SE::Yandex::WordStat::ByRegion -
Översikt av scrapern
Wordstat är en tjänst från Yandex som är utformad för att utvärdera användarintresse för olika ämnen och välja sökord för SEO-optimering och kontextuell reklam. Dessutom kan man med hjälp av Wordstat Yandex utvärdera säsongsvariationer och det geografiska beroendet för sökfrågor.
Scrapern Yandex WordStat by region stöder automatisk multiplikation av frågor, så du kan vara säker på att du får maximalt antal resultat från sökresultaten. A-Parser kan också automatiskt navigera genom relaterade frågor till ett angivet djup.
Funktionaliteten i A-Parser gör det möjligt att spara inställningar för dataskrapning för framtida bruk (förinställningar), schemalägga dataskrapning och mycket mer. Du kan använda automatisk multiplikation av frågor, ersättning av underfrågor från filer, generering av alfanumeriska kombinationer och listor för att få största möjliga mängd resultat.
Resultaten kan sparas i den form och struktur du behöver, tack vare den inbyggda kraftfulla mallmotorn Template Toolkit som gör det möjligt att tillämpa ytterligare logik på resultaten och exportera data i olika format, inklusive JSON, SQL och CSV.
Konton
För att använda scrapern  SE::Yandex::WordStat::ByRegion krävs Yandex-konton. Konton kan registreras med hjälp av scrapern
SE::Yandex::WordStat::ByRegion krävs Yandex-konton. Konton kan registreras med hjälp av scrapern  SE::Yandex::Register eller genom att helt enkelt lägga till befintliga konton i filen
SE::Yandex::Register eller genom att helt enkelt lägga till befintliga konton i filen files/SE-Yandex/accounts.txt i det format som stöds.
Alternativt kan du aktivera registrering av konton "i farten".
Insamlade data
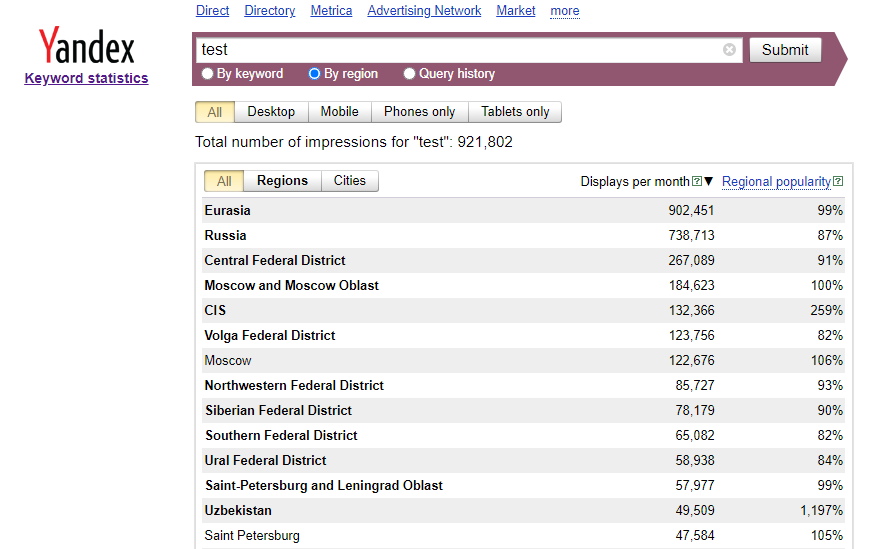
- Totalt antal visningar per sökfråga
- Sökordsstatistik per regioner och städer:
- Region/Stad
- Antal visningar per månad
- Regional popularitet i %
Funktioner
- Stöd för automatisk hantering av Smart captcha och möjlighet att hantera grafisk captcha med hjälp av tjänsten AntiCaptcha eller någon annan tjänst som stöder deras API
- Val av enhetstyp
- Möjlighet att välja auktoriseringsmetod
- Möjlighet att registrera konton "i farten"
- Stöder arbete med utökat kontoformat och kan svara på hemliga frågor (om svaret finns i
info). Den använder också en sparad proxy för auktorisering (om den finns iinfo).
Användningsfall
- Uppskattning av trafikmängd per sökord uppdelat på regioner
Frågor
Som frågor måste du ange sökord, precis som om du skulle skriva in dem direkt i Wordstats sökformulär, till exempel:
test
Alternativ för resultatvisning
A-Parser stöder flexibel formatering av resultat tack vare den inbyggda mallmotorn Template Toolkit, vilket gör det möjligt att visa resultat i valfri form, såväl som i strukturerad form, till exempel CSV eller JSON
Standardutdata
Resultatformat:
$query - Total views: $totalcount\nViews by regions:\n$regions.format('$region $count, $popularity%\n')\nViews by cities:\n$cities.format('$city $count, $popularity%\n')
Resultatet visar antal visningar per fråga, sökordsstatistik per regioner och städer, antal visningar per månad och regional popularitet:
test - Total views: 872855
Views by regions:
Moskva och Moskva oblast 147107, 85%
Centrum 194716, 77%
Nordväst 55815, 70%
Söder 31759, 67%
Volga-regionen 86006, 66%
...
Views by cities:
Tjita 2937, 113%
Sankt Petersburg 35713, 73%
Belgorod 2737, 58%
Ivanovo 1773, 55%
Kaluga 2196, 64%
Kostroma 1166, 49%
Utdata till CSV-tabell
Resultatformat:
[% FOREACH i IN regions;
tools.CSVline(query, i.popularity, i.region, i.count);
END %]
Exempel på resultat:
"test",88,"Moskva och Moskva oblast",1902795
"test",96,"Centrum",2992864
"test",95,"Nordväst",926138
"test",112,Söder,647140
"test",124,"Volga-regionen",1927873
"test",64,"Väst",60975
"test",86,"Öst",427304
Spara i SQL-format
Resultatformat:
[% FOREACH i IN regions;
"INSERT INTO regions VALUES('" _ query _ "', '"; i.popularity _ "', '"; i.count _ "', '"; i.region _ "')\n";
END %]
Exempel på resultat:
INSERT INTO regions VALUES('test', '88', '1902795', 'Moskva och Moskva oblast')
INSERT INTO regions VALUES('test', '96', '2992864', 'Centrum')
INSERT INTO regions VALUES('test', '95', '926138', 'Nordväst')
INSERT INTO regions VALUES('test', '112', '647140', 'Syd')
INSERT INTO regions VALUES('test', '124', '1927873', 'Volgaregionen')
INSERT INTO regions VALUES('test', '64', '60975', 'Väst')
INSERT INTO regions VALUES('test', '86', '427304', 'Öst')
INSERT INTO regions VALUES('test', '80', '89569', 'Syd')
INSERT INTO regions VALUES('test', '75', '356560', 'Centrum')
INSERT INTO regions VALUES('test', '77', '34894', 'Norr')
Dumpa resultat till JSON
Allmänt resultatformat:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.totalcount = p1.totalcount;
obj.regions = [];
FOREACH item IN p1.regions;
obj.regions.push({
popularity = item.popularity
region = item.region
count = item.count
});
END;
obj.json %]
Starttext:
[
Sluttext:
]
Exempel på resultat:
[
{
"regions": [
{
"count": "1902795",
"popularity": 88,
"region": "Moskva och Moskva oblast"
},
{
"count": "2992864",
"popularity": 96,
"region": "Centrum"
},
{
"count": "926138",
"popularity": 95,
"region": "Nordväst"
},
{
"count": "647140",
"popularity": 112,
"region": "Söder"
},
{
"count": "34894",
"popularity": 77,
"region": "Norr"
},
],
"totalcount": "10837937"
}
]
Se även: Resultatfilter
Möjliga inställningar
| Parameter | Standardvärde | Beskrivning |
|---|---|---|
| AntiGate preset | default | Du måste först konfigurera scrapern  Util::AntiGate - ange din åtkomstnyckel och andra parametrar, och välj sedan den skapade förinställningen här Util::AntiGate - ange din åtkomstnyckel och andra parametrar, och välj sedan den skapade förinställningen här |
| AntiGate preset for Login | default | AntiGate-förinställning för inloggning. Du måste först konfigurera scrapern Util::AntiGate med parametrar, och välj sedan den skapade förinställningen här |
| Type | All | Val av enhetstyp |
| Accounts | Only from "accounts.txt" | Val av metod för att arbeta med konton: Always auto register - registrera alltid konton automatiskt "i farten", kräver att en konfigurerad förinställning väljs i parametern SE::Yandex::Register preset. Auto register if no more in "accounts.txt" - först används befintliga konton från accounts.txt, och om de tar slut används automatisk registrering "i farten", för vilken en konfigurerad förinställning måste väljas i parametern SE::Yandex::Register preset. Only from "accounts.txt" - använd endast befintliga konton från accounts.txt, och om de tar slut - vänta den angivna tiden (parametern Wait new accounts in "accounts.txt") på att nya ska dyka upp |
| Wait new accounts in "accounts.txt" | 0 | Väntetid för att nya konton ska dyka upp i accounts.txt |
| Remove bad accounts | Always, except wrong login/password | Automatisk borttagning av "dåliga" konton: Always - ta alltid bort. Always, except wrong login/password - ta alltid bort, utom när Yandex meddelat att felaktigt användarnamn/lösenord angivits. Faktum är att Yandex kan ge ett sådant meddelande vid IP-blockering för ett helt fungerande konto, så man kan valfritt behålla sådana konton för återanvändning. Never - ta aldrig bort. Oavsett valt alternativ tas konton inte bort vid proxy-/webbläsarfel |
| SE::Yandex::Register preset | default | Val av inställningsförinställning för SE::Yandex::Register |
| Authorization method | HTTP | Auktoriseringsmetod: HTTP - snabbt, inte resurskrävande. Chrome - långsamt, resurskrävande, kan teoretiskt förlänga kontons livslängd |
| Chrome headless | ☑ | Om alternativet är aktiverat kommer webbläsaren inte att visas |
| Use sessions | ☑ | Användning av sessioner |
| Do not reset session if authorization passed | ☑ | Återställ inte sessionen vid fel om scrapern redan är auktoriserad |
| Use Wordstat 2 | ☐ | Användning av Wordstat 2 |
| Wordstat 2 parse all table data | ☑ | Gör det möjligt att omedelbart ladda ner alla 2000 resultat för en fråga utan att gå igenom paginering |