HTML::LinkExtractor - Parser für externe und interne Links von einer bestimmten Website
Übersicht über den Parser
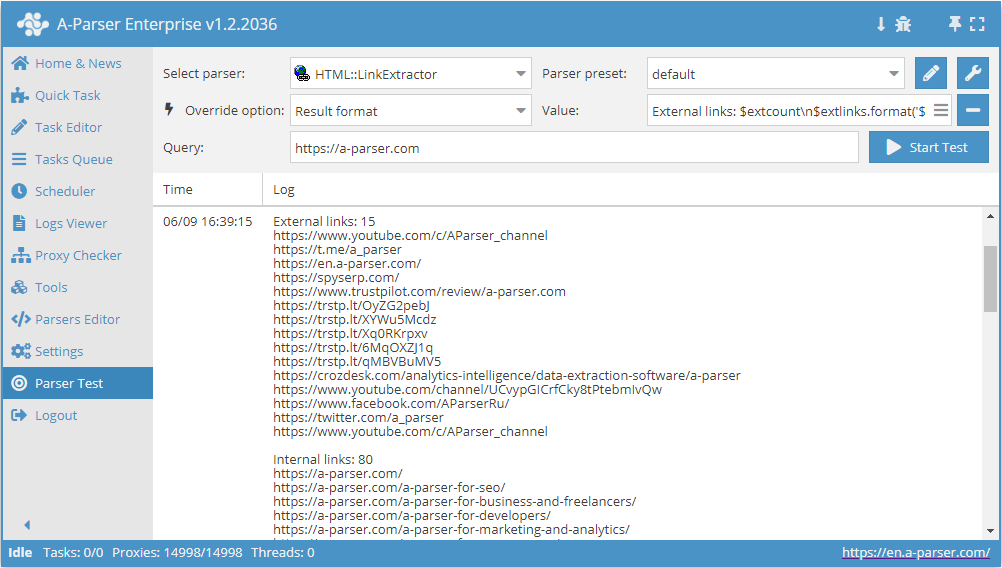
 HTML::LinkExtractor – Parser für externe und interne Links von einer angegebenen Website. Unterstützt mehrseitige Datenerfassung und Navigation durch interne Seiten der Website bis zur angegebenen Tiefe, was das Durchlaufen aller Seiten der Website ermöglicht, um interne und externe Links zu sammeln. Verfügt über integrierte Mittel zur Umgehung des Schutzes von CloudFlare und bietet zudem die Wahl von Chrome als Engine für das Scraping von E-Mails von Seiten, deren Daten durch Skripte geladen werden. Kann Geschwindigkeiten von bis zu 2000 Anfragen pro Minute erreichen – das sind 120 000 Links pro Stunde.
HTML::LinkExtractor – Parser für externe und interne Links von einer angegebenen Website. Unterstützt mehrseitige Datenerfassung und Navigation durch interne Seiten der Website bis zur angegebenen Tiefe, was das Durchlaufen aller Seiten der Website ermöglicht, um interne und externe Links zu sammeln. Verfügt über integrierte Mittel zur Umgehung des Schutzes von CloudFlare und bietet zudem die Wahl von Chrome als Engine für das Scraping von E-Mails von Seiten, deren Daten durch Skripte geladen werden. Kann Geschwindigkeiten von bis zu 2000 Anfragen pro Minute erreichen – das sind 120 000 Links pro Stunde.Anwendungsbeispiele für den Parser
Sammeln aller externen Links von einer Website
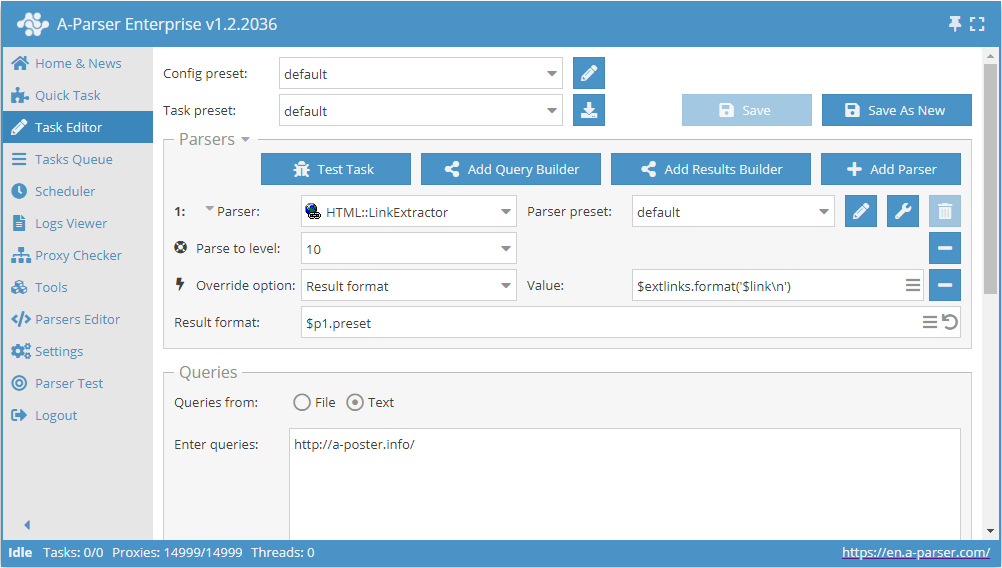
- Die Option Parse to level (Bis zur Ebene extrahieren / Parse to level) hinzufügen, in der Liste den Wert
10wählen (Übergang zu benachbarten Seiten bis zur 10. Ebene). - Die Option Result format hinzufügen, als Wert
$extlinks.format('$link\n')angeben (Ausgabe externer Links). - Im Bereich Queries (Abfragen) das Häkchen bei der Option
Unique queriessetzen. - Im Bereich Results (Ergebnisse) das Häkchen bei der Option
Unique stringsetzen. - Als Abfrage den Link zur Website angeben, von der die externen Links extrahiert werden sollen.
Beispiel herunterladen
Wie man ein Beispiel in A-Parser importiert
eJxtU01v2zAM/S9CgK5AlrSHXnxLgwZb4dZdm57SHISYztTIoirRWQrD/32U7NjJ
1ptIvsfHL9WCpN/5JwceyItkVQsb3yIRORSy0iTGwkrnwYXwSvxYPqRJkiqzuzuQ
kxtCx4geWwv6tMBstKTQeI6pnM2YIoU9aPbspa4Yc33VnOD34JzK4Ugo0JWSuJa2
hI4iRnAgzeJ+0gK+XYyC+fZmLi5Fs16PRUvxixgODHs96Xrqgy9yD0sMKkrD4F6w
9SjLqJNLghA96lxO6BAyyDxXoTOpW4UwlUH11aiPWKcnp8yW8Ww6BX7hsGQ3QUwS
nJ/HCldiFG3BaarI/9VyREKugrHwXO1Cci15Hyik9hxRBE7yBrJu2Ekt0My0joMe
YDH9baV0zlucFUz62RG/hmT/5Wj6Dk+leGV/HNfQZ4nWbfYwsHJMccuNG+S2tSoV
se3nWJmwmyt27gBsP7bHACvRQS/TZe7U+VAtmHAfw9ZmdnCdtXG2mXPnBk2htll3
c0dkZZb8GzIzx9JqCH2ZSmveiofn4UJmvltDMIYC/yXPo8TZPyJE7e9f2lKtU3yB
N6HAkid5qtql3EitX5/T04gYLoqN30Q2mU7ld4ueFzpRpsCpCESCLfJFcVvNuv+/
/S+vv/zFSd3wwt79U4sO3QUs+3hMnrfBP7b5C6wbebo=
Tipp
Sammeln aller internen Links von einer Website
Analog zum ersten Fall, aber in Schritt 2 muss als Wert $intlinks.format('$link\n') angegeben werden (Ausgabe interner Links).
Beispiel herunterladen
Wie man ein Beispiel in A-Parser importiert
eJxtU8tu2zAQ/BfCQBrAtZNDL7o5Roy2cOI0j5PjA2GtXNYUyZIrN4Ggf++QkiW7
zY27O7OzL9aCZdiHB0+BOIhsXQuX3iITORWy0izGwkkfyMfwWnx9vltm2VKZ/e0b
e7ll64HosbXgd0dgW8fKmoCYymGmFEs6kIbnIHUFzPVVc4I/kPcqpyOhsL6UjFra
EjqKGCnDGuJh0gI+XYyi+fpqLi5Fs9mMRUsJixSODHc96Xrqg0/yQM82qihNg3sB
616WSSeXTDF61Lmc8FvMIPNcxc6kbhXiVAbVF6N+pzoDe2V2wMP0isLC2xJuppQk
Ot+PFa7FKNkCaarE/9FyRMa+orEIqHYhUUveBwqpAyKKyUtsYNUNO6uFNTOt06AH
WEp/UymdY4uzAqRvHfFjyOq/HE3f4akUVvbHo4Y+S7JuVncDK7dLu0PjxqJtrUrF
sMPcVibu5grOPZHrx3YfYaX11Mt0mTt1HKojE+9j2NrMDa6zNs42c+7cWlOo3aq7
uSOyMs/4DSszt6XTFPsyldbYSqDH4UJmoVtDNIYC/yXPk8TZP2Jrdfj+1JbqvMIF
fokFlpjkqWqXciu1fnlcnkbEcFEwfjK7bDqVn50NWOhEmcJORSQy7SwuCm01m/7/
9r+8/vAXZ3WDhf0KDy06dhex8GFMAdvAj23+ApcrebQ=
Nur Links folgen, die das Wort forum nicht enthalten
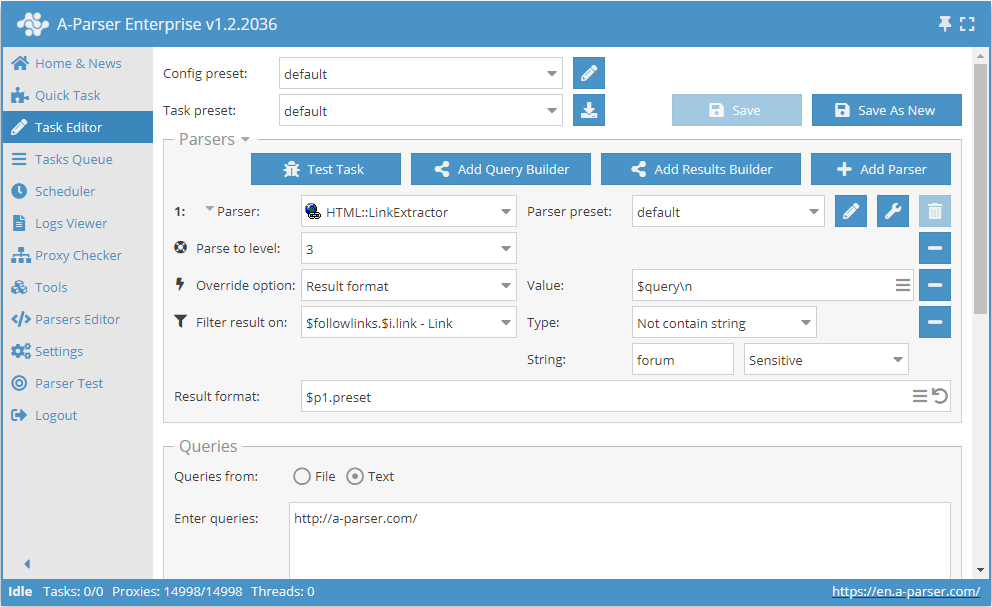
- Die Option Parse to level (Bis zur Ebene extrahieren / Parse to level) hinzufügen, in der Liste den Wert
3wählen (Übergang zu benachbarten Seiten bis zur 3. Ebene). - Die Option Result format hinzufügen, als Wert
$queryangeben. - Einen Filter hinzufügen. Filtern nach
$followlinks.$i.link - Link, TypEnthält keine Zeichenfolgewählen, als Zeichenfolge selbstforumangeben. - Im Bereich Queries (Abfragen) das Häkchen bei der Option
Unique queriessetzen. - Im Bereich Results (Ergebnisse) das Häkchen bei der Option
Unique stringsetzen. - Als Abfrage den Link zur Website angeben, von der die Links extrahiert werden sollen.
Beispiel herunterladen
Wie man ein Beispiel in A-Parser importiert
eJxtVE1v2zAM/S/CDhuQJS2GXXxLgwbd4DZdm57SHISYzrTIkipRaQvD/33UR2xn
6ykh+R75+CG3DLk7uHsLDtCxYtMyE/+zglVQcy+RTZjh1oEN4Q27Wd+WRVEKdbh+
Q8t3qC0hemzL8N0AsbVBoZWjmKjIjClKOIIkz5FLT5hv3Qh+BGtFBSd8rW3DkaQk
BZnBPr14sO/Pz4qNuLWQCEFFhhcbokupXyWpDArCL9tOMnCdWErjTivkQo3yU1nf
kJ3Uk8MB9dBtt6fkbhmFBSnmcppn1Qcf+RHWOkmCwb0k6443sYGKI4ToNHX4+csU
30IGXlUi1OQyVQjTHqo+KfESBTq0Qu0JHwYhwC2tbsiNEJPE6ZwUbvK0Quc+8n8l
DivQepgwR2qXnLRUfaDm0lFE0Jg4bXaVl1i0TKu5lHGBAyymv/JCVnQd85pIPzLx
Y8jqvxxd3+G4FN3CqyUNfZZoXa1uB1alS72PW4z7bQSS7Rbaq7CbC3IeAEw/trsA
a7SFvkzOnKvTAzCgwuENW5ubwXXWxtlmzp10UbXYr/Ixn5BeremVrdRCN0ZC6Et5
KWkrDh6GC5m7vIZgDAL/JS9iibP3iVpL9/MxSTVW0AV+DwIbmuS4ak6541I+PZTj
CBsuiozfiKaYzfjX9PCnO93MWOAh7DUdFHXVbfvPQv/xaD/8OBRtR/v64+4TOjQX
sOSjKbn4yi67v8azl7c=
Tipp
Erhobene Daten
- Anzahl der externen Links
- Anzahl der internen Links
- Externe Links:
- die Links selbst
- Ankertexte
- von HTML-Tags bereinigte Ankertexte
- nofollow-Parameter
- komplettes
<a>-Tag
- Interne Links:
- die Links selbst
- Ankertexte
- von HTML-Tags bereinigte Ankertexte
- nofollow-Parameter
- komplettes
<a>-Tag
- Array mit allen gesammelten Seiten (wird bei Verwendung der Option Use Pages genutzt)
Funktionen
- Mehrseitige Datenerfassung (Navigation durch Seiten)
- Navigation durch interne Seiten der Website bis zur angegebenen Tiefe (Option Parse to level) – ermöglicht das Durchlaufen aller Seiten der Website, um interne und externe Links zu sammeln
- Limit für das Folgen von Links (Option Follow links limit)
- Bereinigt Ankertexte automatisch von HTML-Tags
- Bestimmung von nofollow für jeden Link
- Möglichkeit anzugeben, ob Subdomains als interne Seiten der Website gezählt werden sollen
- Unterstützt Kompressionen gzip/deflate/brotli
- Erkennung und Umwandlung von Website-Kodierungen in UTF-8
- Umgehung des CloudFlare-Schutzes
- Wahl der Engine (HTTP oder Chrome)
Anwendungsfälle
- Erstellung einer vollständigen Sitemap (Speichern aller internen Links)
- Abrufen aller externen Links von einer Website
- Überprüfung von Backlinks auf die eigene Website
Abfragen
Als Abfragen müssen Links zu den Seiten angegeben werden, von denen Links gesammelt werden sollen, oder ein Einstiegspunkt (z. B. die Startseite der Website), wenn die Option Parse to level verwendet wird:
https://lenta.ru/
https://a-parser.com/wiki/index/
Beispiele für die Ergebnisausgabe
A-Parser unterstützt eine flexible Formatierung der Ergebnisse dank der integrierten Template-Engine Template Toolkit, was die Ausgabe in beliebiger Form sowie in strukturierter Form wie CSV oder JSON ermöglicht.
Ausgabe von externen und internen Links mit deren Anzahl
Ergebnisformat:
External links: $extcount\n$extlinks.format('$link\n')
Internal links: $intcount\n$intlinks.format('$link\n')
Beispielergebnis:
External links: 12
https://www.youtube.com/c/AParser_channel
https://t.me/a_parser
https://en.a-parser.com/
https://spyserp.com/ru/
https://sitechecker.pro/
https://arsenkin.ru/tools/
https://spyserp.com/
http://www.promkaskad.ru/
https://www.youtube.com/channel/UCvypGICrfCky8tPtebmIvQw
https://www.facebook.com/AParserRu
https://twitter.com/a_parser
https://www.youtube.com/c/AParser_channel
Internal links: 129
https://a-parser.com/
https://a-parser.com/
https://a-parser.com/a-parser-for-seo/
https://a-parser.com/a-parser-for-business-and-freelancers/
https://a-parser.com/a-parser-for-developers/
https://a-parser.com/a-parser-for-marketing-and-analytics/
https://a-parser.com/a-parser-for-e-commerce/
https://a-parser.com/a-parser-for-cpa/
https://a-parser.com/wiki/features-and-benefits/
https://a-parser.com/wiki/parsers/
Mögliche Einstellungen
Hinweis
| Parametername | Standardwert | Beschreibung |
|---|---|---|
| Good status | All | Auswahl, welche Antwort vom Server als erfolgreich gilt. Wenn bei der Datenerfassung eine andere Antwort vom Server erfolgt, wird die Abfrage mit einem anderen Proxy wiederholt |
| Good code RegEx | Möglichkeit, einen regulären Ausdruck zur Überprüfung des Antwortcodes anzugeben | |
| Ban Proxy Code RegEx | Möglichkeit, Proxys zeitweise zu sperren (Proxy ban time) basierend auf dem Antwortcode des Servers | |
| Method | GET | Abfragemethode |
| POST body | Inhalt, der bei Verwendung der POST-Methode an den Server übertragen wird. Unterstützt Variablen $query – Abfrage-URL, $query.orig – ursprüngliche Abfrage und $pagenum - Seitennummer bei Verwendung der Option Use Pages. | |
| Cookies | Möglichkeit, Cookies für die Abfrage anzugeben. | |
| User agent | _Automatisch wird der User-Agent der aktuellen Chrome-Version eingesetzt_ | Der Header User-Agent beim Abrufen von Seiten |
| Additional headers | Möglichkeit, beliebige Abfrage-Header mit Unterstützung der Template-Engine-Funktionen und Verwendung von Variablen aus dem Abfrage-Builder anzugeben | |
| Read only headers | ☐ | Nur Header lesen. In einigen Fällen spart dies Traffic, wenn der Inhalt nicht verarbeitet werden muss |
| Detect charset on content | ☐ | Kodierung basierend auf dem Seiteninhalt erkennen |
| Emulate browser headers | ☐ | Browser-Header emulieren |
| Max redirects count | 0 | Maximale Anzahl an Weiterleitungen, denen der Parser folgt |
| Follow common redirects | ☑ | Ermöglicht Redirects http <-> https und www.domain <-> domain innerhalb einer Domain unter Umgehung des Limits Max redirects count |
| Max cookies count | 16 | Maximale Anzahl an zu speichernden Cookies |
| Engine | HTTP (Fast, JavaScript Disabled) | Ermöglicht die Wahl der Engine HTTP (schneller, ohne JavaScript) oder Chrome (langsamer, JavaScript aktiviert) |
| Chrome Headless | ☐ | Wenn die Option aktiviert ist, wird der Browser nicht angezeigt |
| Chrome DevTools | ☑ | Ermöglicht die Verwendung von Chromium-Debugging-Tools |
| Chrome Log Proxy connections | ☑ | Wenn die Option aktiviert ist, werden Informationen zu Chrome-Verbindungen im Log ausgegeben |
| Chrome Wait Until | networkidle2 | Bestimmt, wann eine Seite als geladen gilt. Details zu den Werten. |
| Use HTTP/2 transport | ☐ | Bestimmt, ob HTTP/2 anstelle von HTTP/1.1 verwendet werden soll. Zum Beispiel sperren Google und Majestic sofort, wenn HTTP/1.1 verwendet wird. |
| Don't verify TLS certs | ☐ | Deaktivierung der TLS-Zertifikatsvalidierung |
| Randomize TLS Fingerprint | ☐ | Diese Option ermöglicht die Umgehung von Website-Sperren durch TLS-Fingerprinting |
| Bypass CloudFlare | ☑ | Automatische Umgehung der CloudFlare-Prüfung |
| Bypass CloudFlare with Chrome(Experimental) | ☐ | CF-Umgehung via Chrome |
| Bypass CloudFlare with Chrome Max Pages | 20 | Max. Anzahl der Seiten bei CF-Umgehung via Chrome |
| Subdomains are internal | ☐ | Ob Subdomains als interne Links gezählt werden sollen |
| Follow links | Internal only | Welchen Links gefolgt werden soll |
| Follow links limit | 0 | Limit für Follow links, wird auf jede eindeutige Domain angewendet |
| Skip comment blocks | ☐ | Ob Kommentarblöcke übersprungen werden sollen |