SE::Baidu - Baidu 搜索结果爬虫工具
爬虫工具概览
Baidu 搜索结果爬虫工具。借助 Baidu 爬虫工具,您可以获取海量的链接库,供后续使用。您可以直接在搜索框中使用与 Bing 相同的查询方式,包括搜索运算符(filetype, site, intitle)。
A-Parser 的功能允许您保存 Baidu 爬虫工具的数据抓取设置(预设)以便将来使用,还可以设置数据抓取计划等。您可以使用自动查询扩展、从文件替换子查询、遍历数字字母组合和列表,以获取尽可能多的结果。
在 Baidu 爬虫工具中,由于内置了强大的 Template Toolkit 模板引擎,您可以按所需的格式和结构保存结果,该引擎允许对结果应用额外的逻辑,并以各种格式输出数据,包括 JSON, SQL 和 CSV。
爬虫工具应用案例
🔗 Baidu 全链接数据抓取
此资源展示了如何进行全链接数据抓取
🔗 Baidu 搜索建议
Baidu 搜索建议的多级数据抓取
🔗 JS 爬虫工具 JS::SE::Baidu::Suggest
创建 JS 爬虫工具。获取 Baidu 搜索建议
采集数据
- 链接
- 摘要 (Snippets)
- 锚点
- 结果总数
- 相关搜索词列表
- 搜索结果页数
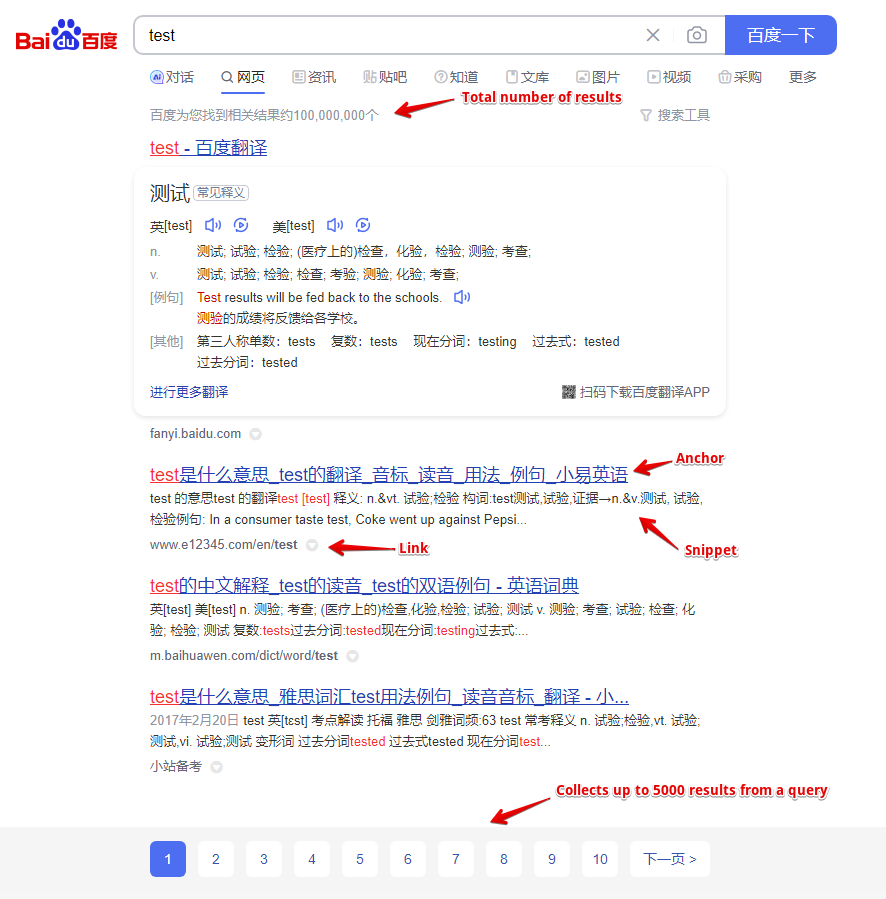
功能
- 每个查询最多抓取 5000 个结果
- 支持所有 Baidu 搜索运算符 (filetype:, site:, intitle:)。
- 采集查询结果及相关关键词
- 将截断的链接转换为完整链接(Get full links 选项)
使用场景
- 采集链接库 - 用于 A-Poster, XRumer, AllSubmitter 等。
- 评估关键词竞争程度
- 检查网站收录情况
- 采集页面标题中包含指定关键词的页面
查询
查询时需要指定搜索短语,例如:
test
site:www.baidu.com
百度产品大全
intitle:爬虫工具
查询占位符
您可以使用 内置宏 来扩展查询,例如我们想要获取一个非常庞大的论坛数据库,可以指定几个不同语言的基础查询:
forum
论坛
foro
论坛
在查询格式中指定从 a 到 zzzz 的字符遍历,这种方法可以最大限度地轮换搜索结果并获得大量新的唯一结果:
$query {az:a:zzzz}
该宏将为每个原始搜索查询创建 475254 个额外查询,总计将产生 4 x 475254 = 1901016 个搜索查询,这个数字令人印象深刻,但对于 A-Parser 来说完全不是问题。在每分钟 2000 个查询的速度下,该任务仅需 16 小时即可处理完毕。
使用运算符
您可以在查询格式中使用搜索运算符,这样它将自动添加到列表中的每个查询:
site:$query
结果输出选项
得益于内置的 Template Toolkit 模板引擎,A-Parser 支持灵活的结果格式化,这使其能够以任意形式以及结构化形式(如 CSV 或 JSON)输出结果。
导出链接列表
链接 + 锚点 + 摘要并输出排名
将链接、锚点和摘要输出到 CSV 表格
保存相关关键词
关键词竞争程度
检查链接收录
以 SQL 格式保存
将结果转储为 JSON
结果处理
A-Parser 允许在数据抓取过程中直接处理结果,本节列出了 Baidu 爬虫工具最常用的案例。
链接去重
按域名进行链接去重
提取域名
去除锚点和摘要中的标签
按包含关系过滤链接
可用设置
| 参数名称 | 默认值 | 描述 |
|---|---|---|
| Pages count | 5 | 抓取的页数(1 到 100) |
| Links per page | 50 | 每页显示的链接数量 (10 / 20 / 50) |
| Get full links | ☐ | 将截断的链接转换为完整链接(默认关闭) |