorunu seçin. - Sorgu olarak, metin çekmek istediğiniz web sitesinin bağlantısını belirtin.
Bu seçenek, web sitesinin ana metni sayfa yüklenirken scriptlerle yüklediği ve HTTP (Fast, JavaScript Disabled) kullanıldığında sonucun eksik olduğu veya hiç olmadığı durumlarda yararlı olabilir.
Örneği indir
Nasıl A-Parser örnek içe aktarılır
eJxtU01v2zAM/S9EDhsQJO1hF9/SYME6pHXXpqcgB8GmXa2ypOkjS2Hkv+/Jce2k
680kHx8fxeeWgvCv/sGx5+Ap27Zku2/KqORKRBVoSlY4zy6Vt/Rjc7fOsg0fwvdD
cKIIxgExYFsKb5bRbfbsnCwZRVkiZl1LnaK9UDEBihdnGqbjbjcljES3XxnXiDR6
Yq9nvY6h+CT2vDEoVlLxmF4huhdNYpyUInCqzqqO6MvXWTgkBlGWMkijhTpNSJuM
U5+1/NMp8sFJXQOP0En2KwhEOnBHkpJv7wq3NOliAk3s+n+deigLLvKUPNSuBLSU
Q6ESyqMiAzuBV8ttkoR8S0YvlFrzntUI6+hvolQlXn5Roem2b/wckv/HcRw2PB+F
s/x10DCwdNFNfjd2lWZtaiyuDdZWspEBsV+aqNNtrpB8ZbbDs90nWGMcD2N65n46
zGVZJw+MV1vYMXWxxsVlLpOF0ZWs895X78ioN3BwrpemsYrTXjoqhat4fhwdsvD9
GVIwCvzYvOxGXHg/GKP8z6eTVOskHPgtCWzwkudTe8pCKPX8uD6v0OgoBC8hWJ/N
5wpWi0KxmRWmmbs4p9QcuDZwFVY77ob/bvg720//vqw94mi//cMJnTZMWOTwVB4X
oez6+A9VbWHX
Haber örneğinde sayfalar arası geçiş yaparak metin veri çekme
Sonuçlar, her sorgu için ayrı bir dosya halinde aparser/results/example/textextractor dizinine kaydedilir. Dosya adı olarak sorgunun sıra numarası kullanılır.
- Check next page seçeneğini ekleyin, düzenli ifade (regex) olarak
(forum\/news\/page-\d+)"[^>]+>İleribelirtin. - Page as new query seçeneğini ekleyin.
- File name (Dosya adı) kısmını
example/textextractor/${query.num}.txtolarak değiştirin. - Sorgu olarak A-Parser haberlerinin ilk sayfa bağlantısını belirtin:
https://a-parser.com/forum/news/.
Örneği indir
Nasıl A-Parser örnek içe aktarılır
eJx1VN1v2jAQ/18sHjaVEtjoSx4qUVS0TRRoS58Ik6zkQj0c27UdPhTlf9/ZCQmw
7sXJne/jd7+7c0EsNVuz0GDAGhKuCqL8PwnJ44FmikMYLuFgHw9W09hKHYYzFBd0
A6RLFNUGtPNbkR/Lp+mVLVokkNKcW9ItiD0qwLBSWSaFwTuWoBi/Q7w9C7mjPHdm
X1Kp8yyKAgF7gx+F17dRlNx8jcjq9/365j7K+8PBN3d+T/15585h3513A68ZYkCa
JMxlpJyExWW6KcuYq7RPyvK/AF3ikZnB/jkHfWwRWp3DdfQtgPJmU9gBavpluV53
CTKKHJiJ1Bl1+Tpq0Ktpbi5f6Q6WEi9TxqFVT1Ca0czhgqofgUX0cKI46BQfLmFP
5FnZswd7UXGV0fWnRfEm2IdnWEi0dc4MzETLDFUubq08ntCuSMfLBEPk3ve58iFh
SrlBDgxCn1AEmlzfMAuaIsp5TSlSJMWIc09Pa+bjP+SMJzhMoxSdftaOn5vM/4lR
NuWdp9qB3mvE0ETx0sP8qfVK5FRuTmRwNw8om7HMRTUYXd/ThrOZM8ukhiZNHbnO
joukQLixaVs4Uq3qooyLtlwqYylStpljAZolcLLMxRK3dS7G0g2Cq0vknGNbDLy0
4zIydRuc0AK8dh77FAirWVFipeTm12sFVWmG43jnAGbI5HnWOmRMOX97mZ7fkHak
UHi3VpkwCOht9VD0YpkFfq/9VgfExbCwkThdWGG5bl6U5kEqPn1XwgIXlvwxi8ra
FepsUYeMGWwMCQflX6y1tO0=
Toplanan veriler
- Belirtilen sayfadaki metin bloklarını kazır
- Toplanan tüm sayfaları içeren dizi (Use Pages seçeneği kullanıldığında kullanılır)
Özellikler
- Çok sayfalı metin veri çekme (sayfalar arası geçiş)
- Metni HTML etiketlerinden otomatik temizleme
- Metin bloğu için minimum uzunluk belirleme imkanı
- Metinden bağlantı metinlerini (anchor) isteğe bağlı kaldırma
- gzip/deflate/brotli sıkıştırma desteği
- Web sitelerinin kodlamalarını algılama ve UTF-8'e dönüştürme
- CloudFlare korumasını atlatma
- Motor seçimi (HTTP veya Chrome)
Kullanım senaryoları
- Herhangi bir web sitesinden metin içeriği çekme
Sorgular
Sorgu olarak, metin bloklarının çekilmesi gereken sayfaların bağlantıları belirtilmelidir, örneğin:
https://a-parser.com/
Sonuç çıktı seçenekleri
A-Parser, yerleşik Template Toolkit şablon motoru sayesinde sonuçları esnek bir şekilde biçimlendirmeyi destekler; bu da sonuçları hem serbest formda hem de CSV veya JSON gibi yapılandırılmış formatlarda almanıza olanak tanır.
Varsayılan çıktı
Sonuç formatı:
$texts.format('$text\n')
Sonuç örneği:
Merhaba, İşinin Ehli En Üst Düzey Profesyonellerden Oluşan Süper Ekip! İspanyolca, Türkçe ve Portekizce dillerini öğrenme fırsatı sunduğunuz için teşekkürler! İmkanlarınızın daha da genişlemesini dilerim! İlham ve Yaratıcılıkla kalın! Ayrıca Almanca ve Fransızca öğrenme imkanı da eklemenizi rica ediyorum!”
Lingualeo'yu uzun yıllardır kullanıyorum, ilk kez henüz uygulama hiç yokken, sadece web sitesi varken çalışmaya başlamıştım) Geliştiricilere teşekkürler, aynı ruhla, yaratıcılıkla ve işinize olan büyük sevginizle devam edin)
BT için teknik İngilizce: sözlükler, ders kitapları, dergiler
Çevrimiçi dil öğren Çevrimiçi İngilizce öğren Çevrimiçi Vietnamca öğren Çevrimiçi Yunanca öğren Çevrimiçi Endonezyaca öğren Çevrimiçi İspanyolca öğren Çevrimiçi İtalyanca öğren Çevrimiçi Çince öğren Çevrimiçi Korece öğren Çevrimiçi Almanca öğren Çevrimiçi Felemenkçe öğren Çevrimiçi Lehçe öğren Çevrimiçi Portekizce öğren Çevrimiçi Sırpça öğren Çevrimiçi Türkçe öğren Çevrimiçi Ukraynaca öğren Çevrimiçi Fransızca öğren Çevrimiçi Hintçe öğren Çevrimiçi Çekçe öğren Çevrimiçi Japonca öğren
Olası ayarlar
| Parametre adı | Varsayılan değer | Açıklama |
|---|---|---|
| Min block length | 50 | Karakter cinsinden minimum metin bloğu uzunluğu. |
| Skip anchor text | ☐ | Metindeki bağlantı metinlerinin (anchor) atlanıp atlanmayacağı. |
| Ignore tags list | Yoksayılması gereken etiketleri belirtme seçeneği. Örnek: div,span,p | |
| Good status | All | Sunucudan gelen hangi yanıtın başarılı sayılacağı. Veri çekme sırasında sunucudan farklı bir yanıt gelirse, sorgu başka bir proxy ile tekrarlanır. |
| Good code RegEx | Yanıt kodunu kontrol etmek için düzenli ifade (regex) belirtme imkanı. | |
| Method | GET | Sorgu yöntemi. |
| POST body | POST yöntemi kullanıldığında sunucuya iletilecek içerik. $query – sorgu URL'si, $query.orig – orijinal sorgu ve Use Pages seçeneği kullanıldığında $pagenum - sayfa numarası değişkenlerini destekler. | |
| Cookies | Sorgu için çerezleri (cookies) belirtme imkanı. | |
| User agent | `_Otomatik olarak güncel Chrome sürümünün user-agent bilgisi eklenir_ | Sayfa sorgulanırken kullanılacak User-Agent başlığı. |
| Additional headers | Şablon motoru özelliklerini ve sorgu oluşturucudaki değişkenleri kullanarak özel sorgu başlıkları belirtme imkanı. | |
| Read only headers | ☐ | Sadece başlıkları oku. İçeriği işlemeye gerek yoksa bazı durumlarda trafik tasarrufu sağlar. |
| Detect charset on content | ☐ | Sayfa içeriğine göre kodlamayı algıla. |
| Emulate browser headers | ☐ | Tarayıcı başlıklarını emüle et. |
| Max redirects count | 7 | Veri kazıyıcının takip edeceği maksimum yönlendirme (redirect) sayısı. |
| Max cookies count | 16 | Kaydedilecek maksimum çerez (cookies) sayısı. |
| Bypass CloudFlare | ☑ | Otomatik CloudFlare kontrolü atlatma. |
| Follow common redirects | ☑ | Max redirects count sınırını aşarak aynı alan adı içinde http <-> https ve www.domain <-> domain yönlendirmelerine izin verir. |
| Engine | HTTP (Fast, JavaScript Disabled) | HTTP (daha hızlı, JavaScript kapalı) veya Chrome (daha yavaş, JavaScript açık) motorunu seçmeye olanak tanır. |
| Chrome Headless | ☐ | Seçenek etkinse tarayıcı görüntülenmez. |
| Chrome DevTools | ☑ | Chromium hata ayıklama araçlarını kullanmaya olanak tanır. |
| Chrome Log Proxy connections | ☑ | Seçenek etkinse, chrome bağlantılarıyla ilgili bilgiler günlüğe (log) yazılır. |
| Chrome Wait Until | networkidle2 | Sayfanın ne zaman yüklendi sayılacağını belirler. Değerler hakkında daha fazla bilgi. |
| Use HTTP/2 transport | ☐ | HTTP/1.1 yerine HTTP/2 kullanılıp kullanılmayacağını belirler. Örneğin, Google ve Majestic HTTP/1.1 kullanıldığında hemen engeller. |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | Chrome üzerinden CF atlatma. |
| Bypass CloudFlare with Chrome Max Pages | Chrome üzerinden CF atlatırken maksimum sayfa sayısı. |