HTML::EmailExtractor - Datenerfassung von E-Mail-Adressen von Webseiten
Übersicht über den Parser
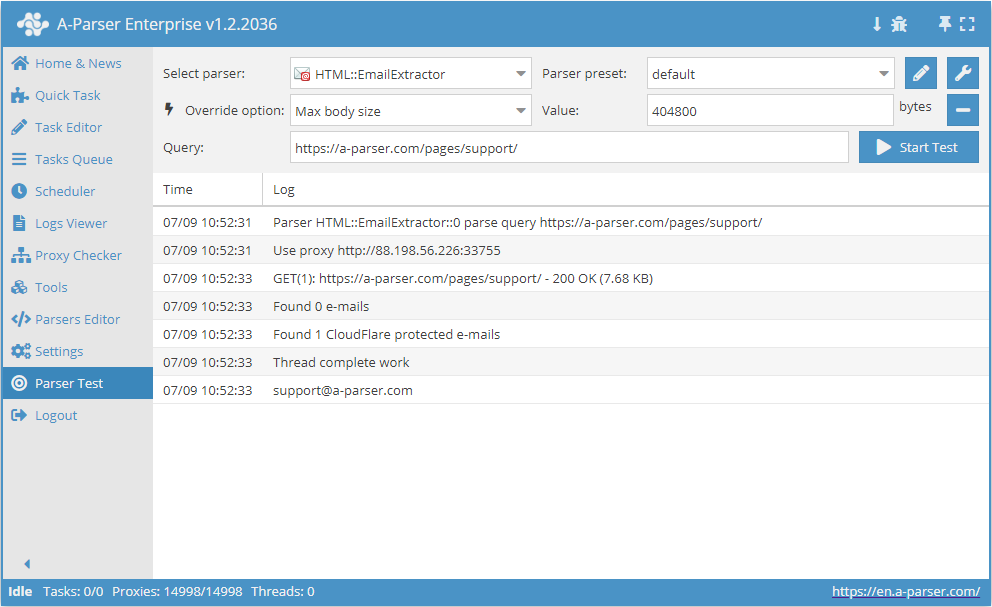
 HTML::EmailExtractor extrahiert E-Mail-Adressen von den angegebenen Seiten. Er unterstützt das Durchlaufen interner Seiten einer Website bis zu einer festgelegten Tiefe, was es ermöglicht, alle Seiten einer Website zu scannen und dabei interne sowie externe Links zu erfassen. Der E-Mail-Parser verfügt über integrierte Funktionen zur Umgehung des Schutzes von CloudFlare und bietet zudem die Möglichkeit, Chrome als Engine für die Extraktion von E-Mails von Seiten zu wählen, deren Daten durch Skripte geladen werden. Er kann Geschwindigkeiten von bis zu 250 Anfragen pro Minute erreichen – das sind 15 000 Links pro Stunde.
HTML::EmailExtractor extrahiert E-Mail-Adressen von den angegebenen Seiten. Er unterstützt das Durchlaufen interner Seiten einer Website bis zu einer festgelegten Tiefe, was es ermöglicht, alle Seiten einer Website zu scannen und dabei interne sowie externe Links zu erfassen. Der E-Mail-Parser verfügt über integrierte Funktionen zur Umgehung des Schutzes von CloudFlare und bietet zudem die Möglichkeit, Chrome als Engine für die Extraktion von E-Mails von Seiten zu wählen, deren Daten durch Skripte geladen werden. Er kann Geschwindigkeiten von bis zu 250 Anfragen pro Minute erreichen – das sind 15 000 Links pro Stunde.Anwendungsfälle für den Parser
E-Mails von einer Website extrahieren mit Durchlaufen der Seiten bis zum angegebenen Limit
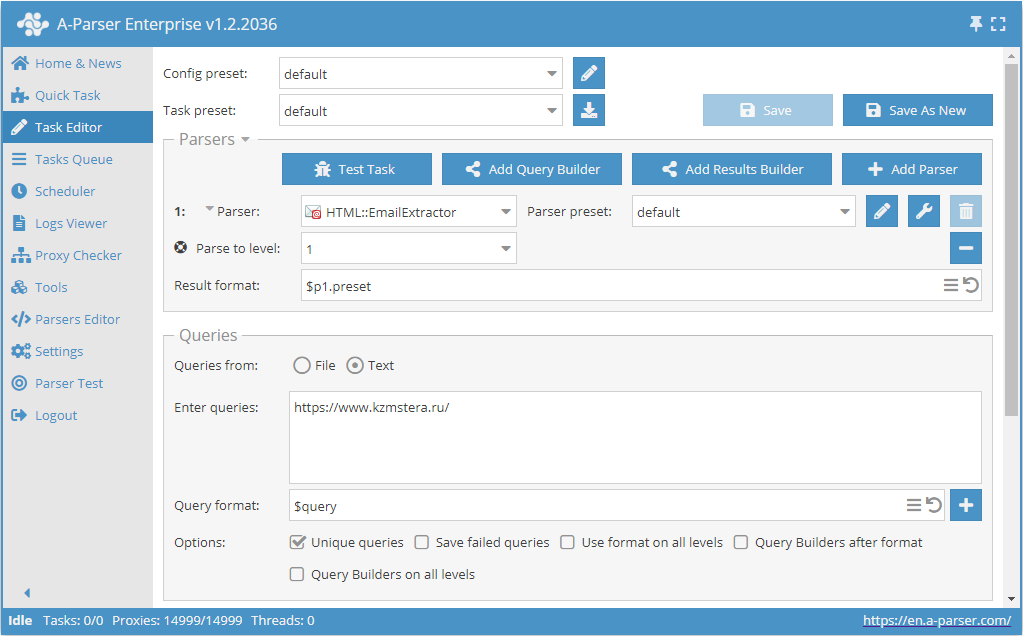
- Die Option Parse to level (Bis zur Ebene extrahieren / Parse to level) hinzufügen und in der Liste den gewünschten Wert (Limit) auswählen.
- Im Abschnitt Queries (Abfragen) die Option
Unique queriesaktivieren. - Im Abschnitt Results (Ergebnisse) die Option
Unique stringaktivieren. - Als Abfrage den Link zur Website angeben, von der E-Mails extrahiert werden sollen.
Beispiel herunterladen
Wie man ein Beispiel in A-Parser importiert
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
Tipp
E-Mails nach einer Website-Datenbank extrahieren mit Durchlaufen jeder Website bis zum angegebenen Limit
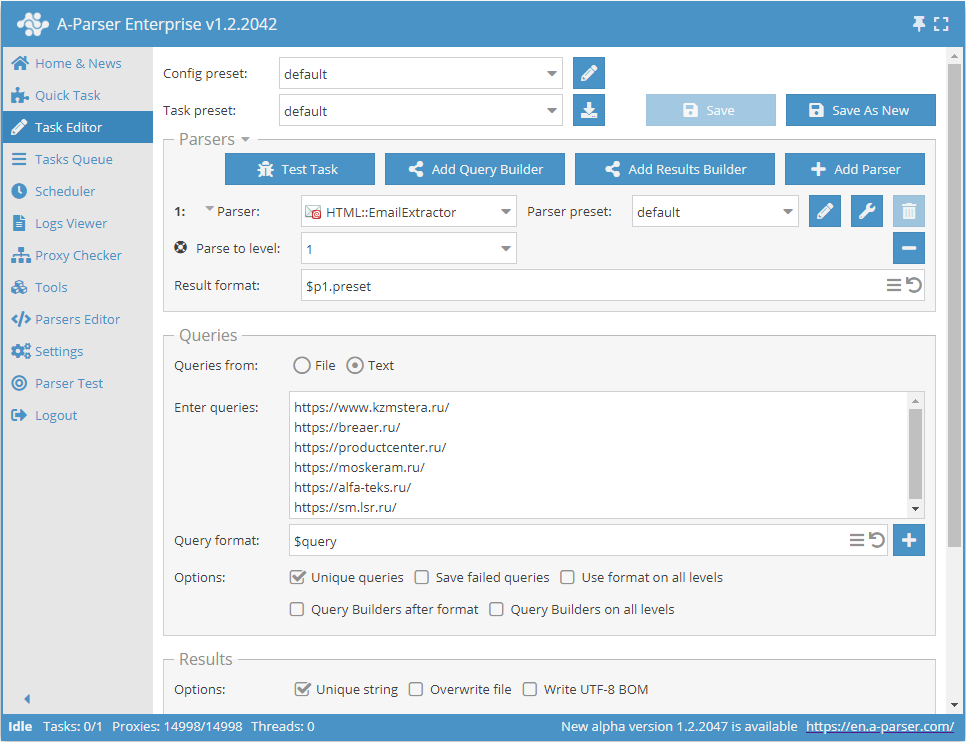
- Die Option Parse to level (Bis zur Ebene extrahieren / Parse to level) hinzufügen und in der Liste den gewünschten Wert (Limit) auswählen.
- Im Abschnitt Queries (Abfragen) die Option
Unique queriesaktivieren. - Im Abschnitt Results (Ergebnisse) die Option
Unique stringaktivieren. - Als Abfrage die Links zu den Websites angeben, von denen E-Mails extrahiert werden sollen, oder in Queries from (Abfragen aus)
Filewählen und die Abfragedatei mit der Website-Datenbank hochladen.
Beispiel herunterladen
Wie man ein Beispiel in A-Parser importiert
eJxtU01z2jAQ/S8aDu0MY5pDL74RJkzTIXGakBPDQYPXREWWVEmGpB7+e98Kx4Ym
N+3u2/f2S62IMuzCg6dAMYh81QqX3iIXJVWy0VGMhZM+kOfwSvxY3i3y/KaWSt+8
Ri830XpAenAr4psjpFsXlTUBMVXCTBwL2pOGZy91A8zVcb0eC+ghM8ytryXrjtxV
1hXRB5/knpYWwUppGtxzWPeyZrlRKSNxNKsS0ZevWXxlBlmWiiuR+qTAbQyqz0b9
4VJEiF6ZLfAwvaIw97aGO1IiYefbe4UrMUq2AE2T8n+dckQefUNjEVDtHAOisg9U
UgdEVCQvMbGiG07eCmumWqfBDLBEf90oXWLs0wpJt13i55DiA8ex7/Bcak/+4FFD
z5Ks6+JuyCrtwm7RuLFoW6taRdhhZhvDu/kG547I9WO7Z1htPfUyHXOnjstyZPgA
hq1N3eC6aONiM5fOjTWV2hZowKuS3pGNWeJ8CzOztdPEfZlGa2wl0ONwIdPQrYGN
ocD/k2dJ4uLwo7U6/Hw6leq8wgV+5wJrTPJctaPcSK2fHxfnETFcFIyXGF3IJ5PD
4ZDt/taBl5r5ZiI4N9LW4qjQ2XHd/7n+Z7af/7y8PWJpv8PDCc4dMhg+jCpgI/zL
/gFm02Dr
Tipp
E-Mails nach einer Link-Datenbank extrahieren
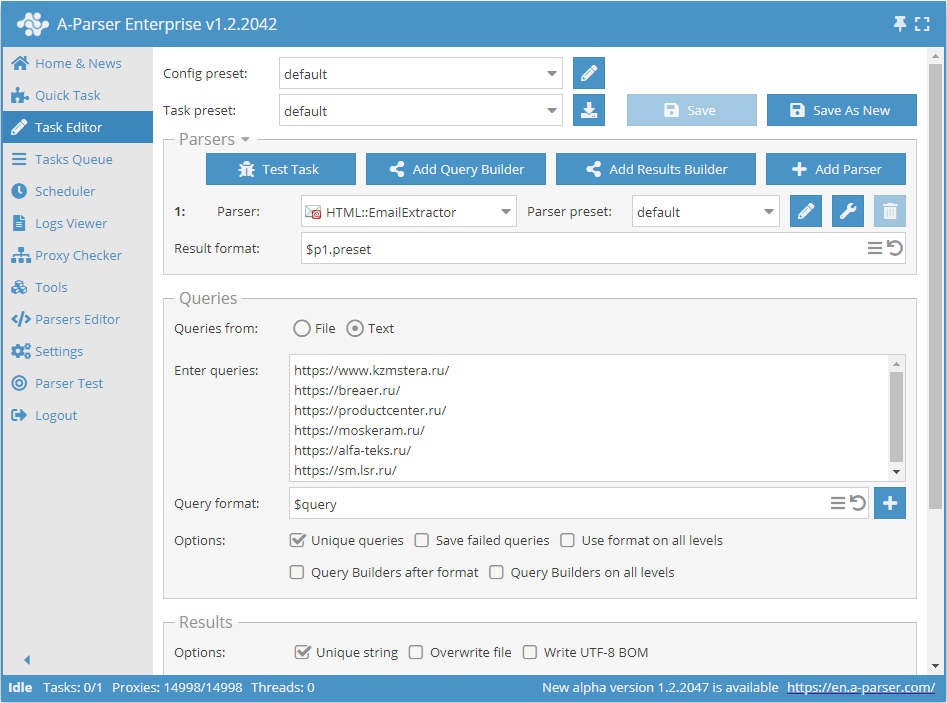
- Im Abschnitt Queries (Abfragen) die Option
Unique queriesaktivieren. - Im Abschnitt Results (Ergebnisse) die Option
Unique stringaktivieren. - Als Abfrage die Links angeben, von denen E-Mails extrahiert werden sollen, oder in Queries from (Abfragen aus)
Filewählen und die Abfragedatei mit der Link-Datenbank hochladen.
Beispiel herunterladen
Wie man ein Beispiel in A-Parser importiert
eJxtU01z0zAQ/S+aHmAmOPTAxbc00wwwaV3a9BRyEPE6COuLXSkpePLfWTmOHZfe
tG/fvv1UI4Kkmh4QCAKJfN0I375FLkqoZNRBTISXSIDJvRafV3fLPL81Uunbl4By
Gxwy5UzebCaCBfhJC4dGJqErf511qr3zSe5h5dhZKQ0DvGDrXhpIUaUMkLxZ1Qq9
e5+Fl6Qgy1IF5azUpwypriHrs1W/Y4qngMrumM8mKqAFOsNwgFYkgX/OFa7FVWsL
lolt/LdTjMgDRpgI4moX3DGUvaOSmtijAqDkERQ+lcR4I5ydab2EPeiB1srfRKVL
nuOs4qAvXeDblOI/jWPf4WWqPeABuYZepbVuirshqnRLt+PGreO2tTIqsE1zF23a
zUcGawDfj+0+0YxD6NN0yl12PhUPtmTmsLWZH6BRG6PNjMGts5XaFdwAqhLOzGhX
fI+FnTvjNaS+bNSat0LwOFzIjLo1JGMo8HXwvE0xuuTgnKavT6dSPSq+wE+pQMOT
vMzaSW6l1s+Py0uPGC6KjZ8heMqn08PhkNV/DaWlZhin3+3Z8wMl4Bjy6Mq4DVuw
4bXLOKpZwoxRqSv5IUBNY5hMpqkVEKnUADvHN8yDPG76P9v/7Obtn5s3R76RX/Rw
oqeBJjJjvBniAxD59fEfH7B6cg==
Tipp
Gesammelte Daten
- E-Mail-Adressen
- Gesamtzahl der Adressen auf der Seite
- Array mit allen gesammelten Seiten (wird bei Verwendung der Option Use Pages genutzt)
Funktionen
- Mehrseitige Datenerfassung (Navigation durch Seiten)
- Navigation durch interne Seiten der Website bis zur angegebenen Tiefe (Option Parse to level) – ermöglicht das Durchlaufen aller Seiten der Website unter Erfassung interner und externer Links
- Bestimmung von Follow-Links für Verweise
- Limit für Seitennavigation (Option Follow links limit)
- Möglichkeit anzugeben, ob Subdomains als interne Seiten der Website betrachtet werden sollen
- Unterstützt Komprimierung gzip/deflate/brotli
- Erkennung und Konvertierung von Website-Kodierungen in UTF-8
- Umgehung des CloudFlare-Schutzes
- Wahl der Engine (HTTP oder Chrome)
- Unterstützung des gesamten Funktionsumfangs von
 HTML::LinkExtractor
HTML::LinkExtractor
Anwendungsbeispiele
- Extraktion von E-Mail-Adressen
- Ausgabe der Anzahl der E-Mail-Adressen
Abfragen
Als Abfragen müssen Links zu Seiten angegeben werden, zum Beispiel:
https://a-parser.com/pages/support/
Beispiele für die Ergebnisausgabe
A-Parser unterstützt eine flexible Formatierung der Ergebnisse dank der integrierten Template-Engine Template Toolkit, was die Ausgabe in beliebiger Form sowie in strukturierter Form wie CSV oder JSON ermöglicht.
Ausgabe der Anzahl der E-Mail-Adressen
Ergebnisformat:
$mailcount
Beispielergebnis:
4
Mögliche Einstellungen
Hinweis
| Parametername | Standardwert | Beschreibung |
|---|---|---|
| Good status | All | Auswahl, welche Antwort vom Server als erfolgreich gilt. Wenn bei der Datenerfassung eine andere Antwort vom Server kommt, wird die Abfrage mit einem anderen Proxy wiederholt |
| Good code RegEx | Möglichkeit, einen regulären Ausdruck zur Überprüfung des Antwortcodes anzugeben | |
| Ban Proxy Code RegEx | Möglichkeit, Proxys zeitweise zu sperren (Proxy ban time) basierend auf dem Antwortcode des Servers | |
| Method | GET | Abfragemethode |
| POST body | Inhalt, der bei Verwendung der POST-Methode an den Server gesendet wird. Unterstützt Variablen $query – Abfrage-URL, $query.orig – ursprüngliche Abfrage und $pagenum - Seitennummer bei Verwendung der Option Use Pages. | |
| Cookies | Möglichkeit, Cookies für die Abfrage anzugeben. | |
| User agent | _Automatisch wird der User-Agent der aktuellen Chrome-Version eingesetzt_ | Der User-Agent Header beim Abrufen von Seiten |
| Additional headers | Möglichkeit, benutzerdefinierte Abfrage-Header mit Unterstützung der Template-Engine-Funktionen und Verwendung von Variablen aus dem Abfrage-Builder anzugeben | |
| Read only headers | ☐ | Nur Header lesen. In einigen Fällen spart dies Traffic, wenn der Inhalt nicht verarbeitet werden muss |
| Detect charset on content | ☐ | Kodierung basierend auf dem Seiteninhalt erkennen |
| Emulate browser headers | ☐ | Browser-Header emulieren |
| Max redirects count | 0 | Maximale Anzahl an Weiterleitungen, denen der Parser folgt |
| Follow common redirects | ☑ | Ermöglicht Weiterleitungen http <-> https und www.domain <-> domain innerhalb derselben Domain unter Umgehung des Limits Max redirects count |
| Max cookies count | 16 | Maximale Anzahl der zu speichernden Cookies |
| Engine | HTTP (Fast, JavaScript Disabled) | Ermöglicht die Wahl der Engine: HTTP (schneller, ohne JavaScript) oder Chrome (langsamer, JavaScript aktiviert) |
| Chrome Headless | ☐ | Wenn diese Option aktiviert ist, wird der Browser nicht angezeigt |
| Chrome DevTools | ☑ | Ermöglicht die Verwendung von Chromium-Debugging-Tools |
| Chrome Log Proxy connections | ☑ | Wenn diese Option aktiviert ist, werden Informationen zu Chrome-Verbindungen im Log ausgegeben |
| Chrome Wait Until | networkidle2 | Bestimmt, wann eine Seite als geladen gilt. Weitere Informationen zu den Werten. |
| Use HTTP/2 transport | ☐ | Bestimmt, ob HTTP/2 anstelle von HTTP/1.1 verwendet werden soll. Zum Beispiel sperren Google und Majestic sofort, wenn HTTP/1.1 verwendet wird. |
| Don't verify TLS certs | ☐ | Deaktivierung der TLS-Zertifikatsvalidierung |
| Randomize TLS Fingerprint | ☐ | Diese Option ermöglicht die Umgehung von Website-Sperren basierend auf dem TLS-Fingerabdruck |
| Bypass CloudFlare | ☑ | Automatische Umgehung der CloudFlare-Prüfung |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | CloudFlare-Umgehung via Chrome |
| Bypass CloudFlare with Chrome Max Pages | 20 | Max. Anzahl der Seiten bei CloudFlare-Umgehung via Chrome |
| Subdomains are internal | ☐ | Ob Subdomains als interne Links betrachtet werden sollen |
| Follow links | Internal only | Welchen Links gefolgt werden soll |
| Follow links limit | 0 | Limit für Follow links, wird auf jede einzigartige Domain angewendet |
| Skip comment blocks | ☐ | Ob Kommentarblöcke übersprungen werden sollen |
| Search Cloudflare protected e-mails | ☑ | Ob durch Cloudflare geschützte E-Mails extrahiert werden sollen. |
| Skip non-HTML blocks | ☑ | Keine E-Mail-Adressen in Tags (script, style, comment usw.) sammeln. |
| Skip meta tags | ☐ | Keine E-Mail-Adressen in Meta-Tags sammeln |
| Search URL encoded e-mails | ☐ | Erfassung von URL-kodierten E-Mails |