SE::Google::TrustCheck - サイトのトラストチェック
スクレイパーの概要
このスクレイパーを使用すると、Googleにおけるサイトのトラストを確認できます。 SE::Googleスクレイパーのすべての機能が利用可能です。
A-Parserのマルチスレッド動作により、クエリの処理速度は最大で毎分 900 クエリに達し、平均して毎分最大 6200 件の結果を取得できます。
SE::Googleスクレイパーのすべての機能が利用可能です。
A-Parserのマルチスレッド動作により、クエリの処理速度は最大で毎分 900 クエリに達し、平均して毎分最大 6200 件の結果を取得できます。
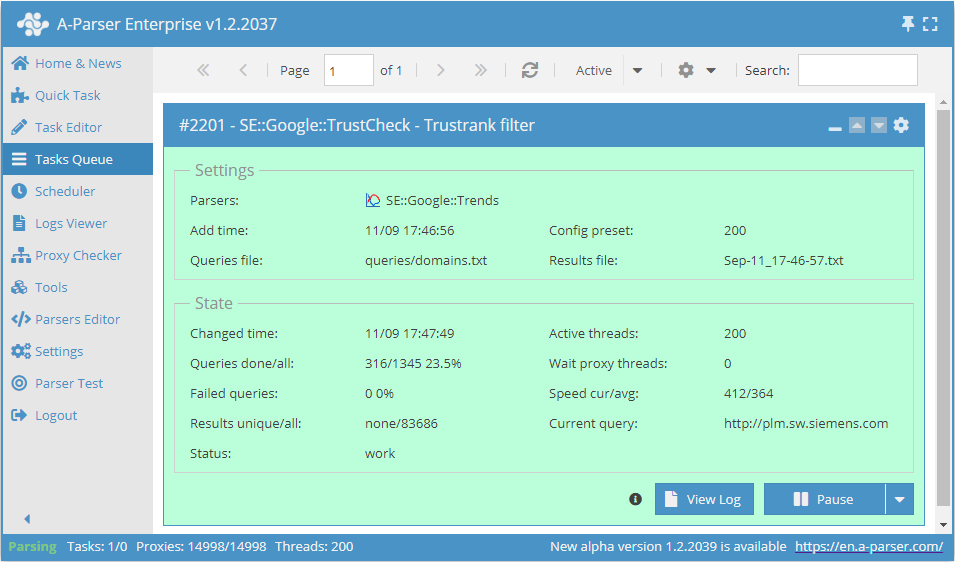
A-Parserの機能により、スクレイピング設定を将来の使用のために保存(プリセット)したり、スクレイピングのスケジュールを設定したりすることが可能です。
組み込みの強力なテンプレートエンジン Template Toolkit により、結果に必要なロジックを適用し、JSON、SQL、CSV を含む様々なフォーマットで、必要な形式と構造で結果を保存できます。
収集データ
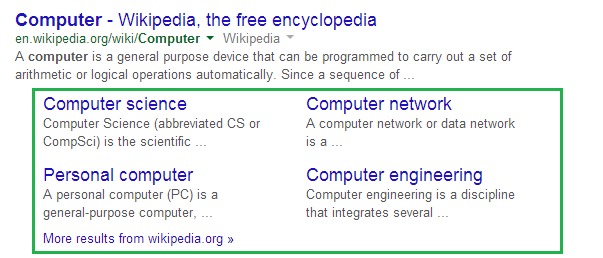
- GoogleによるサイトへのTrust(信頼度)の確認
- 取得可能な結果 -
0、1、2:0- 追加のリンクブロックなし1または2は、Googleが追加のリンクブロックを表示しているため、サイトに信頼があることを意味します。1はサイトに水平方向のリンクブロックがあることを意味し、2は大きな垂直方向のリンクブロックがあることを意味します。

機能
- トラストサイトのデータベース収集
- 検索対象国、ドメイン、結果の言語、その他の設定の選択をサポート
クエリ
クエリとして、検索したいサイトのURLを指定する必要があります。例:
http://uraldekor.ru/
http://a-parser.com/
http://www.yandex.ru/
http://google.com/
http://vk.com/
http://facebook.com/
http://youtube.com/
クエリの置換
組み込みマクロを使用して、ファイルからサブクエリを自動的に挿入できます。例えば、キーワードベースでサイトを確認したい場合、いくつかのメインクエリを指定します:
ria.ru
lenta.ru
rbc.ru
yandex.ru
クエリ形式にファイル Keywords.txt から追加の単語を挿入するマクロを指定します。この方法により、キーワードベースでサイトベースを確認し、結果としてポジションを取得できます:
$query {subs:Keywords}
このマクロは、各元の検索クエリに対してファイル内の単語数と同じ数の追加クエリを作成します。その結果、マクロの動作により [元のクエリ数(ドメイン)] x [Keywordsファイル内のクエリ数] = [総クエリ数] となります。
また、クエリ形式にプロトコルを指定して、ドメインのみをクエリとして使用できるようにすることも可能です:
http://$query
この形式は、各クエリの前に http:// を付加します。
結果の出力例
A-Parserは、組み込みのテンプレートエンジン Template Toolkit により柔軟な結果フォーマットをサポートしており、任意の形式やCSV、JSONなどの構造化された形式で結果を出力できます。
トラスト確認リストのエクスポート
結果フォーマット:
$query: $trustrank\n
結果には、リンクのリストとそのTrust確認結果が表示されます。
結果の例:
http://www.yandex.ru/: 2
http://a-parser.com/: 1
http://vk.com/: 2
http://uraldekor.ru/: 0
http://google.com/: 2
...
リンク + アンカー + スニペットとポジションの出力
リンク、アンカー、スニペットのCSVテーブルへの出力
関連キーワードの保存
キーワードの競合調査
リンクのインデックス登録確認
SQL形式での保存
結果のJSONへのダンプ
結果の処理
A-Parserではスクレイピング中に直接結果を処理できます。このセクションでは、SE::Google::TrustCheckスクレイパーの最も一般的なケースを紹介します。
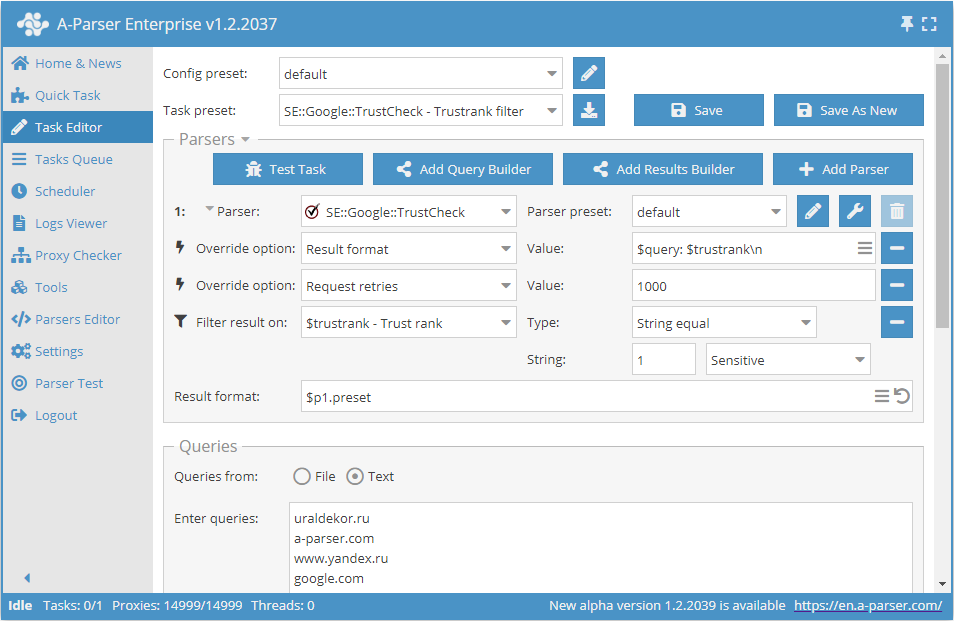
トラスト値が「1」のドメインの保存
フィルタを追加し、ドロップダウンリストからトラスト変数 $trustrank - Trust rank を選択します。タイプとして String equal を選択します。次に、String (文字列) に必要なトラスト値 1 を入力します。このフィルタにより、不要なトラスト値を持つすべての結果を除外できます。
サンプルをダウンロード
eJx1VEtz2jAQ/iuMJod2hjhw6MU3woROOzSkCTkBB4HXRLWsNXrwGA//vSvZ2CYt
J3tf37f7raSSWW4y86LBgDUsXpSsCP8sZm9PcfwdcSshjufaGTv+gE3Wu+8FQ3OV
9VIhLWjWZwXXBrQHWNyoo6QEUu6kZf2S2VMBRIF70FokQEGRkJ2izrmlBkIa23Pp
fNrdzoE+xb07e2FeLhU738YpNB5PGqwWYDo4w8Fg0C1r2q8ZY9YQkLOKzqtU2Dku
u1D0j4UVqMgwoAw7r1YXIDMJc/jOi2FUC9oE3/ge5ljRQ+uekPXM8zBvwi34aFQJ
8uVrZI8egSeJ8JxcVgxe8Jb1XYldaE4h5XrNaPyJxtwPBgEgCHnpbsE+rC3ih4dK
X0ZILkD8rkpZnHJpoM8MdTzh1E/yOSJIIW5Rz4IU5C8ZqpGUU9iDbNMC/qMTMqFD
Mkqp6Edd+P+U2T8Y52bKLhWt/aCphwYlWI+zX21VglPckgDJmsaXIheWbDNGp/x+
BuTMAIpGumcvXY4aGpoauWanm1KA8mes3dyoaF1XY1xt59q5QZWK7aw+t5dMp+Z0
HWdqjHkhwc+lnJS0FgOv7SkZmXoN3mgb/Fw8DhR+9Mu9YxZRmp9vVauFFnQKv/kG
c1Kyy1pDbriU76/TboS1J4sMpznNlKGOtFsqfl89A9EG86U6HA7RiasEjiG4DS9C
Fdpn1TflG1gj1tYJnXXrkMI8t4Ut0qkkZc6r5oVpXqry1jsTl2da+x/zUhV4jXw6
+UhsEy7s8PwXfU7A2Q==
参照:結果フィルタ
リンクの重複排除
ドメインによるリンクの重複排除
ドメインの抽出
アンカーとスニペットからのタグ削除
含有によるリンクのフィルタリング
設定可能な項目
SE::Googleスクレイパーのすべての設定に加えて、以下の追加設定をサポートしています:| パラメータ名 | デフォルト値 | 説明 |
|---|---|---|
| Pages count | 1 | 検索結果のスクレイピングページ数 (1から10まで) |