SE::Google::TrustCheck - Vérification du trust d'un site
Présentation du scraper
Le scraper permet de vérifier le trust d'un site dans Google. Toutes les fonctionnalités du scraper  SE::Google sont disponibles.
Grâce au traitement multithread de A-Parser, la vitesse de traitement des requêtes peut atteindre 900 requêtes par minute, ce qui permet en moyenne d'obtenir jusqu'à 6200 résultats par minute.
SE::Google sont disponibles.
Grâce au traitement multithread de A-Parser, la vitesse de traitement des requêtes peut atteindre 900 requêtes par minute, ce qui permet en moyenne d'obtenir jusqu'à 6200 résultats par minute.
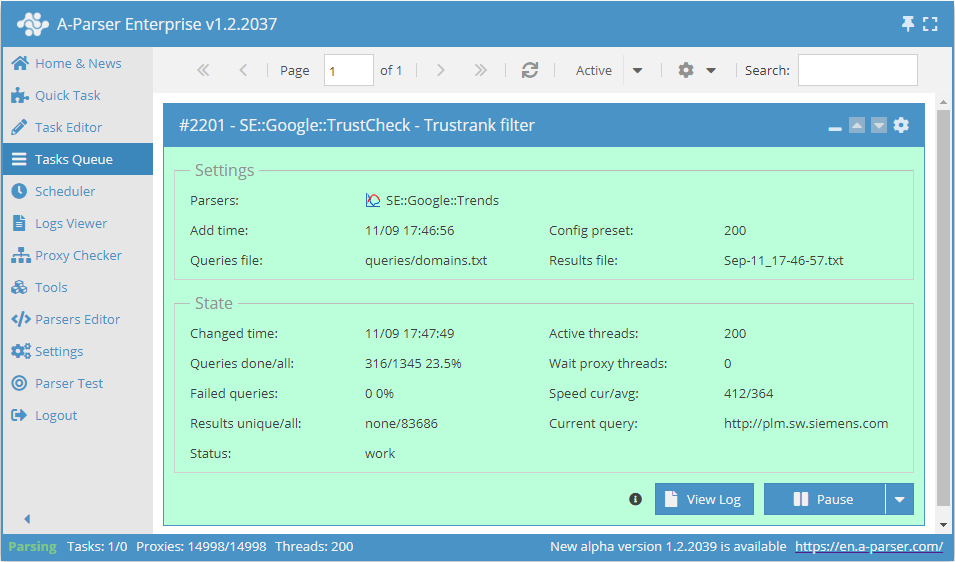
Les fonctionnalités d'A-Parser permettent de sauvegarder les paramètres de collecte de données pour une utilisation ultérieure (présélections), de définir des calendriers de collecte et bien plus encore.
La sauvegarde des résultats est possible dans le format et la structure dont vous avez besoin, grâce au puissant moteur de gabarit intégré Template Toolkit qui permet d'appliquer une logique supplémentaire aux résultats et d'exporter les données dans divers formats, y compris JSON, SQL et CSV.
Données collectées
- Vérification du Trust (confiance) de Google envers le site
- Résultats possibles -
0,1et2:0- pas de blocs de liens supplémentaires1ou2signifie que Google a confiance dans le site, car il affiche des blocs de liens supplémentaires.1- signifie que le site a un bloc de liens horizontal, et2- signifie qu'il a un grand bloc de liens vertical

Fonctionnalités
- Collecte d'une base de sites de confiance
- Prend en charge le choix du pays de recherche, du domaine, de la langue des résultats et d'autres paramètres
Requêtes
En tant que requêtes, il est nécessaire d'indiquer l'URL du site recherché, par exemple :
http://uraldekor.ru/
http://a-parser.com/
http://www.yandex.ru/
http://google.com/
http://vk.com/
http://facebook.com/
http://youtube.com/
Substitutions de requêtes
Vous pouvez utiliser les macros intégrées pour la substitution automatique de sous-requêtes à partir de fichiers, par exemple si nous voulons vérifier des sites par rapport à une base de mots-clés, indiquons quelques requêtes de base :
ria.ru
lenta.ru
rbc.ru
yandex.ru
Dans le format de requête, indiquons la macro de substitution de mots supplémentaires provenant du fichier Keywords.txt, cette méthode permet de vérifier une base de sites par rapport à une base de mots-clés et d'obtenir les positions en résultat :
$query {subs:Keywords}
Cette macro créera autant de requêtes supplémentaires qu'il y en a dans le fichier pour chaque requête de recherche initiale, ce qui donnera au total [nombre de requêtes initiales (domaines)] x [nombre de requêtes dans le fichier Keywords] = [nombre total de requêtes] suite au travail de la macro.
Il est également possible d'indiquer le protocole dans le format de requête pour pouvoir utiliser uniquement des domaines comme requêtes :
http://$query
Ce format ajoutera http:// à chaque requête.
Variantes d'affichage des résultats
A-Parser prend en charge un formatage flexible des résultats grâce au moteur de gabarit intégré Template Toolkit, ce qui lui permet d'afficher les résultats sous une forme libre, ainsi que structurée, par exemple CSV ou JSON
Exportation de la liste de vérification du trust
Format du résultat :
$query: $trustrank\n
Le résultat affiche la liste des liens et leur vérification de Trust.
Exemple de résultat :
http://www.yandex.ru/: 2
http://a-parser.com/: 1
http://vk.com/: 2
http://uraldekor.ru/: 0
http://google.com/: 2
...
Liens + ancres + extraits avec affichage de la position
Affichage des liens, ancres et extraits dans un tableau CSV
Sauvegarde des mots-clés associés
Concurrence des mots-clés
Vérification de l'indexation des liens
Sauvegarde au format SQL
Dump des résultats en JSON
Traitement des résultats
A-Parser permet de traiter les résultats directement pendant la collecte de données, dans cette section nous avons listé les cas les plus populaires pour le scraper SE::Google::TrustCheck
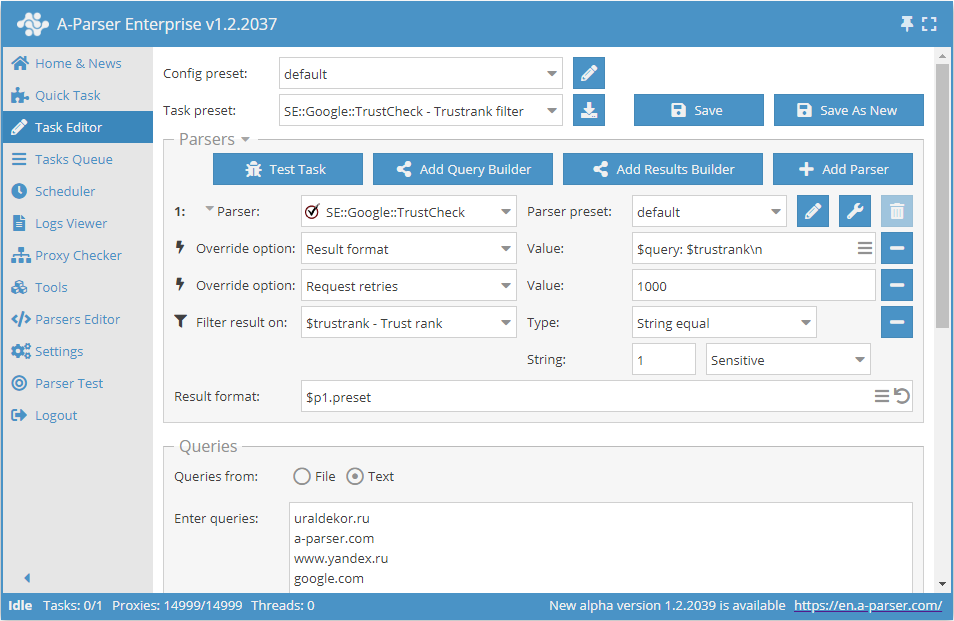
Sauvegarde des domaines avec une valeur de trust "1"
Ajouter un filtre et dans la liste déroulante choisir la variable de trust $trustrank - Trust rank. Choisir le type : String equal. Ensuite, il faut inscrire dans String (Chaîne) la valeur de trust souhaitée 1. Avec ce filtre, vous pourrez supprimer tous les résultats n'ayant pas le trust requis.
Télécharger l'exemple
Comment importer l'exemple dans A-Parser
eJx1VEtz2jAQ/iuMJod2hjhw6MU3woROOzSkCTkBB4HXRLWsNXrwGA//vSvZ2CYt
J3tf37f7raSSWW4y86LBgDUsXpSsCP8sZm9PcfwdcSshjufaGTv+gE3Wu+8FQ3OV
9VIhLWjWZwXXBrQHWNyoo6QEUu6kZf2S2VMBRIF70FokQEGRkJ2izrmlBkIa23Pp
fNrdzoE+xb07e2FeLhU738YpNB5PGqwWYDo4w8Fg0C1r2q8ZY9YQkLOKzqtU2Dku
u1D0j4UVqMgwoAw7r1YXIDMJc/jOi2FUC9oE3/ge5ljRQ+uekPXM8zBvwi34aFQJ
8uVrZI8egSeJ8JxcVgxe8Jb1XYldaE4h5XrNaPyJxtwPBgEgCHnpbsE+rC3ih4dK
X0ZILkD8rkpZnHJpoM8MdTzh1E/yOSJIIW5Rz4IU5C8ZqpGUU9iDbNMC/qMTMqFD
Mkqp6Edd+P+U2T8Y52bKLhWt/aCphwYlWI+zX21VglPckgDJmsaXIheWbDNGp/x+
BuTMAIpGumcvXY4aGpoauWanm1KA8mes3dyoaF1XY1xt59q5QZWK7aw+t5dMp+Z0
HWdqjHkhwc+lnJS0FgOv7SkZmXoN3mgb/Fw8DhR+9Mu9YxZRmp9vVauFFnQKv/kG
c1Kyy1pDbriU76/TboS1J4sMpznNlKGOtFsqfl89A9EG86U6HA7RiasEjiG4DS9C
Fdpn1TflG1gj1tYJnXXrkMI8t4Ut0qkkZc6r5oVpXqry1jsTl2da+x/zUhV4jXw6
+UhsEy7s8PwXfU7A2Q==
Voir aussi : Filtres de résultats
Déduplication des liens
Déduplication des liens par domaine
Extraction de domaines
Suppression des balises des ancres et extraits
Filtrage des liens par inclusion
Paramètres possibles
Prend en charge tous les paramètres du scraper SE::Google, ainsi que les éléments suivants :
| Nom du paramètre | Valeur par défaut | Description |
|---|---|---|
| Pages count | 1 | Nombre de pages de collecte des résultats (de 1 à 10) |