SE::Yandex::WordStat::ByRegion -
Panoramica dello scraper
Wordstat è un servizio di Yandex progettato per valutare l'interesse degli utenti per vari argomenti e selezionare parole chiave per l'ottimizzazione SEO e la pubblicità contestuale. Inoltre, con Wordstat Yandex è possibile valutare la stagionalità e la dipendenza geografica delle query di ricerca.
Lo scraper Yandex WordStat by region supporta la moltiplicazione automatica delle query, garantendo di ottenere il numero massimo di risultati dai dati forniti. Inoltre, A-Parser può navigare automaticamente attraverso le query correlate fino alla profondità specificata.
La funzionalità di A-Parser consente di salvare le impostazioni di scraping per un uso futuro (preset), impostare pianificazioni di scraping e molto altro. È possibile utilizzare la moltiplicazione automatica delle query, la sostituzione di sotto-query da file, l'iterazione di combinazioni alfanumeriche e liste per ottenere il maggior numero possibile di risultati.
Il salvataggio dei risultati è possibile nel formato e nella struttura necessari, grazie al potente motore di modelli integrato Template Toolkit che consente di applicare logica aggiuntiva ai risultati e di esportare i dati in vari formati, tra cui JSON, SQL e CSV.
Account
Per il funzionamento dello scraper  SE::Yandex::WordStat::ByRegion sono necessari account Yandex. Gli account possono essere registrati utilizzando lo scraper
SE::Yandex::WordStat::ByRegion sono necessari account Yandex. Gli account possono essere registrati utilizzando lo scraper  SE::Yandex::Register o semplicemente aggiungendo gli account esistenti al file
SE::Yandex::Register o semplicemente aggiungendo gli account esistenti al file files/SE-Yandex/accounts.txt nel formato supportato.
In alternativa, è possibile abilitare la registrazione degli account "al volo".
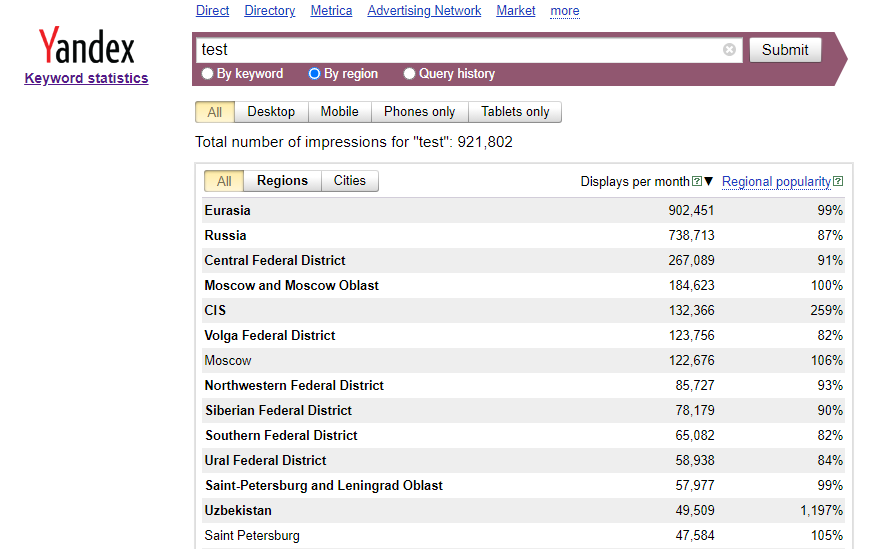
Dati raccolti
- Numero totale di impressioni per query
- Statistiche delle parole chiave per regioni e città:
- Regione/Città
- Numero di visualizzazioni al mese
- Popolarità regionale in %
Funzionalità
- Supporto per il superamento automatico di Smart captcha e possibilità di superare captcha grafici utilizzando il servizio AntiCaptcha o qualsiasi altra API supportata
- Scelta del tipo di dispositivo
- Possibilità di scegliere il metodo di autenticazione
- Possibilità di registrare account "al volo"
- Supporta il lavoro con il formato esteso degli account e sa rispondere alla domanda segreta (se la risposta è presente in
info). Utilizza inoltre il proxy salvato per l'autenticazione (se presente ininfo).
Casi d'uso
- Valutazione del volume di traffico per parola chiave suddiviso per regioni
Query
Come query, è necessario specificare le parole chiave, esattamente come se venissero inserite direttamente nel modulo di ricerca di Wordstat, ad esempio:
test
Esempi di output dei risultati
A-Parser supporta la formattazione flessibile dei risultati grazie al motore di modelli integrato Template Toolkit, che gli consente di produrre risultati in forma libera o strutturata, come CSV o JSON
Output predefinito
Formato del risultato:
$query - Total views: $totalcount\nViews by regions:\n$regions.format('$region $count, $popularity%\n')\nViews by cities:\n$cities.format('$city $count, $popularity%\n')
Il risultato mostra il numero di impressioni per query, le statistiche delle parole chiave per regioni e città, il numero di visualizzazioni al mese e la popolarità regionale:
test - Total views: 872855
Views by regions:
Mosca e regione di Mosca 147107, 85%
Centro 194716, 77%
Nord-Ovest 55815, 70%
Sud 31759, 67%
Volga 86006, 66%
...
Views by cities:
Chita 2937, 113%
San Pietroburgo 35713, 73%
Belgorod 2737, 58%
Ivanovo 1773, 55%
Kaluga 2196, 64%
Kostroma 1166, 49%
Output in tabella CSV
Formato del risultato:
[% FOREACH i IN regions;
tools.CSVline(query, i.popularity, i.region, i.count);
END %]
Esempio di risultato:
"test",88,"Mosca e regione di Mosca",1902795
"test",96,"Centro",2992864
"test",95,"Nord-Ovest",926138
"test",112,Sud,647140
"test",124,"Volga",1927873
"test",64,"Ovest",60975
"test",86,"Est",427304
Salvataggio in formato SQL
Formato del risultato:
[% FOREACH i IN regions;
"INSERT INTO regions VALUES('" _ query _ "', '"; i.popularity _ "', '"; i.count _ "', '"; i.region _ "')\n";
END %]
Esempio di risultato:
INSERT INTO regions VALUES('test', '88', '1902795', 'Mosca e regione di Mosca')
INSERT INTO regions VALUES('test', '96', '2992864', 'Centro')
INSERT INTO regions VALUES('test', '95', '926138', 'Nord-Ovest')
INSERT INTO regions VALUES('test', '112', '647140', 'Sud')
INSERT INTO regions VALUES('test', '124', '1927873', 'Volga')
INSERT INTO regions VALUES('test', '64', '60975', 'Ovest')
INSERT INTO regions VALUES('test', '86', '427304', 'Est')
INSERT INTO regions VALUES('test', '80', '89569', 'Sud')
INSERT INTO regions VALUES('test', '75', '356560', 'Centro')
INSERT INTO regions VALUES('test', '77', '34894', 'Nord')
Dump dei risultati in JSON
Formato comune del risultato:
[% IF notFirst;
",\n";
ELSE;
notFirst = 1;
END;
obj = {};
obj.totalcount = p1.totalcount;
obj.regions = [];
FOREACH item IN p1.regions;
obj.regions.push({
popularity = item.popularity
region = item.region
count = item.count
});
END;
obj.json %]
Testo iniziale:
[
Testo finale:
]
Esempio di risultato:
[
{
"regions": [
{
"count": "1902795",
"popularity": 88,
"region": "Mosca e regione di Mosca"
},
{
"count": "2992864",
"popularity": 96,
"region": "Centro"
},
{
"count": "926138",
"popularity": 95,
"region": "Nord-Ovest"
},
{
"count": "647140",
"popularity": 112,
"region": "Sud"
},
{
"count": "34894",
"popularity": 77,
"region": "Nord"
},
],
"totalcount": "10837937"
}
]
Vedi anche: Filtri dei risultati
Impostazioni possibili
| Parametro | Valore predefinito | Descrizione |
|---|---|---|
| AntiGate preset | default | È necessario configurare preventivamente lo scraper  Util::AntiGate - specificare la propria chiave di accesso e altri parametri, quindi selezionare il preset creato qui Util::AntiGate - specificare la propria chiave di accesso e altri parametri, quindi selezionare il preset creato qui |
| AntiGate preset for Login | default | Preset AntiGate per il login. È necessario configurare preventivamente lo scraper Util::AntiGate con i parametri, quindi selezionare il preset creato qui |
| Type | All | Scelta del tipo di dispositivo |
| Accounts | Only from "accounts.txt" | Scelta del metodo di gestione degli account: Always auto register - registra sempre automaticamente gli account "al volo", richiede la selezione di un preset configurato nel parametro SE::Yandex::Register preset. Auto register if no more in "accounts.txt" - utilizza prima gli account esistenti da accounts.txt e, se terminano, utilizza la registrazione automatica "al volo", per la quale è necessario selezionare un preset configurato nel parametro SE::Yandex::Register preset. Only from "accounts.txt" - utilizza solo gli account esistenti da accounts.txt e, se terminano, attende il tempo specificato (parametro Wait new accounts in "accounts.txt") per la comparsa di nuovi |
| Wait new accounts in "accounts.txt" | 0 | Tempo di attesa per la comparsa di nuovi account in accounts.txt |
| Remove bad accounts | Always, except wrong login/password | Rimozione automatica degli account "cattivi": Always - rimuovi sempre. Always, except wrong login/password - rimuovi sempre, tranne quando Yandex segnala login/password errati. Il fatto è che Yandex può restituire tale messaggio in caso di ban dell'IP per un account perfettamente funzionante, quindi è possibile opzionalmente mantenere tali account per un riutilizzo. Never - non rimuovere mai. Indipendentemente dall'opzione scelta, gli account non vengono rimossi in caso di errori del proxy/browser |
| SE::Yandex::Register preset | default | Scelta del preset di impostazioni per SE::Yandex::Register |
| Authorization method | HTTP | Metodo di autenticazione: HTTP - veloce, poco esigente in termini di risorse. Chrome - lento, esigente in termini di risorse, teoricamente può prolungare la vita degli account |
| Chrome headless | ☑ | Se l'opzione è abilitata, il browser non verrà visualizzato |
| Use sessions | ☑ | Utilizzo delle sessioni |
| Do not reset session if authorization passed | ☑ | Non resettare la sessione in caso di errori se lo scraper è già autenticato |
| Use Wordstat 2 | ☐ | Utilizzo di Wordstat 2 |
| Wordstat 2 parse all table data | ☑ | Consente di scaricare immediatamente tutti i 2000 risultati per query senza passare attraverso la paginazione |